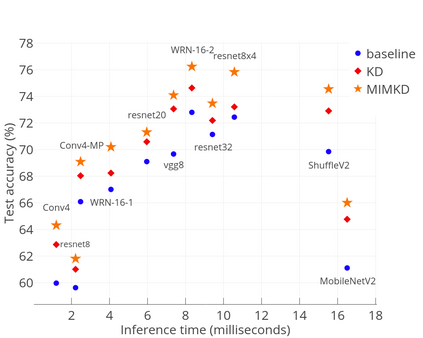
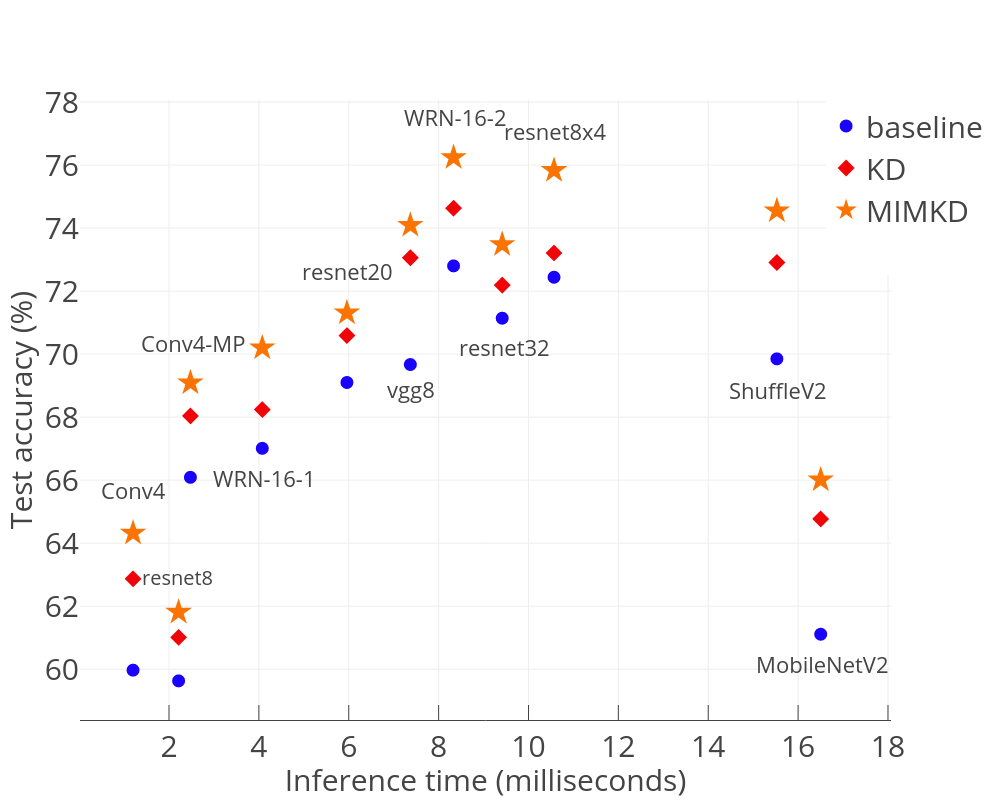
Knowledge distillation is a widely used general technique to transfer knowledge from a teacher network to a student network. In this work, we propose Mutual Information Maximization Knowledge Distillation (MIMKD). Our method uses a contrastive objective to simultaneously estimate and maximize a lower bound on the mutual information between intermediate and global feature representations from the teacher and the student networks. Our method is flexible, as the proposed mutual information maximization does not impose significant constraints on the structure of the intermediate features of the networks. As such, we can distill knowledge from arbitrary teachers to arbitrary students. Our empirical results show that our method outperforms competing approaches across a wide range of student-teacher pairs with different capacities, with different architectures, and when student networks are with extremely low capacity. We are able to obtain 74.55% accuracy on CIFAR100 with a ShufflenetV2 from a baseline accuracy of 69.8% by distilling knowledge from ResNet50.
翻译:知识蒸馏是一种广泛使用的一般技术,从教师网络向学生网络传授知识。在这项工作中,我们提出相互信息最大化知识蒸馏(MIMKD ) 。我们的方法使用一个对比性目标,即同时估计和最大限度地扩大教师和学生网络的中间和全球地物代表之间的相互信息。我们的方法是灵活的,因为拟议的相互信息最大化不会对网络的中间地物结构施加重大限制。因此,我们可以从任意教师向任意学生提取知识。我们的经验结果表明,我们的方法优于不同能力、不同建筑和学生网络能力极低的广大学生-教师对口的竞争方法。我们能够通过从ResNet50中提取知识,从69.8%的基线精度中获得74.55%的精度,在ShufflenetV2中,我们可以从ShufflenetV2获得74.55%的精度。