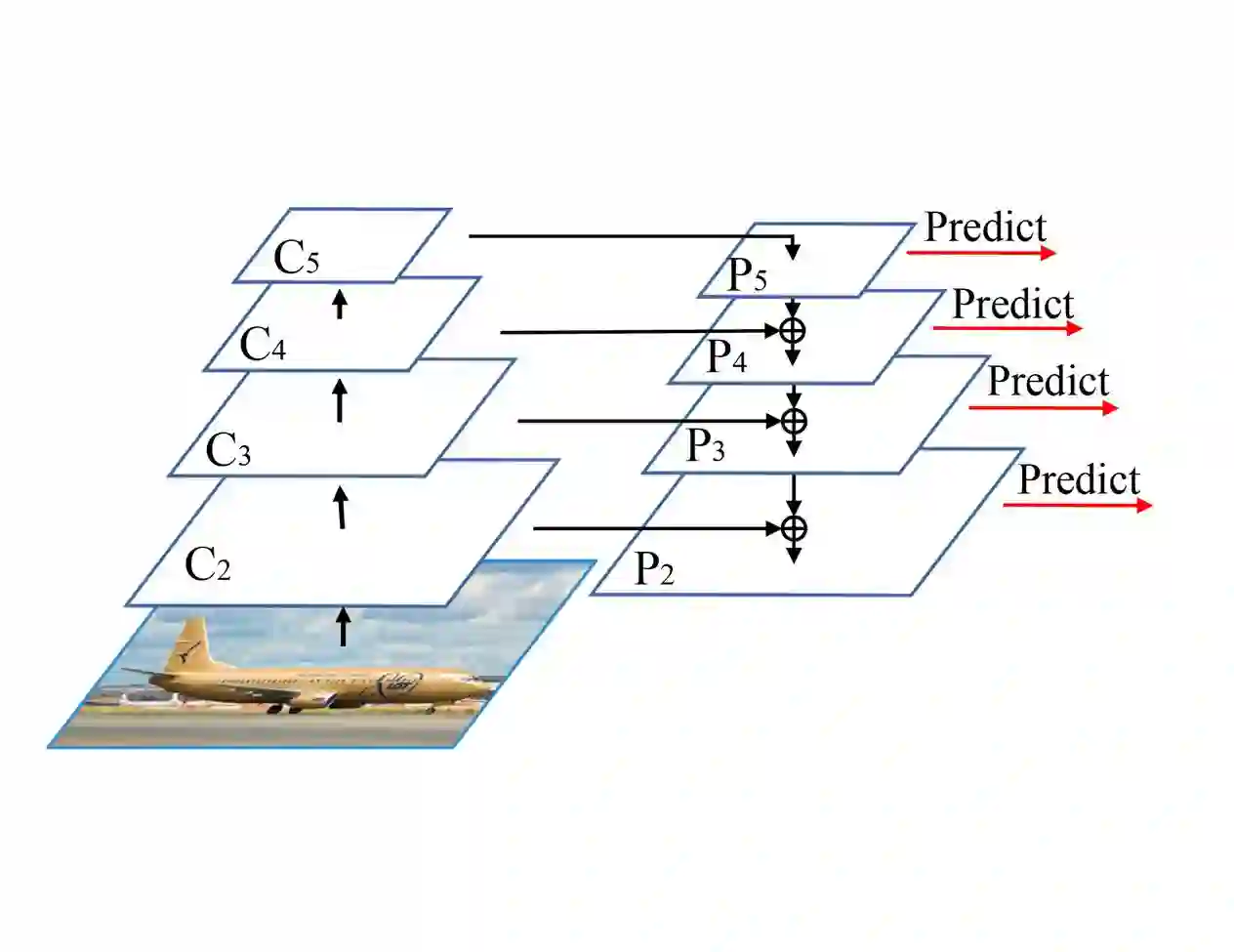
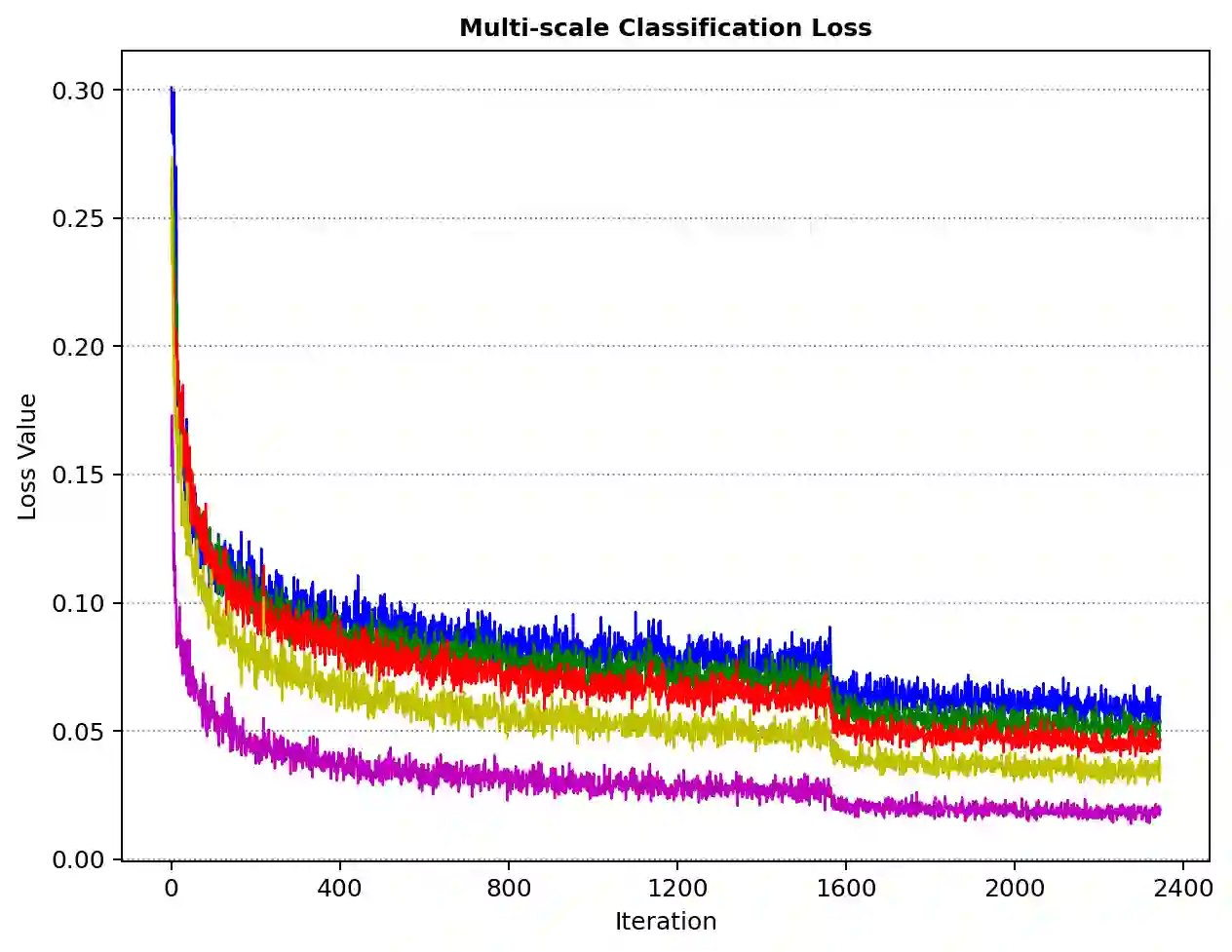
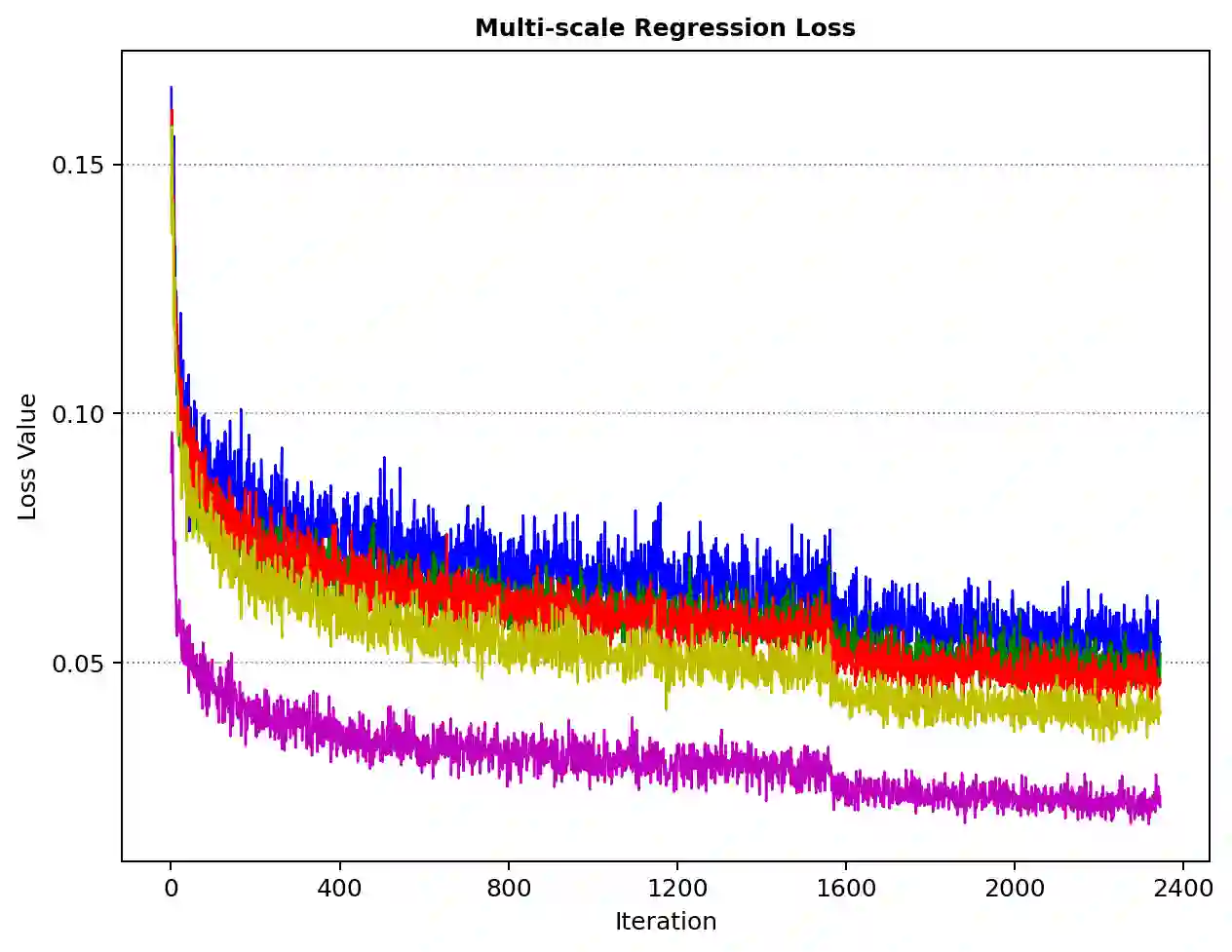
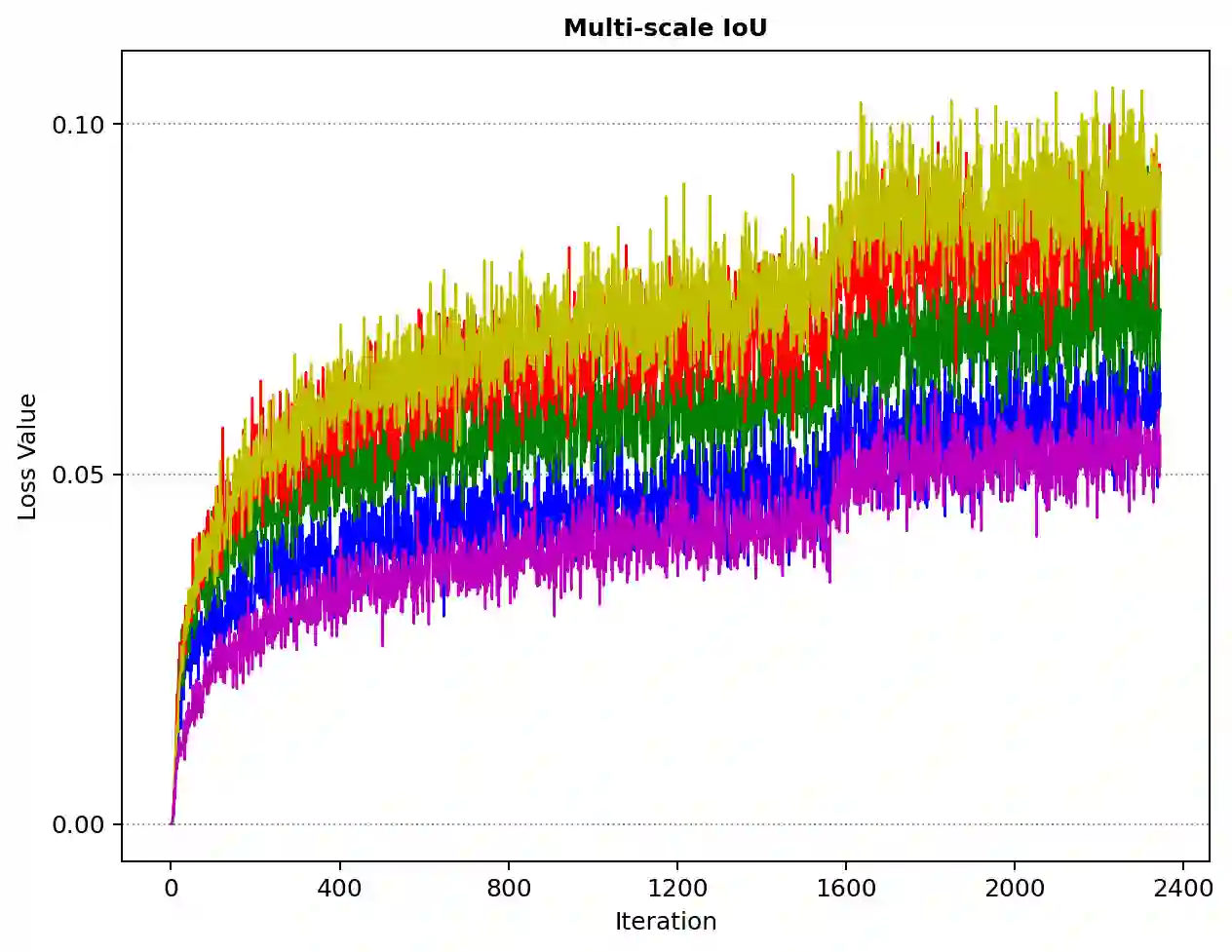
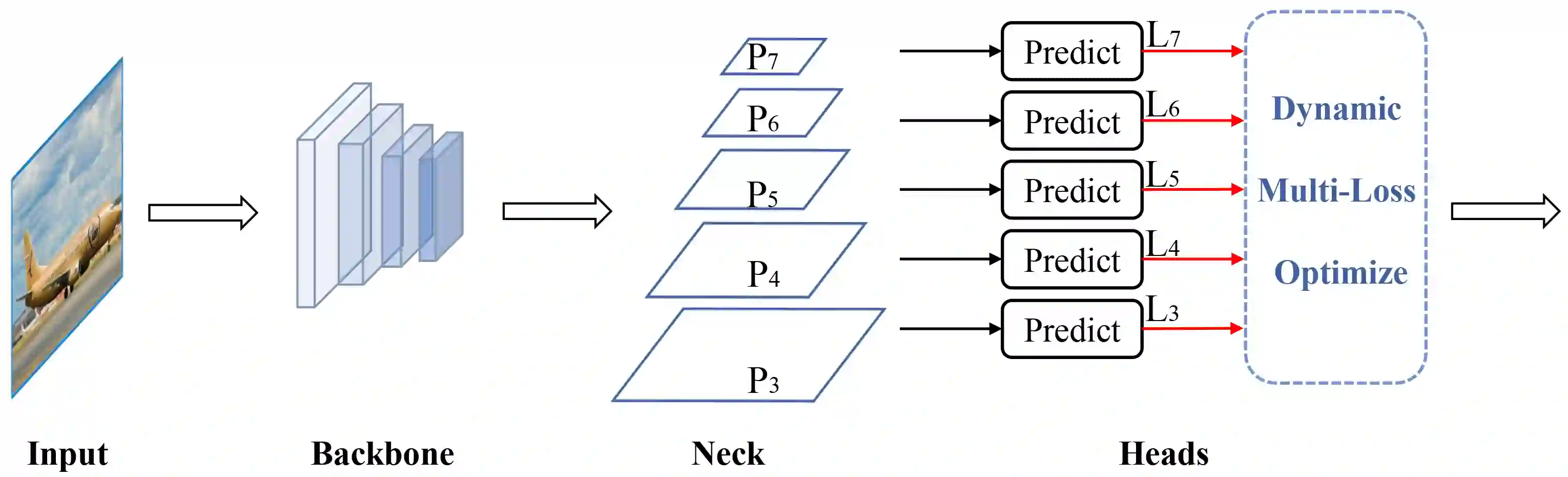
With the continuous improvement of the performance of object detectors via advanced model architectures, imbalance problems in the training process have received more attention. It is a common paradigm in object detection frameworks to perform multi-scale detection. However, each scale is treated equally during training. In this paper, we carefully study the objective imbalance of multi-scale detector training. We argue that the loss in each scale level is neither equally important nor independent. Different from the existing solutions of setting multi-task weights, we dynamically optimize the loss weight of each scale level in the training process. Specifically, we propose an Adaptive Variance Weighting (AVW) to balance multi-scale loss according to the statistical variance. Then we develop a novel Reinforcement Learning Optimization (RLO) to decide the weighting scheme probabilistically during training. The proposed dynamic methods make better utilization of multi-scale training loss without extra computational complexity and learnable parameters for backpropagation. Experiments show that our approaches can consistently boost the performance over various baseline detectors on Pascal VOC and MS COCO benchmark.
翻译:由于通过先进的模型结构不断改进物体探测器的性能,培训过程中的不平衡问题得到更多的注意,这是进行多尺度探测的物体探测框架的一个常见范例,但每个尺度在培训期间都得到同等对待。在本文件中,我们仔细研究多尺度探测器培训的客观不平衡问题。我们认为,每个尺度层次的损失既不同等重要,也不独立。与确定多任务重量的现有解决办法不同,我们积极优化培训过程中每个尺度层次的损失重量。具体地说,我们提议采用适应差异加权法(AVW),以根据统计差异平衡多尺度的损失。然后,我们开发一个新的强化学习优化法(RLO),以决定培训期间的加权办法。拟议的动态方法使多尺度培训损失得到更好的利用,而没有额外的计算复杂性和可学习的反演算参数。实验表明,我们的方法可以不断提高Pascal VOC和MS COCO基准的各种基线探测器的性能。