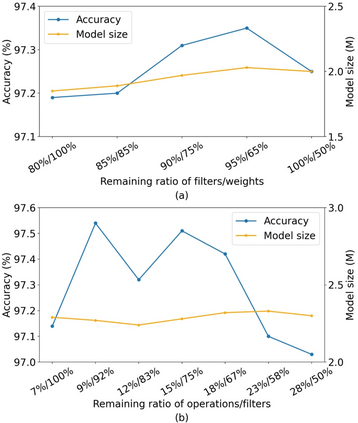
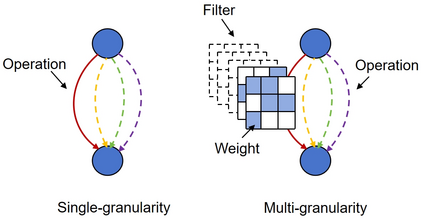
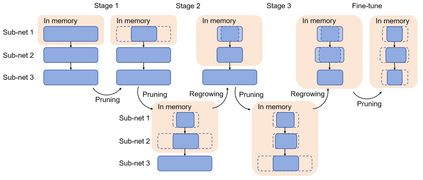
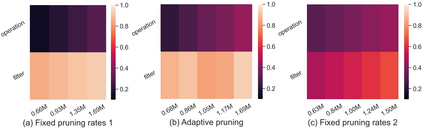
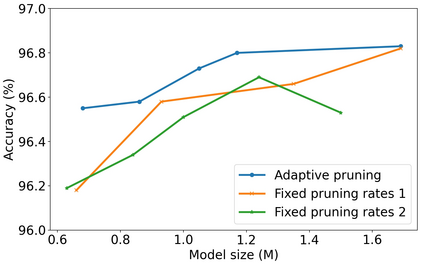
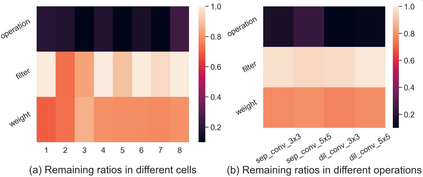
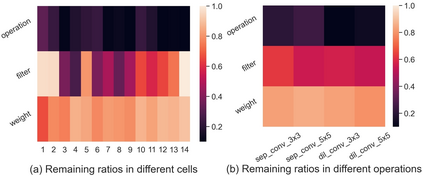
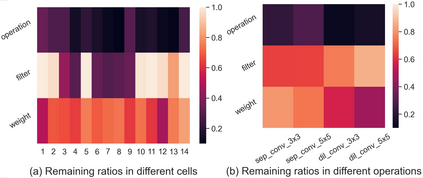
Differentiable architecture search (DAS) has become the prominent approach in the field of neural architecture search (NAS) due to its time-efficient automation of neural network design. It shifts the traditional paradigm of discrete architecture sampling and evaluation to differentiable super-net optimization and discretization. However, existing DAS methods either only conduct coarse-grained operation-level search, or restrictively explore fine-grained filter-level and weight-level units using manually-defined remaining ratios, which fail to simultaneously achieve small model size and satisfactory model performance. Additionally, they address the high memory consumption of the search process at the expense of search quality. To tackle these issues, we introduce multi-granularity architecture search (MGAS), a unified framework which aims to comprehensively and memory-efficiently explore the multi-granularity search space to discover both effective and efficient neural networks. Specifically, we learn discretization functions specific to each granularity level to adaptively determine the remaining ratios according to the evolving architecture. This ensures an optimal balance among units of different granularity levels for different target model sizes. Considering the memory demands, we break down the super-net optimization and discretization into multiple sub-net stages. By allowing re-pruning and regrowing of units in previous sub-nets during subsequent stages, we compensate for potential bias in earlier stages. Extensive experiments on CIFAR-10, CIFAR-100 and ImageNet demonstrate that MGAS outperforms other state-of-the-art methods in achieving a better trade-off between model performance and model size.
翻译:暂无翻译