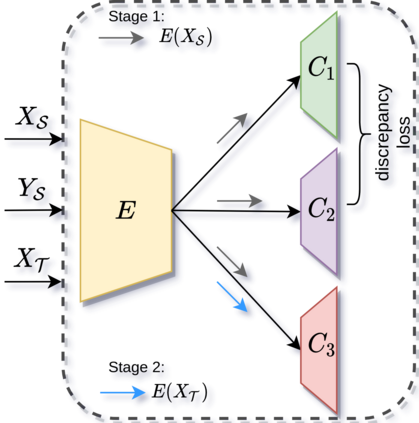
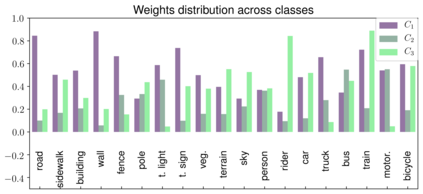
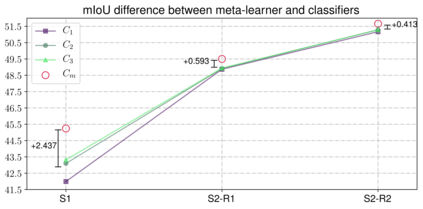
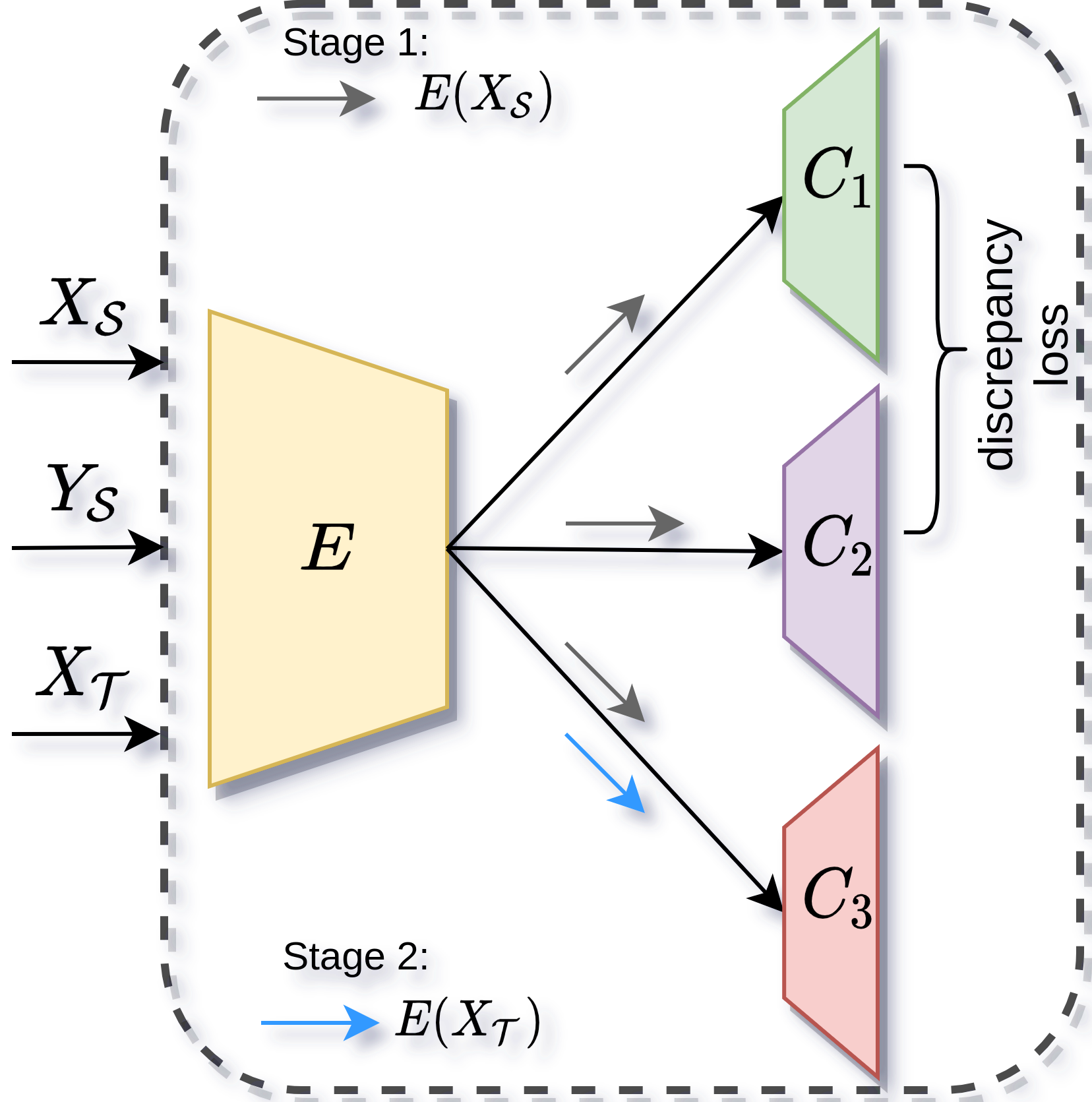
We introduce an unsupervised domain adaption (UDA) strategy that combines multiple image translations, ensemble learning and self-supervised learning in one coherent approach. We focus on one of the standard tasks of UDA in which a semantic segmentation model is trained on labeled synthetic data together with unlabeled real-world data, aiming to perform well on the latter. To exploit the advantage of using multiple image translations, we propose an ensemble learning approach, where three classifiers calculate their prediction by taking as input features of different image translations, making each classifier learn independently, with the purpose of combining their outputs by sparse Multinomial Logistic Regression. This regression layer known as meta-learner helps to reduce the bias during pseudo label generation when performing self-supervised learning and improves the generalizability of the model by taking into consideration the contribution of each classifier. We evaluate our method on the standard UDA benchmarks, i.e. adapting GTA V and Synthia to Cityscapes, and achieve state-of-the-art results in the mean intersection over union metric. Extensive ablation experiments are reported to highlight the advantageous properties of our proposed UDA strategy.
翻译:我们引入了一种不受监督的域适应(UDA)战略,将多种图像翻译、混合学习和自我监督学习结合起来,采取一致的方法,我们注重UDA的标准任务之一,即对标签合成数据和未标签真实世界数据进行语义分解模式的培训,目的是很好地利用后者。为了利用多图像翻译的优势,我们建议了一种混合学习方法,即三个分类者以不同图像翻译的输入特征来计算其预测,使每个分类者独立学习,目的是通过稀疏的多角度物流回归将其产出结合起来。这个被称为元 Leaner的回归层在进行自我监督学习时有助于减少假标签生成过程中的偏差,并通过考虑到每个分类者的贡献来提高模型的通用性。我们评估了我们关于标准的UDA基准的方法,即将GTA V和Synthia 调整为城市景象,并实现了在UBIML Regresulation上的平均交叉性结果。我们报告的UDA范围战略的大规模扩展性实验被突出。