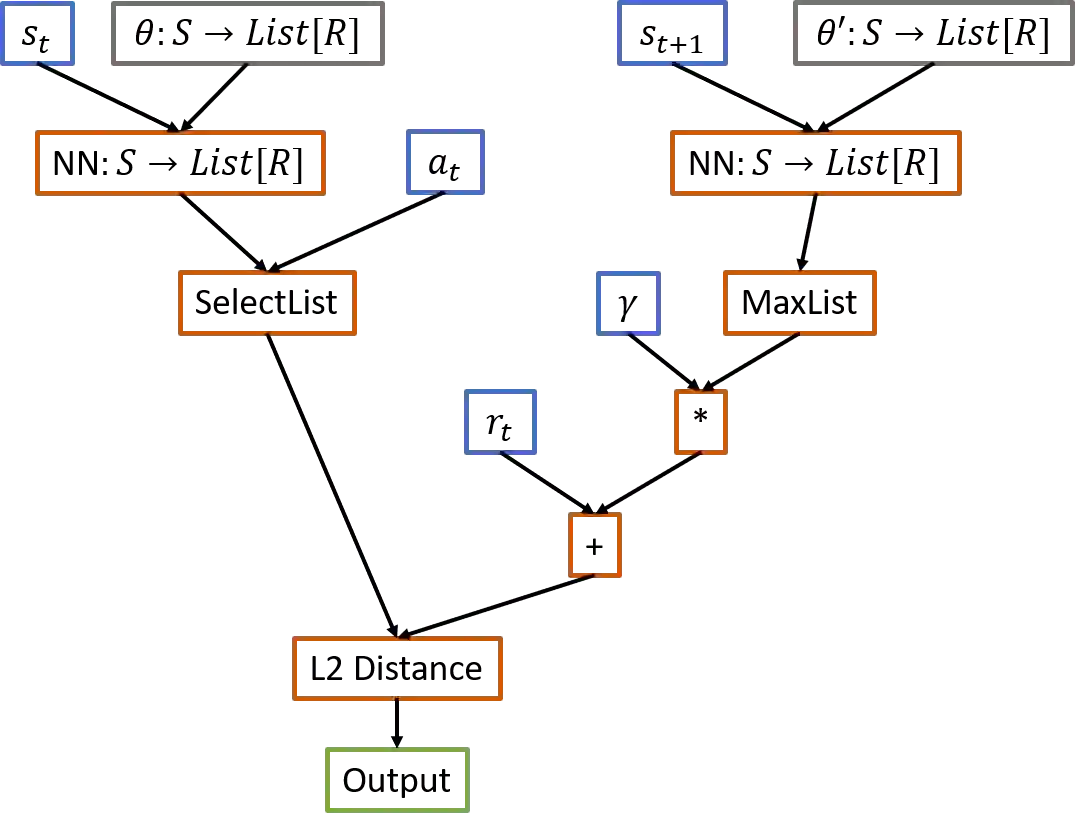
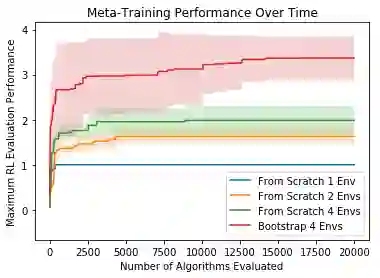
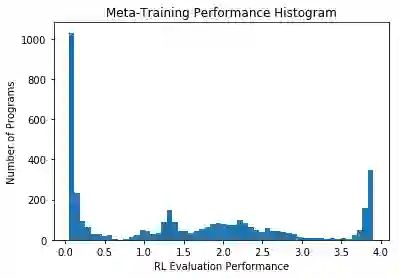
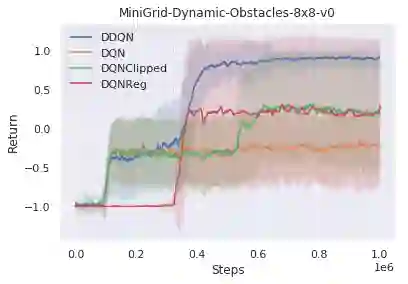
We propose a method for meta-learning reinforcement learning algorithms by searching over the space of computational graphs which compute the loss function for a value-based model-free RL agent to optimize. The learned algorithms are domain-agnostic and can generalize to new environments not seen during training. Our method can both learn from scratch and bootstrap off known existing algorithms, like DQN, enabling interpretable modifications which improve performance. Learning from scratch on simple classical control and gridworld tasks, our method rediscovers the temporal-difference (TD) algorithm. Bootstrapped from DQN, we highlight two learned algorithms which obtain good generalization performance over other classical control tasks, gridworld type tasks, and Atari games. The analysis of the learned algorithm behavior shows resemblance to recently proposed RL algorithms that address overestimation in value-based methods.
翻译:我们建议了一种方法,通过搜索计算图的空间来进行元学习强化学习算法,计算损失函数,以优化无价值模型RL代理器。 所学的算法是域不可知的, 可以概括到培训期间看不到的新环境。 我们的方法既可以从零中学习,也可以从已知的现有算法(如DQN)中套取靴子,从而进行可解释的修改,从而改进性能。 在简单的古典控制和网格世界任务中从零中学习, 我们的方法重新发现了时间差异算法。 从 DQN 中引入的, 我们突出强调了获得优于其他古典控制任务、 网格世界类型任务和 Atari 游戏的超常化性功能的两种已学算法。 对所学的算法行为的分析显示与最近提出的RL 算法相似之处, 后者解决了基于价值方法的过高估计。