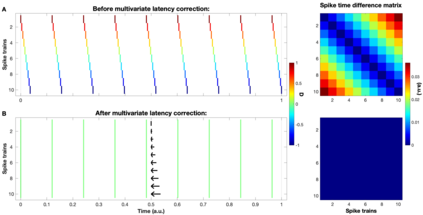
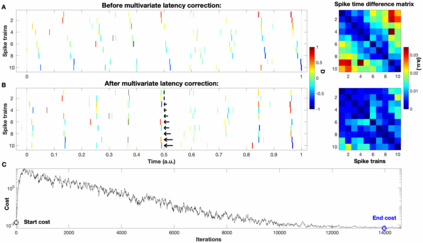
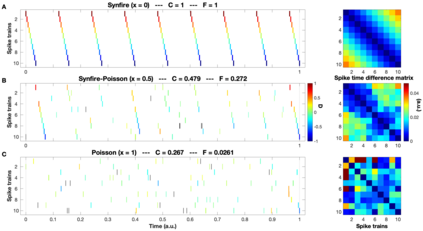
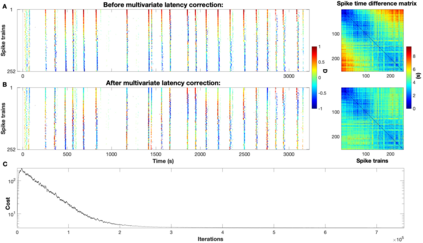
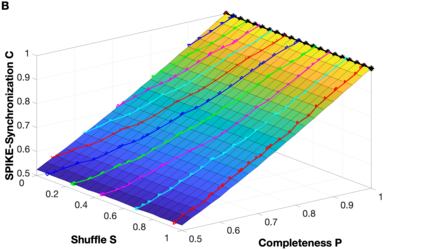
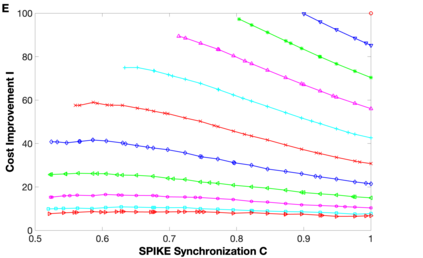
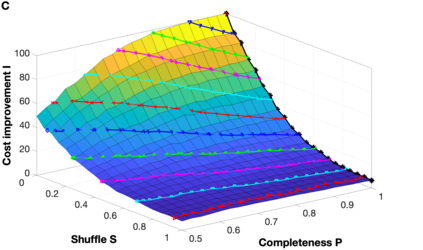
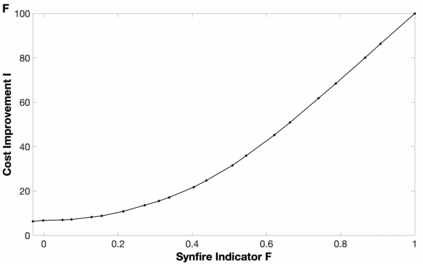
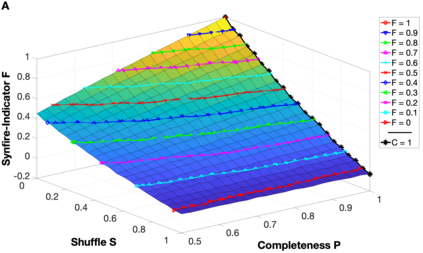
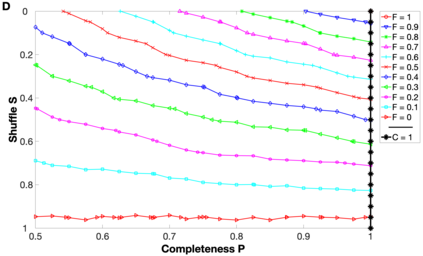
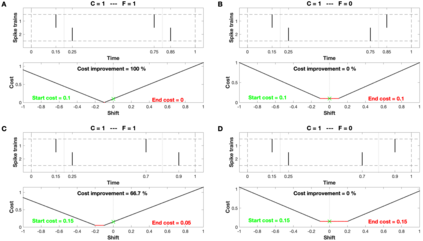
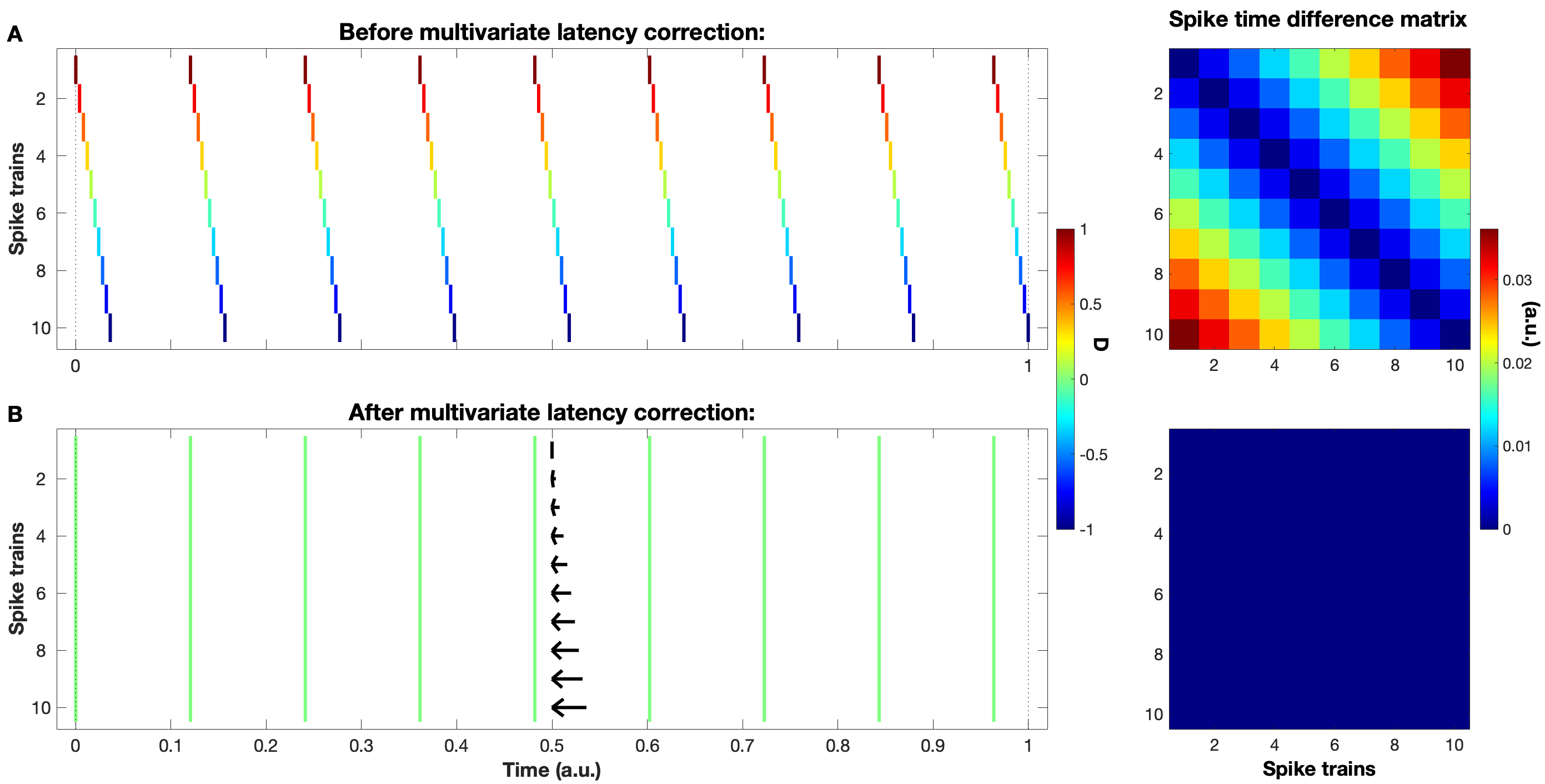
Background: In neurophysiological data, latency refers to a global shift of spikes from one spike train to the next, either caused by response onset fluctuations or by finite propagation speed. Such systematic shifts in spike timing lead to a spurious decrease in synchrony which needs to be corrected. New Method: We propose a new algorithm of multivariate latency correction suitable for sparse data for which the relevant information is not primarily in the rate but in the timing of each individual spike. The algorithm is designed to correct systematic delays while maintaining all other kinds of noisy disturbances. It consists of two steps, spike matching and distance minimization between the matched spikes using simulated annealing. Results: We show its effectiveness on simulated and real data: cortical propagation patterns recorded via calcium imaging from mice before and after stroke. Using simulations of these data we also establish criteria that can be evaluated beforehand in order to anticipate whether our algorithm is likely to yield a considerable improvement for a given dataset. Comparison with Existing Method(s): Existing methods of latency correction rely on adjusting peaks in rate profiles, an approach that is not feasible for spike trains with low firing in which the timing of individual spikes contains essential information. Conclusions: For any given dataset the criterion for applicability of the algorithm can be evaluated quickly and in case of a positive outcome the latency correction can be applied easily since the source codes of the algorithm are publicly available.
翻译:在神经生理学数据中,延时是指从一个峰值列向下一个峰值的全球性峰值变化,要么是由于反应起伏波动或有限的传播速度造成的。在峰值时间上的这种系统变化导致假的同步下降,需要加以纠正。新方法:我们建议了一种适合稀有数据的多变延时校正新算法,这些数据的相关信息主要不是在速度上,而是在每次峰值的时间安排上。算法旨在纠正系统性的延误,同时维持所有其他类型的噪音。它包括两个步骤,即用模拟Annealing来调整匹配的峰值之间的匹配和距离最小化。结果:我们在模拟和真实数据上显示了其有效性:通过小鼠在中风前后的钙成像记录到的螺旋传播模式。我们还利用这些数据的模拟,我们还制定了可以预先评估的标准,以便预测我们的算法是否能够为给定数据集带来相当大的改进。与现有方法的比较:现有的Latency校正校正的校准方法取决于调整费率的峰值,一种方法对于使用在模拟和真实性列列列列的校准性火车上,这是不可行的方法。