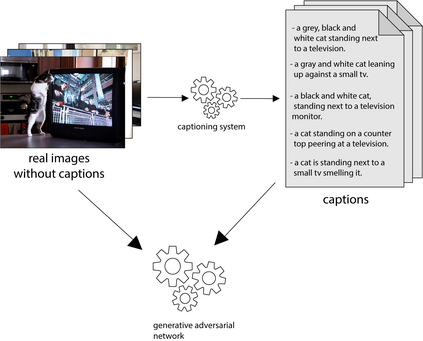
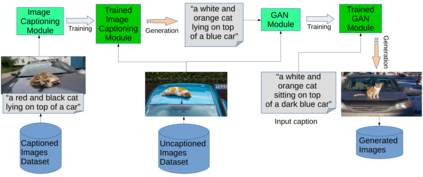
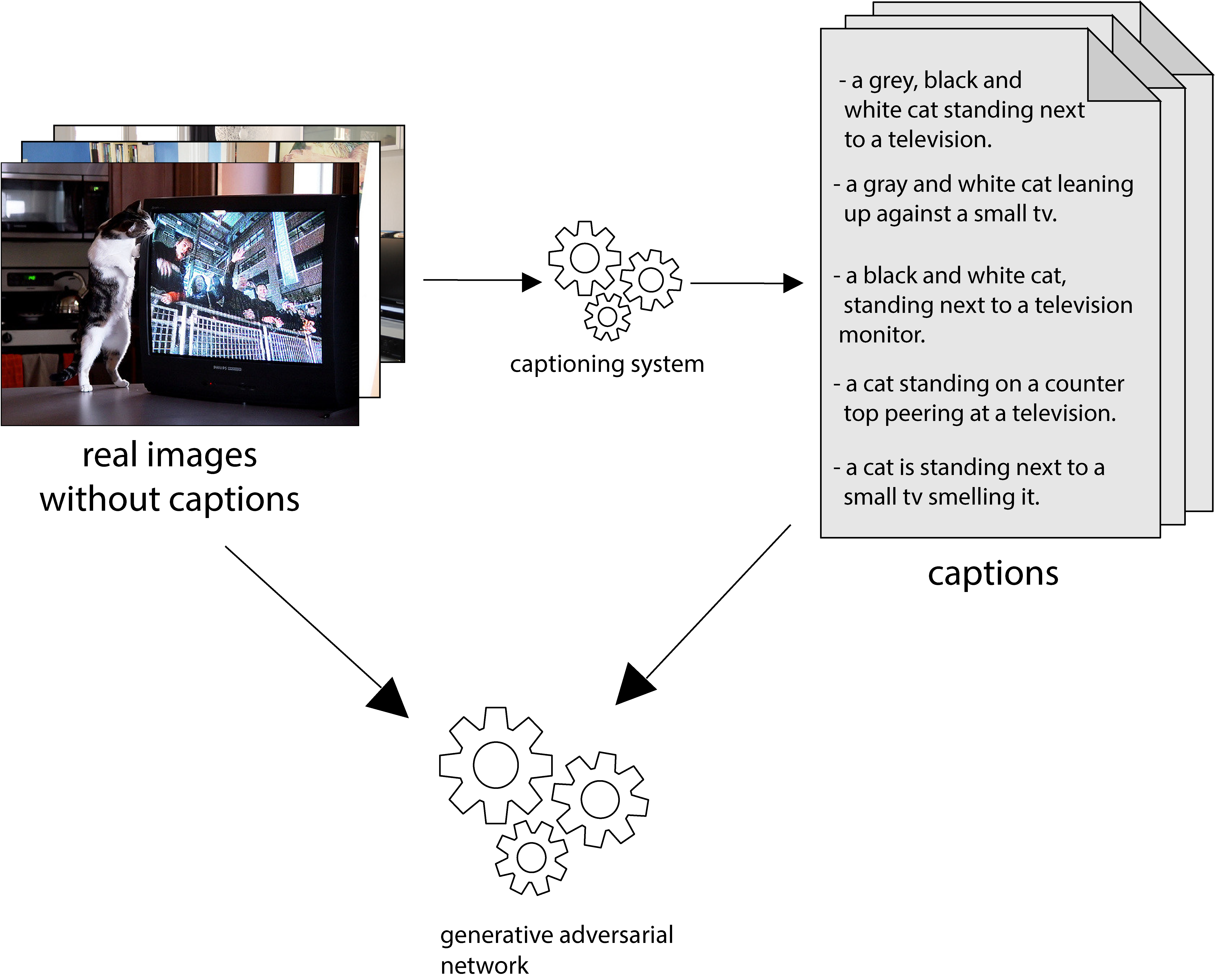
Text to Image Synthesis refers to the process of automatic generation of a photo-realistic image starting from a given text and is revolutionizing many real-world applications. In order to perform such process it is necessary to exploit datasets containing captioned images, meaning that each image is associated with one (or more) captions describing it. Despite the abundance of uncaptioned images datasets, the number of captioned datasets is limited. To address this issue, in this paper we propose an approach capable of generating images starting from a given text using conditional GANs trained on uncaptioned images dataset. In particular, uncaptioned images are fed to an Image Captioning Module to generate the descriptions. Then, the GAN Module is trained on both the input image and the machine-generated caption. To evaluate the results, the performance of our solution is compared with the results obtained by the unconditional GAN. For the experiments, we chose to use the uncaptioned dataset LSUN bedroom. The results obtained in our study are preliminary but still promising.
翻译:图像合成文本指的是从给定文本开始自动生成照片现实图像的过程, 并且正在使许多真实世界应用程序发生革命性。 为了进行这种过程, 有必要利用含有字幕图像的数据集, 这意味着每个图像都与描述它的一个( 或更多的) 字幕相关。 尽管有大量未字幕图像数据集, 字幕数据集的数量有限 。 为了解决这个问题, 我们在本文件中建议一种方法, 能够从某个文本生成图像, 使用在未覆盖图像数据集方面受过训练的有条件 GANs 生成的图像。 特别是, 未覆盖图像被装入图像描述模块 。 然后, GAN 模块将同时在输入图像和机器生成的字幕上接受培训 。 为了评估结果, 我们解决方案的性能与无条件 GAN 所获得的结果进行比较 。 对于实验, 我们选择使用未覆盖数据集 LSUN 卧室 。 我们的研究结果是初步的, 但仍然很有希望 。