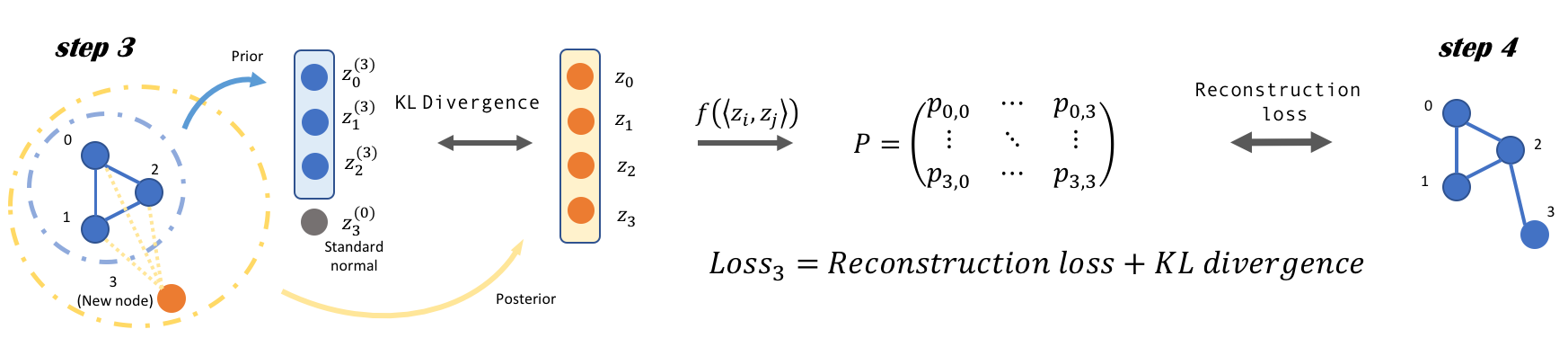Modeling generative process of growing graphs has wide applications in social networks and recommendation systems, where cold start problem leads to new nodes isolated from existing graph. Despite the emerging literature in learning graph representation and graph generation, most of them can not handle isolated new nodes without nontrivial modifications. The challenge arises due to the fact that learning to generate representations for nodes in observed graph relies heavily on topological features, whereas for new nodes only node attributes are available. Here we propose a unified generative graph convolutional network that learns node representations for all nodes adaptively in a generative model framework, by sampling graph generation sequences constructed from observed graph data. We optimize over a variational lower bound that consists of a graph reconstruction term and an adaptive Kullback-Leibler divergence regularization term. We demonstrate the superior performance of our approach on several benchmark citation network datasets.
翻译:成形图的模型化过程在社交网络和建议系统中有着广泛的应用,冷起点问题导致与现有图表分离的新节点。尽管在学习图形表解和图形生成方面正在出现文献,但大多数这类文献都无法在没有三重修改的情况下处理孤立的新节点。挑战的产生是由于以下事实:在观测到的图形中,学习为节点生成表示方式的学习严重依赖地形特征,而对于新的节点只有节点属性。我们在这里建议建立一个统一的基因图集共变网络,通过抽样图形生成序列从观测到的图表数据中得出,学习在基因模型框架内适应性地反映所有节点的节点。我们优化了由图形重建术语和适应性 Kullback-Lebell-Lebell 差异规范术语组成的低变式下边框。我们展示了我们在若干基准引用网络数据集上的方法的优异性表现。