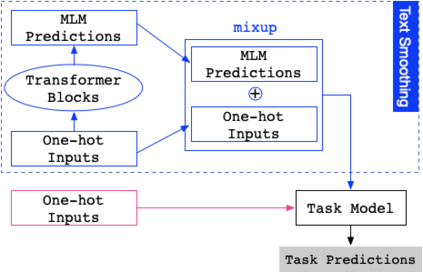
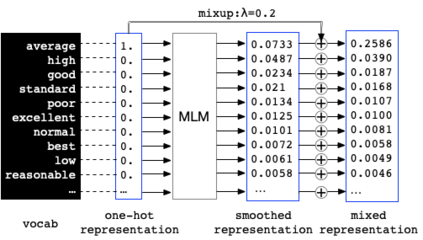
Before entering the neural network, a token is generally converted to the corresponding one-hot representation, which is a discrete distribution of the vocabulary. Smoothed representation is the probability of candidate tokens obtained from a pre-trained masked language model, which can be seen as a more informative substitution to the one-hot representation. We propose an efficient data augmentation method, termed text smoothing, by converting a sentence from its one-hot representation to a controllable smoothed representation. We evaluate text smoothing on different benchmarks in a low-resource regime. Experimental results show that text smoothing outperforms various mainstream data augmentation methods by a substantial margin. Moreover, text smoothing can be combined with those data augmentation methods to achieve better performance.
翻译:在进入神经网络之前,一般将一个符号转换为相应的单热表达式,即单热表达式,这是单词的分散分布。平滑的表示式是指从预先训练过的蒙面语言模式中获得候选符号的概率,这可以被视为对单热表达式的更有意义的替代。我们建议一种有效的数据增强方法,称为文字平滑,将一个单热表达式的句子转换为一个可控制、平滑的表达式。我们评估的是低资源制度中不同基准的平滑文本。实验结果显示,文本以相当大的幅度优于各种主流数据增强方法。此外,文本平滑可以与这些数据增强方法相结合,以取得更好的性能。