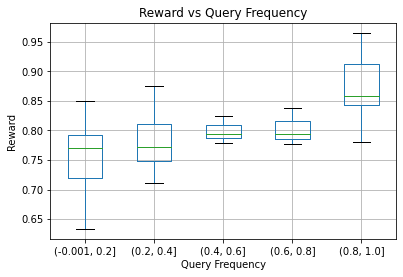
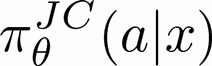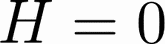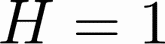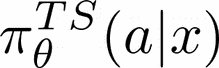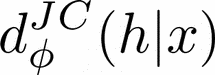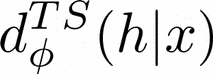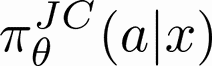Human-AI complementarity is important when neither the algorithm nor the human yields dominant performance across all instances in a given context. Recent work that explored human-AI collaboration has considered decisions that correspond to classification tasks. However, in many important contexts where humans can benefit from AI complementarity, humans undertake course of action. In this paper, we propose a framework for a novel human-AI collaboration for selecting advantageous course of action, which we refer to as Learning Complementary Policy for Human-AI teams (\textsc{lcp-hai}). Our solution aims to exploit the human-AI complementarity to maximize decision rewards by learning both an algorithmic policy that aims to complement humans by a routing model that defers decisions to either a human or the AI to leverage the resulting complementarity. We then extend our approach to leverage opportunities and mitigate risks that arise in important contexts in practice: 1) when a team is composed of multiple humans with differential and potentially complementary abilities, 2) when the observational data includes consistent deterministic actions, and 3) when the covariate distribution of future decisions differ from that in the historical data. We demonstrate the effectiveness of our proposed methods using data on real human responses and semi-synthetic, and find that our methods offer reliable and advantageous performance across setting, and that it is superior to when either the algorithm or the AI make decisions on their own. We also find that the extensions we propose effectively improve the robustness of the human-AI collaboration performance in the presence of different challenging settings.
翻译:当算法和人类在特定情况下在各种情况下都产生主导性业绩时,人类-AI之间的互补性是重要的。最近探索人类-AI合作的工作考虑了与分类任务相对应的决定。然而,在人类能够受益于AI互补性的许多重要情况下,人类采取行动方针。在本文件中,我们提议了一个新的人类-AI合作框架,以选择有利的行动方针,我们称之为人类-AI团队学习补充政策(ctextsc{lcp-hai});我们的解决办法旨在利用人类-AI的互补性,通过学习一种旨在以人类或AI的决定作为补充的路线模式来补充人类的决定,从而最大限度地获得决策的回报。然而,在许多重要情况下,人类-AI能够利用机会,减轻实践中出现的风险。 1)当一个团队由多种人组成时,我们称之为人类-AI团队的学习补充性政策(ctextscrenticc{lc{lcp-hait});2 当观察性数据包含一致的确定性行动时,以及3)当未来决定的变量分布与历史数据不同时,我们发现我们提出的方法的有效性是有效的,当我们使用真实性方法时,而我们提出的具有高超常性的业绩决定时,我们提出的是提出其高超的。