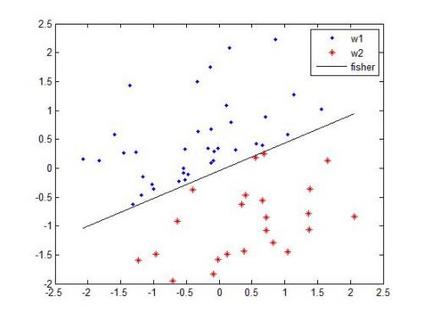
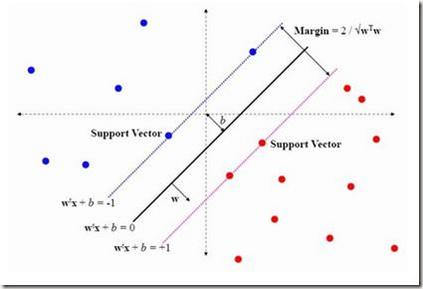
Support vector machines (SVM) and other kernel techniques represent a family of powerful statistical classification methods with high accuracy and broad applicability. Because they use all or a significant portion of the training data, however, they can be slow, especially for large problems. Piecewise linear classifiers are similarly versatile, yet have the additional advantages of simplicity, ease of interpretation and, if the number of component linear classifiers is not too large, speed. Here we show how a simple, piecewise linear classifier can be trained from a kernel-based classifier in order to improve the classification speed. The method works by finding the root of the difference in conditional probabilities between pairs of opposite classes to build up a representation of the decision boundary. When tested on 17 different datasets, it succeeded in improving the classification speed of a SVM for 12 of them by up to two orders-of-magnitude. Of these, two were less accurate than a simple, linear classifier. The method is best suited to problems with continuum features data and smooth probability functions. Because the component linear classifiers are built up individually from an existing classifier, rather than through a simultaneous optimization procedure, the classifier is also fast to train.
翻译:支持矢量机器( SVM) 和其他内核技术代表了强大的统计分类方法组合, 具有高度准确性和广泛适用性。 但是,由于它们使用培训数据的所有或大部分内容, 它们可能很慢, 特别是对于大问题来说。 细微线性分类器同样具有多功能性, 但具有简单、 易解的附加优势, 如果组件线性分类器的数量不是太大, 则具有速度。 这里我们展示了如何从一个以内核为基础的分类器中训练一个简单、 笔性线性线性分类器, 以便提高分类速度。 这种方法通过找出不同类对等之间有条件概率差异的根源, 以建立决定边界的表示。 在17个不同的数据集上测试时, 它成功地提高了一个SVM的分类速度, 其中12个的分类速度达到两个 。 其中两个比一个简单、 线性分类器的分类器更不准确。 这种方法最适合于连续特性数据和光度概率函数的问题。 因为组件线性分类器是由一个现有分类器单独建立起来的, 而不是通过同步的压缩程序 。