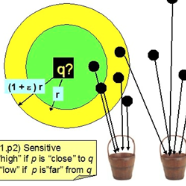
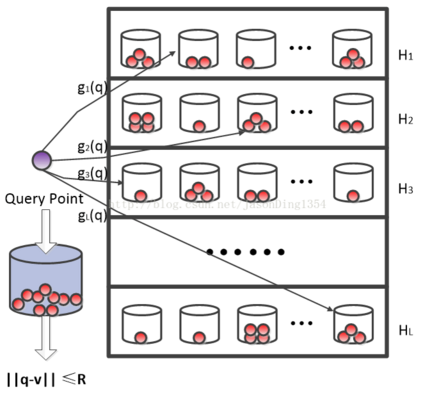
Data similarity (or distance) computation is a fundamental research topic which fosters a variety of similarity-based machine learning and data mining applications. In big data analytics, it is impractical to compute the exact similarity of data instances due to high computational cost. To this end, the Locality Sensitive Hashing (LSH) technique has been proposed to provide accurate estimators for various similarity measures between sets or vectors in an efficient manner without the learning process. Structured data (e.g., sequences, trees and graphs), which are composed of elements and relations between the elements, are commonly seen in the real world, but the traditional LSH algorithms cannot preserve the structure information represented as relations between elements. In order to conquer the issue, researchers have been devoted to the family of the hierarchical LSH algorithms. In this paper, we explore the present progress of the research into hierarchical LSH from the following perspectives: 1) Data structures, where we review various hierarchical LSH algorithms for three typical data structures and uncover their inherent connections; 2) Applications, where we review the hierarchical LSH algorithms in multiple application scenarios; 3) Challenges, where we discuss some potential challenges as future directions.
翻译:数据相似性(或距离)计算是一个根本性的研究课题,它促进以类似性为基础的各种机器学习和数据挖掘应用。在大数据分析中,由于计算成本高,计算数据实例的精确相似性是不切实际的。为此,提出了地方敏感散列(LSH)技术,以提供准确的估测标准,用于在不经过学习过程的情况下以有效的方式对各组或矢量进行各种相似性测量。结构化数据(例如序列、树木和图表),由各种元素和各个元素之间的关系组成,在现实世界中是常见的,但传统的LSH算法无法保存作为元素之间关系的结构信息。为了克服问题,研究人员们专门研究等级性LSH算法(LSH)的类别。在本文件中,我们从以下角度探讨目前对等级LSH的研究的进展:(1)数据结构,我们从三个典型的数据结构中审查各种等级LSH算法,并发现它们之间的内在联系;(2)应用,我们在这里审查多种应用情景中的等级性LSH算法;(3),我们在这里讨论未来方向上的一些挑战。