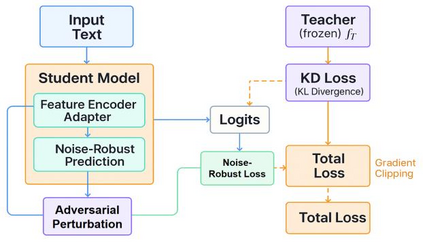
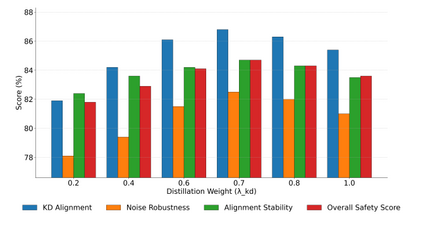
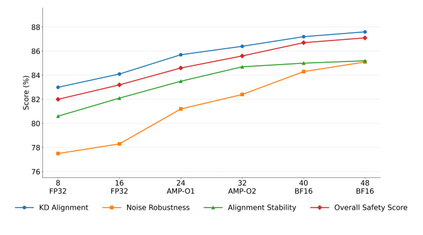
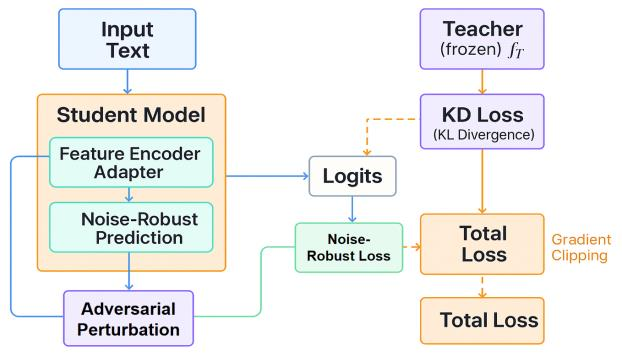
This paper addresses the limitations of large-scale language models in safety alignment and robustness by proposing a fine-tuning method that combines contrastive distillation with noise-robust training. The method freezes the backbone model and transfers the knowledge boundaries of the teacher model to the student model through distillation, thereby improving semantic consistency and alignment accuracy. At the same time, noise perturbations and robust optimization constraints are introduced during training to ensure that the model maintains stable predictive outputs under noisy and uncertain inputs. The overall framework consists of distillation loss, robustness loss, and a regularization term, forming a unified optimization objective that balances alignment ability with resistance to interference. To systematically validate its effectiveness, the study designs experiments from multiple perspectives, including distillation weight sensitivity, stability analysis under computation budgets and mixed-precision environments, and the impact of data noise and distribution shifts on model performance. Results show that the method significantly outperforms existing baselines in knowledge transfer, robustness, and overall safety, achieving the best performance across several key metrics. This work not only enriches the theoretical system of parameter-efficient fine-tuning but also provides a new solution for building safer and more trustworthy alignment mechanisms.
翻译:暂无翻译