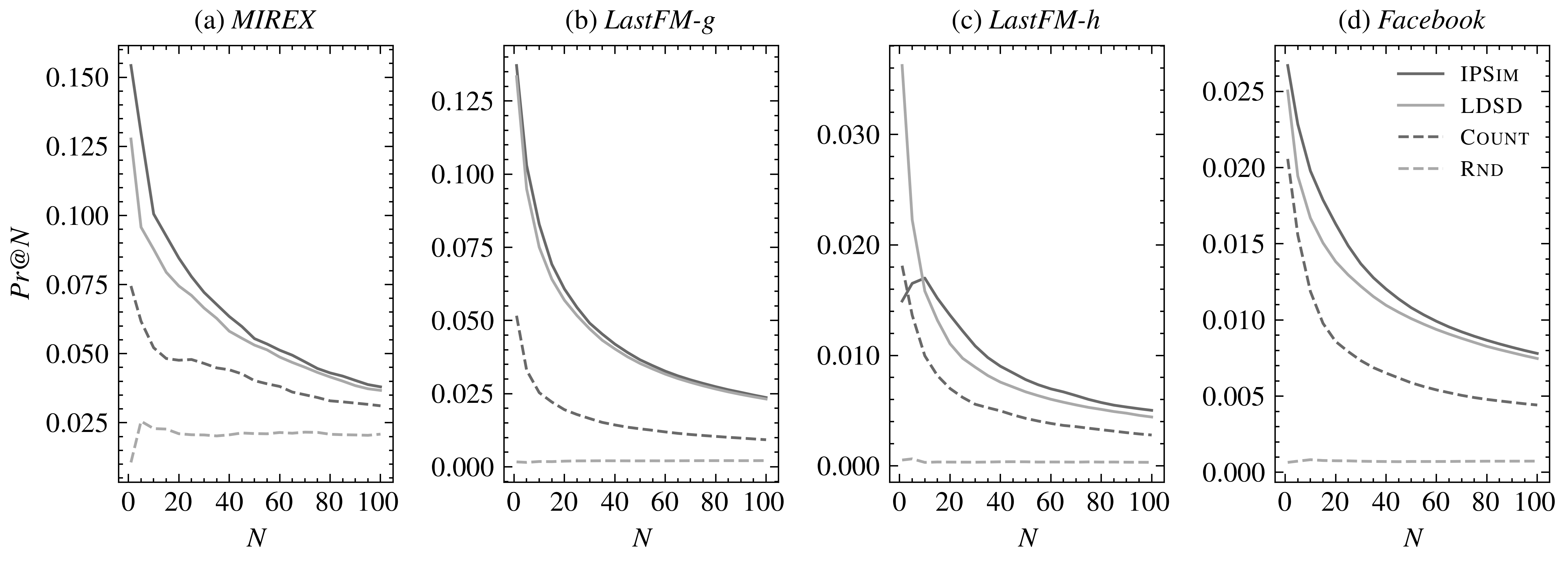
We introduce a novel and interpretable path-based music similarity measure. Our similarity measure assumes that items, such as songs and artists, and information about those items are represented in a knowledge graph. We find paths in the graph between a seed and a target item; we score those paths based on their interestingness; and we aggregate those scores to determine the similarity between the seed and the target. A distinguishing feature of our similarity measure is its interpretability. In particular, we can translate the most interesting paths into natural language, so that the causes of the similarity judgements can be readily understood by humans. We compare the accuracy of our similarity measure with other competitive path-based similarity baselines in two experimental settings and with four datasets. %\sout{The results show that our measure has highest accuracy in general.} The results highlight the validity of our approach to music similarity, and demonstrate that path interestingness scores can be the basis of an accurate and interpretable similarity measure.
翻译:我们引入了一种新颖和可解释的基于路径的音乐相似度测量。 我们的相似度测量假设, 诸如歌曲和艺术家之类的项目, 以及那些项目的信息在知识图中都有体现。 我们在图表中找到种子和目标项目之间的路径; 我们根据它们的有趣程度来评分这些路径; 我们对这些评分进行汇总以确定种子和目标之间的相似性。 我们相似度测量的一个显著特征是它的可解释性。 特别是, 我们可以将最有趣的路径转换为自然语言, 以便人类能够很容易地理解相似性判断的原因。 我们比较了我们相似度测量的准确性与其他竞争性路径相似性基线在两个实验环境中和四个数据集中的精确性。 ==sout{结果显示, 我们的测分数具有最高的一般准确性。}结果突出了我们对待音乐相似性的方法的有效性,并表明路径有趣的分数可以成为准确和可解释相似性测量的基础。