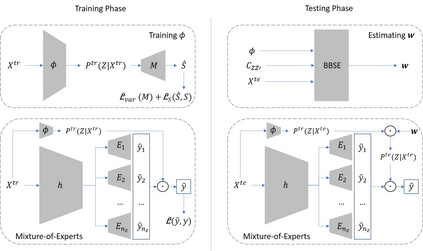
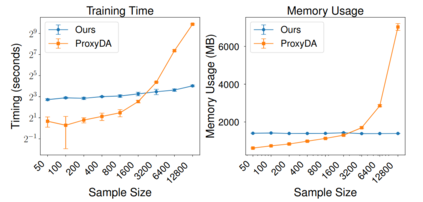
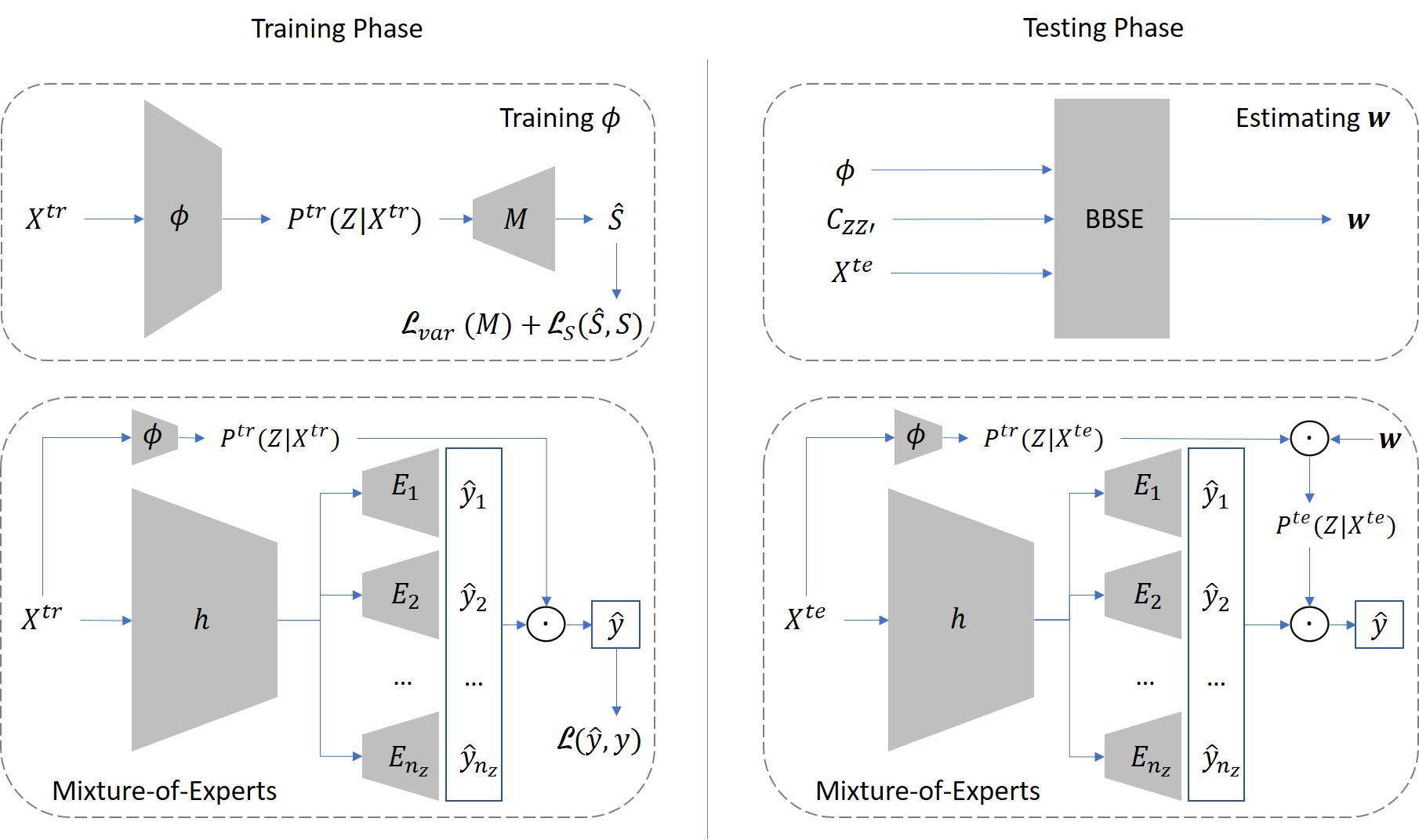
We consider the task of out-of-distribution (OOD) generalization, where the distribution shift is due to an unobserved confounder ($Z$) affecting both the covariates ($X$) and the labels ($Y$). In this setting, traditional assumptions of covariate and label shift are unsuitable due to the confounding, which introduces heterogeneity in the predictor, i.e., $\hat{Y} = f_Z(X)$. OOD generalization differs from traditional domain adaptation by not assuming access to the covariate distribution ($X^\text{te}$) of the test samples during training. These conditions create a challenging scenario for OOD robustness: (a) $Z^\text{tr}$ is an unobserved confounder during training, (b) $P^\text{te}{Z} \neq P^\text{tr}{Z}$, (c) $X^\text{te}$ is unavailable during training, and (d) the posterior predictive distribution depends on $P^\text{te}(Z)$, i.e., $\hat{Y} = E_{P^\text{te}(Z)}[f_Z(X)]$. In general, accurate predictions are unattainable in this scenario, and existing literature has proposed complex predictors based on identifiability assumptions that require multiple additional variables. Our work investigates a set of identifiability assumptions that tremendously simplify the predictor, whose resulting elegant simplicity outperforms existing approaches.
翻译:暂无翻译