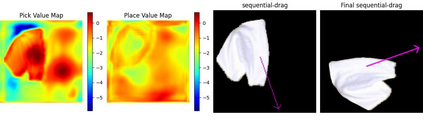
Pre-defined manipulation primitives are widely used for cloth manipulation. However, cloth properties such as its stiffness or density can highly impact the performance of these primitives. Although existing solutions have tackled the parameterisation of pick and place locations, the effect of factors such as the velocity or trajectory of quasi-static and dynamic manipulation primitives has been neglected. Choosing appropriate values for these parameters is crucial to cope with the range of materials present in house-hold cloth objects. To address this challenge, we introduce the Quasi-Dynamic Parameterisable (QDP) method, which optimises parameters such as the motion velocity in addition to the pick and place positions of quasi-static and dynamic manipulation primitives. In this work, we leverage the framework of Sequential Reinforcement Learning to decouple sequentially the parameters that compose the primitives. To evaluate the effectiveness of the method we focus on the task of cloth unfolding with a robotic arm in simulation and real-world experiments. Our results in simulation show that by deciding the optimal parameters for the primitives the performance can improve by 20% compared to sub-optimal ones. Real-world results demonstrate the advantage of modifying the velocity and height of manipulation primitives for cloths with different mass, stiffness, shape and size. Supplementary material, videos, and code, can be found at https://sites.google.com/view/qdp-srl.
翻译:预定义的操作基元广泛用于布料操作。然而,布料的刚度或密度等性质可以高度影响这些基元的性能。尽管现有解决方案已经解决了拾放位置的参数化问题,但准静态和动态操作基元的速度或轨迹等因素的影响被忽略了。选择适当的参数值是应对家用布料中存在的材料范围的关键。为了解决这一挑战,我们介绍了准动态可参数化(QDP)方法,该方法优化参数,例如准静态和动态操作基元的运动速度以及拾放位置。在这项工作中,我们利用连续强化学习的框架,将组成基元的参数分解为顺序子问题。为了评估该方法的有效性,我们专注于模拟和实际实验中的布料展开任务。我们在模拟中的结果表明,通过决定基元的最优参数,性能可以提高20%,与次优参数相比。实际结果表明,修改不同质量、刚度、形状和大小的布料的操作基元速度和高度具有优势。补充材料、视频和代码可在https://sites.google.com/view/qdp-srl找到。