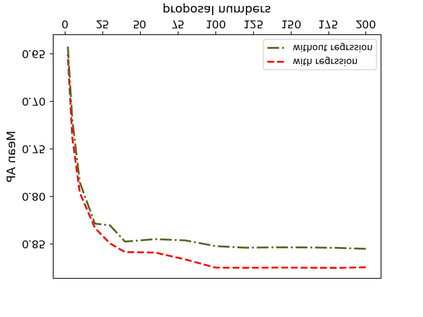
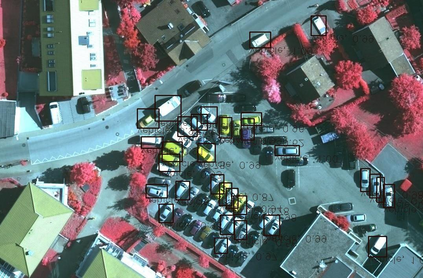
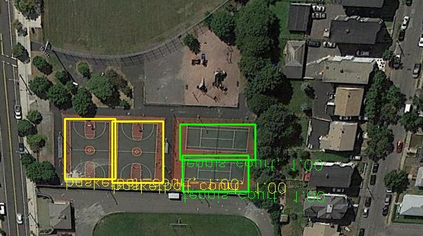
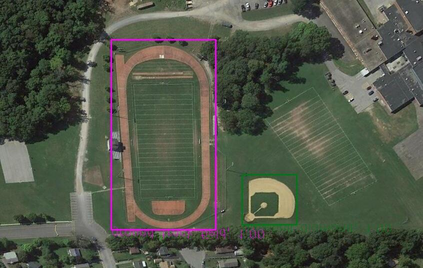
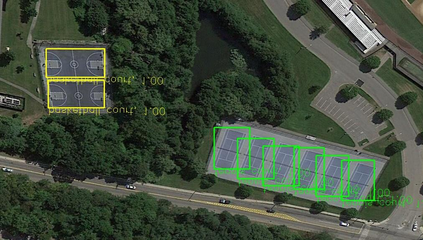
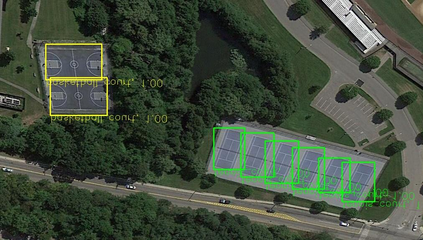
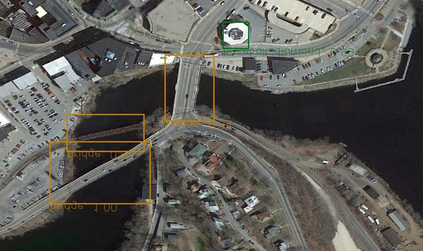
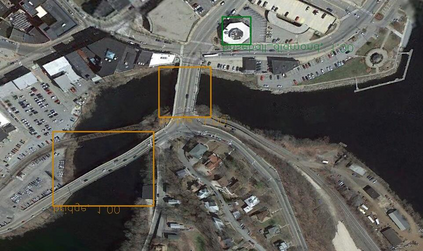
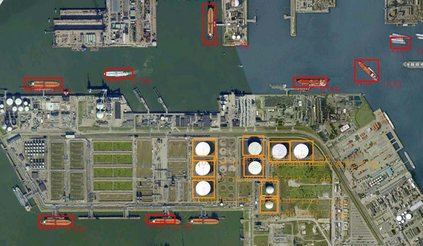
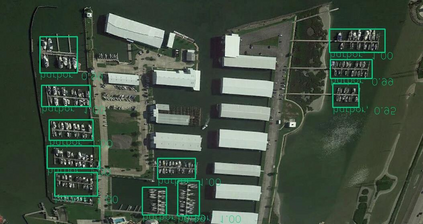
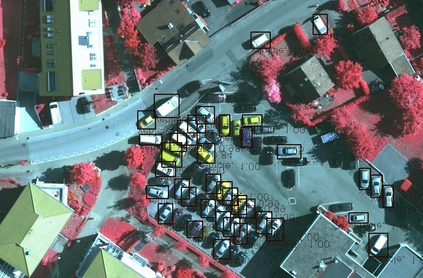
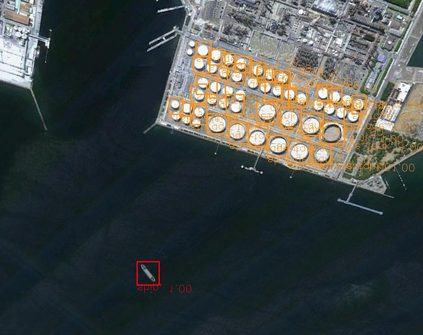
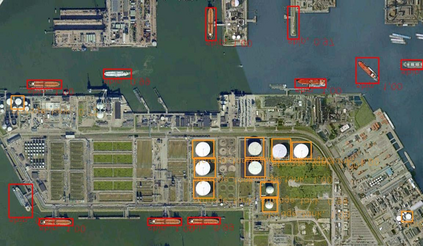
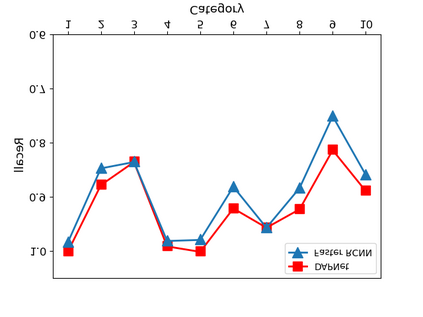
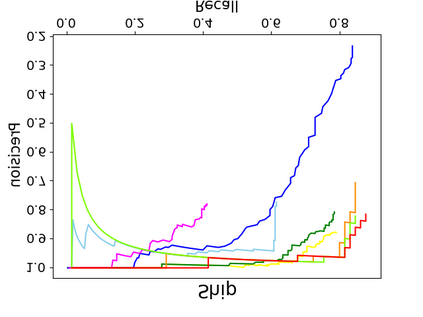
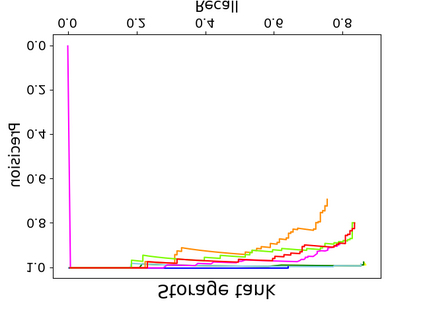
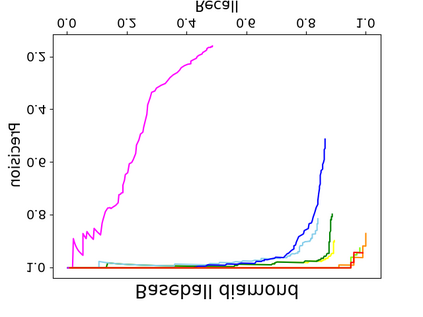
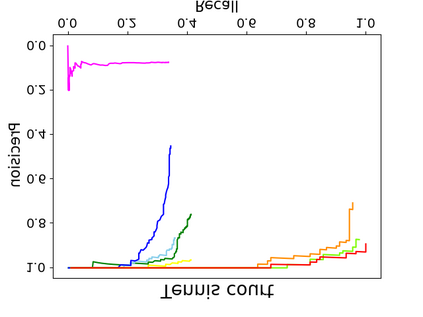
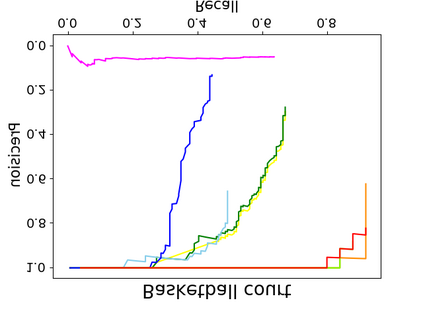
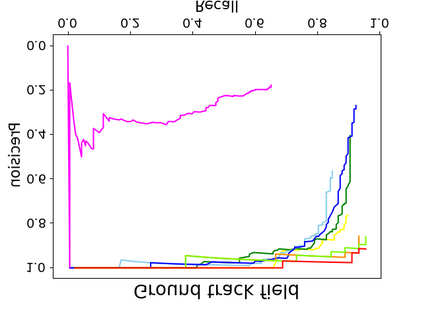
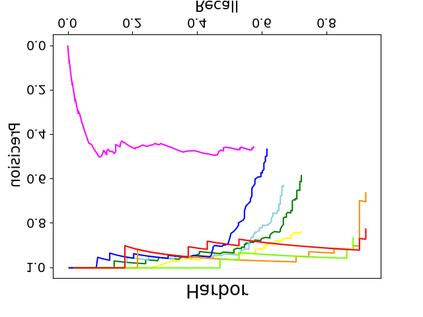
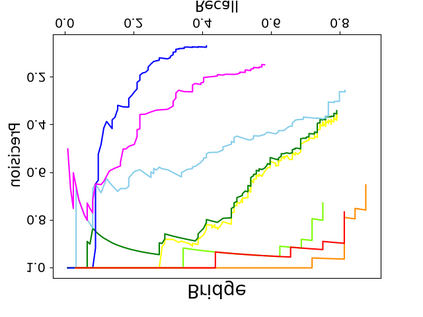
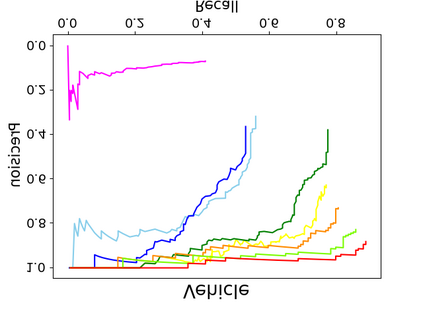
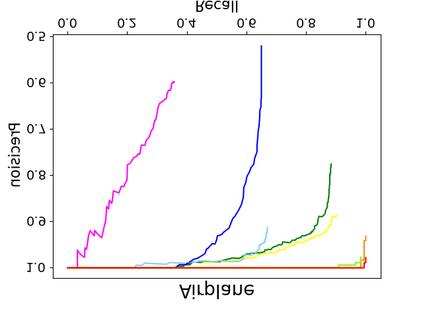
Object detection is a fundamental and challenging problem in aerial and satellite image analysis. More recently, a two-stage detector Faster R-CNN is proposed and demonstrated to be a promising tool for object detection in optical remote sensing images, while the sparse and dense characteristic of objects in remote sensing images is complexity. It is unreasonable to treat all images with the same region proposal strategy, and this treatment limits the performance of two-stage detectors. In this paper, we propose a novel and effective approach, named deep adaptive proposal network (DAPNet), address this complexity characteristic of object by learning a new category prior network (CPN) on the basis of the existing Faster R-CNN architecture. Moreover, the candidate regions produced by DAPNet model are different from the traditional region proposal network (RPN), DAPNet predicts the detail category of each candidate region. And these candidate regions combine the object number, which generated by the category prior network to achieve a suitable number of candidate boxes for each image. These candidate boxes can satisfy detection tasks in sparse and dense scenes. The performance of the proposed framework has been evaluated on the challenging NWPU VHR-10 data set. Experimental results demonstrate the superiority of the proposed framework to the state-of-the-art.
翻译:在空中和卫星图像分析中,发现物体是一个根本性的、具有挑战性的问题。最近,提出并展示了两阶段探测器快速R-CNN,这是在光学遥感图像中进行物体探测的一个很有希望的工具,而遥感图像中物体的稀少和密集特征是复杂的。用同样的区域建议战略处理所有图像是不合理的,这种处理限制了两阶段探测器的性能。在本文件中,我们提出了一个新颖和有效的办法,称为深调建议网络(DAPNet),通过在现有快速R-CNN结构的基础上学习新的类别,处理物体的这一复杂特征。此外,DAPNet模型产生的候选区域不同于传统的区域建议网络(RPN),DAPNet预测每个候选区域的详细类别。这些候选区域将前一个类别产生的物体编号结合起来,以便为每个图像找到一个合适的候选箱。这些候选框可以在稀少和密集的场景点满足探测任务。在具有挑战性的NWPU-HR-10数据集上对拟议框架的性能进行了评价。实验结果显示拟议框架的优越性。