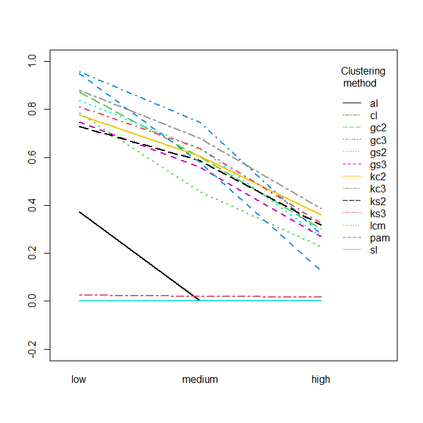
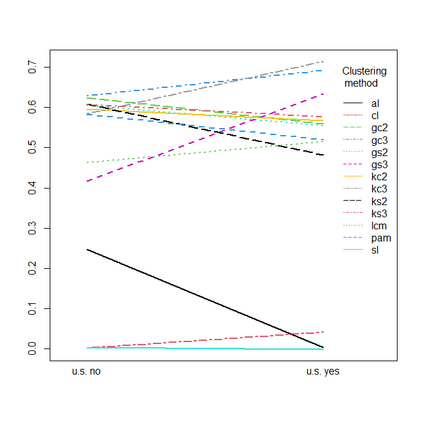
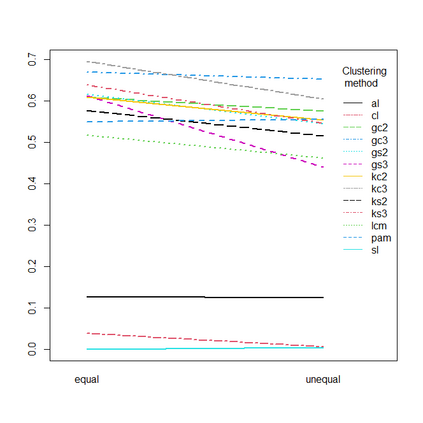
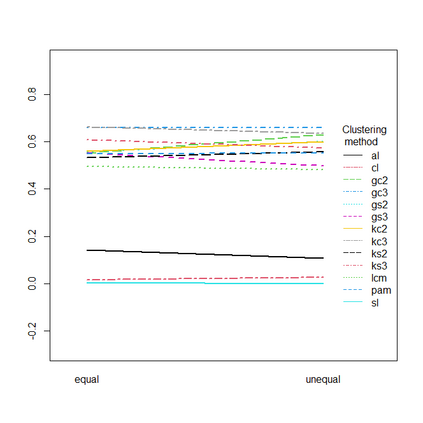
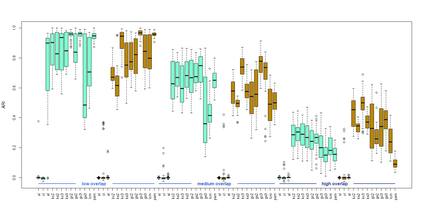
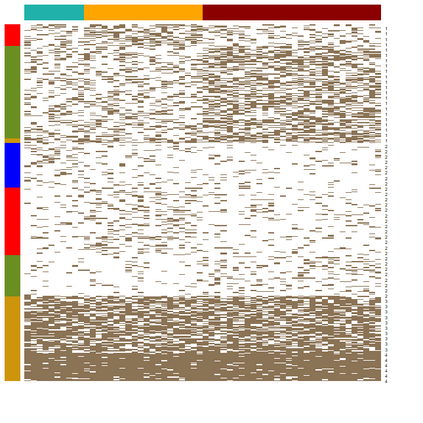
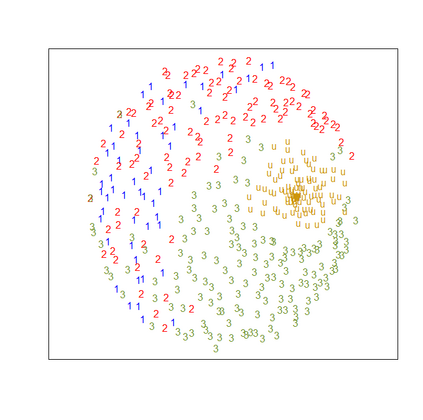
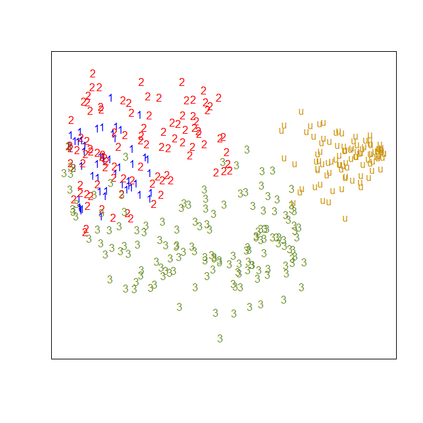
Presence-absence data is defined by vectors or matrices of zeroes and ones, where the ones usually indicate a "presence" in a certain place. Presence-absence data occur for example when investigating geographical species distributions, genetic information, or the occurrence of certain terms in texts. There are many applications for clustering such data; one example is to find so-called biotic elements, i.e., groups of species that tend to occur together geographically. Presence-absence data can be clustered in various ways, namely using a latent class mixture approach with local independence, distance-based hierarchical clustering with the Jaccard distance, or also using clustering methods for continuous data on a multidimensional scaling representation of the distances. These methods are conceptually very different and can therefore not easily be compared theoretically. We compare their performance with a comprehensive simulation study based on models for species distributions.
翻译:例如,在调查地理物种分布、遗传信息或文本中出现某些术语时,会出现缺席数据。 有许多将这些数据分组的应用;一个例子是找到所谓的生物元素,即往往在地理上共同出现的物种群。 不存在数据可以以不同方式分组,即使用具有当地独立性的潜在级混合方法、基于距离的远距离等级组合,或者使用组合方法,连续提供多维比例代表距离的连续数据。这些方法在概念上非常不同,因此不易在理论上加以比较。我们将它们的性能与基于物种分布模型的综合模拟研究进行比较。