
题目
通过元学习的贝叶斯自适应深度RL, VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning
关键字
元学习,变分推理,贝叶斯推理,最大期望,强化学习,深度学习,人工智能
简介
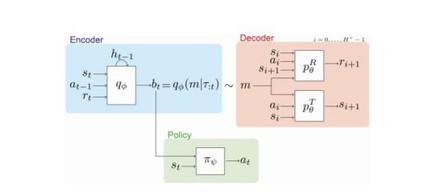
在未知环境中权衡探索和开发是最大程度地提高学习过程中预期回报的关键。 一种贝叶斯最优策略,它以最佳方式运行,不仅取决于环境状态,还取决于主体对环境的不确定性,决定其行动。 但是,除了最小的任务外,计算贝叶斯最佳策略是很困难的。 在本文中,我们介绍了变分贝叶斯自适应深度RL(variBAD),这是一种在未知环境中进行元学习以进行近似推理的方法,并直接在动作选择过程中合并任务不确定性。 在网格世界中,我们说明variBAD如何根据任务不确定性执行结构化的在线探索。 我们还评估了在meta-RL中广泛使用的MuJoCo域上的variBAD,并表明与现有方法相比,它在训练过程中获得了更高的回报。
作者
Luisa Zintgraf, Kyriacos Shiarlis, Maximilian Igl, Sebastian Schulze, Yarin Gal, Katja Hofmann, Shimon Whiteson
成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2018年1月31日


相关VIP内容
相关资讯