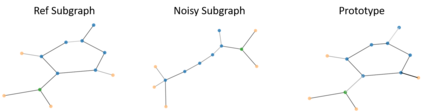
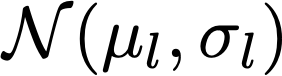Graph Neural Networks (GNNs) are a powerful tool for machine learning on graphs.GNNs combine node feature information with the graph structure by recursively passing neural messages along edges of the input graph. However, incorporating both graph structure and feature information leads to complex models, and explaining predictions made by GNNs remains unsolved. Here we propose GNNExplainer, the first general, model-agnostic approach for providing interpretable explanations for predictions of any GNN-based model on any graph-based machine learning task. Given an instance, GNNExplainer identifies a compact subgraph structure and a small subset of node features that have a crucial role in GNN's prediction. Further, GNNExplainer can generate consistent and concise explanations for an entire class of instances. We formulate GNNExplainer as an optimization task that maximizes the mutual information between a GNN's prediction and distribution of possible subgraph structures. Experiments on synthetic and real-world graphs show that our approach can identify important graph structures as well as node features, and outperforms baselines by 17.1% on average. GNNExplainer provides a variety of benefits, from the ability to visualize semantically relevant structures to interpretability, to giving insights into errors of faulty GNNs.
翻译:GNNExplainer将一个缩略图结构与一组节点特性相匹配,这些节点特性在GNN的预测中具有关键作用。此外,GNNExplainer可以为整个几类情况提供一致和简明的解释。我们将GNNExplainer编成一个优化任务,使GNN的预测和可能的子图结构分布之间的相互信息最大化。合成图和真实世界图的实验显示,我们的方法可以确定重要的图形结构以及节点特征,并用17.1%的图像模型为GNNS的可视性解释。