17种深度强化学习算法用Pytorch实现

新智元报道
【新智元导读】深度强化学习已经在许多领域取得了瞩目的成就,并且仍是各大领域受热捧的方向之一。本文推荐一个用PyTorch实现了17种深度强化学习算法的教程和代码库,帮助大家在实践中理解深度RL算法。

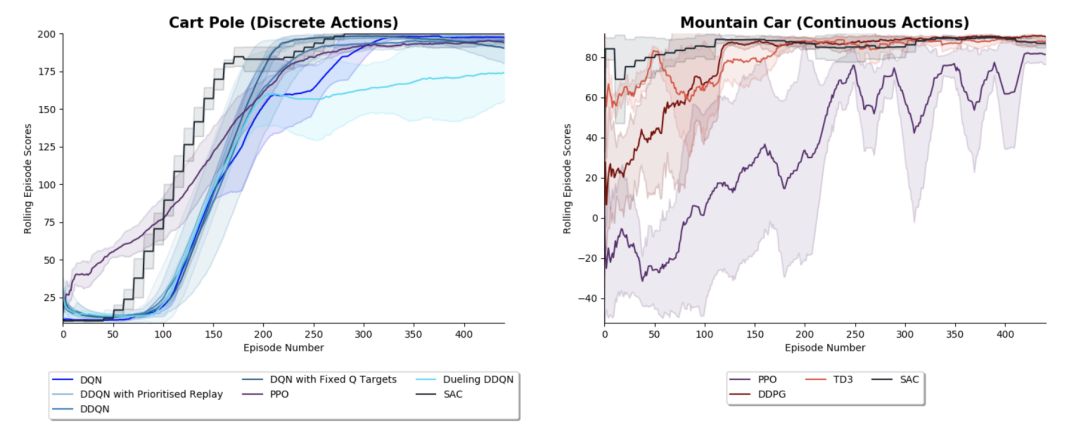
Deep Q Learning (DQN) (Mnih et al. 2013)
DQN with Fixed Q Targets (Mnih et al. 2013)
Double DQN (DDQN) (Hado van Hasselt et al. 2015)
DDQN with Prioritised Experience Replay (Schaul et al. 2016)
Dueling DDQN (Wang et al. 2016)
REINFORCE (Williams et al. 1992)
Deep Deterministic Policy Gradients (DDPG) (Lillicrap et al. 2016 )
Twin Delayed Deep Deterministic Policy Gradients (TD3) (Fujimoto et al. 2018)
Soft Actor-Critic (SAC & SAC-Discrete) (Haarnoja et al. 2018)
Asynchronous Advantage Actor Critic (A3C) (Mnih et al. 2016)
Syncrhonous Advantage Actor Critic (A2C)
Proximal Policy Optimisation (PPO) (Schulman et al. 2017)
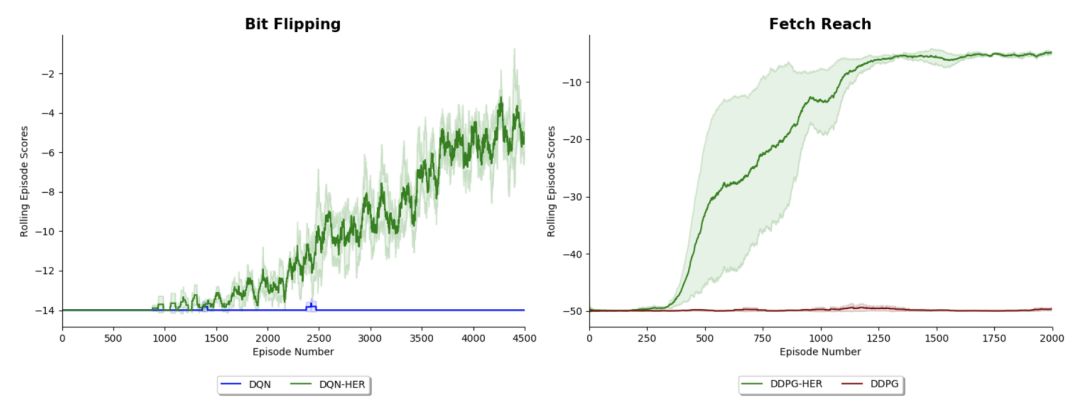
DQN with Hindsight Experience Replay (DQN-HER) (Andrychowicz et al. 2018)
DDPG with Hindsight Experience Replay (DDPG-HER) (Andrychowicz et al. 2018 )
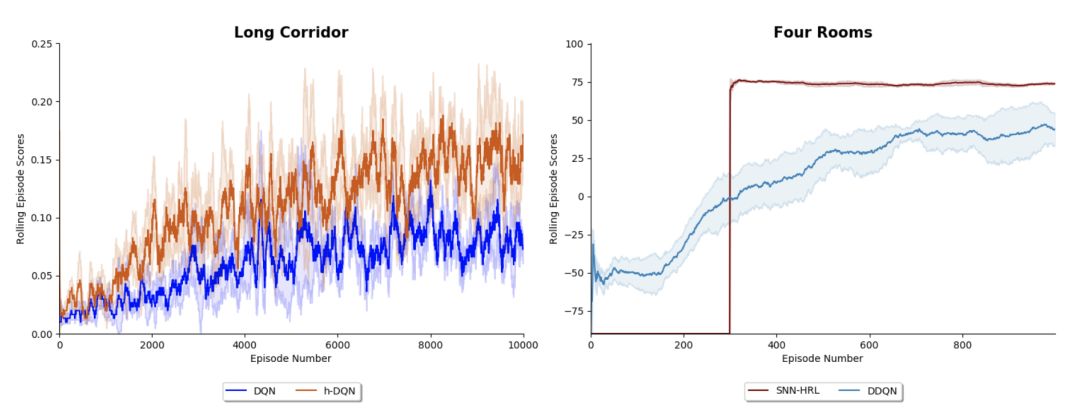
Hierarchical-DQN (h-DQN) (Kulkarni et al. 2016)
Stochastic NNs for Hierarchical Reinforcement Learning (SNN-HRL) (Florensa et al. 2017)
Diversity Is All You Need (DIAYN) (Eyensbach et al. 2018)
Bit Flipping 游戏 (Andrychowicz et al. 2018)
Four Rooms 游戏 (Sutton et al. 1998)
Long Corridor 游戏 (Kulkarni et al. 2016)
Ant-{Maze, Push, Fall} (Nachum et al. 2018)
├── agents├── actor_critic_agents├── DQN_agents├── policy_gradient_agents└── stochastic_policy_search_agents├── environments├── results└── data_and_graphs├── tests├── utilities└── data structures
git clone https://github.com/p-christ/Deep_RL_Implementations.gitcd Deep_RL_Implementationsconda create --name myenvnameyconda activate myenvnamepip3 install -r requirements.txtpython Results/Cart_Pole.py



