由于自动驾驶的复杂性和安全性关键性,最近的工作通常在为推进自动驾驶研究而设计的模拟器上测试他们的想法。尽管将自动驾驶建模为轨迹优化问题很方便,但这些方法中很少有借助在线强化学习(RL)来解决具有挑战性的驾驶场景。这主要是因为经典的在线RL算法最初是为诸如Atari游戏之类的玩具问题设计的,这些问题可以在几个小时内解决。相比之下,由于模拟耗时和问题本身的难度,使用这些在线强化学习方法可能需要几周或几个月的时间才能在自动驾驶任务上获得令人满意的结果。因此,一个有前途的自动驾驶在线强化学习流程应该是效率驱动的。
本文研究了由于昂贵的模拟成本,直接将通用单智能体或分布式RL算法应用于CARLA自动驾驶管道的低效性。本文提出两种异步分布式强化学习方法,多并行SAC (off-policy)和多并行PPO (on-policy),致力于通过一个专门的分布式框架来加速CARLA模拟器上的在线强化学习训练,该框架建立进程间和进程内并行。所提出的分布式多智能体强化学习算法在各种CARLA自动驾驶任务上以更短和合理的时间实现了最先进的性能。
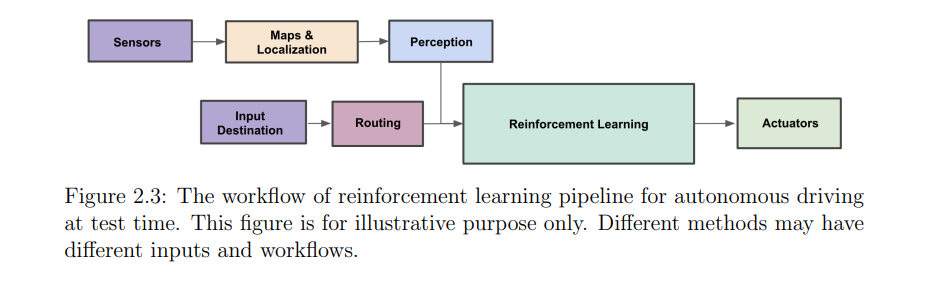
自动驾驶的许多进展都集中在模块化方法上,其中整个任务被划分为多个子任务,如感知、规划和控制[12,46,54,61,63,94]。虽然这种范式在典型的trac场景中表现良好,但在没有为边缘情况精心设计的特殊程序的情况下,它很难处理分布外驾驶情况。为了应对这个问题,强化学习(RL)受到了关注,因为自动驾驶可以自然地视为一个轨迹优化问题,我们需要对驾驶过程进行最优控制。经验证据表明,强化学习方法能够以高度自动化的方式实现这一目标,而不需要手动处理具有挑战性的长尾和罕见情况。它们的成功已经在许多决策任务中得到了证明,例如玩策略游戏或操纵机器人[8,60,74,78,79,81,88]。