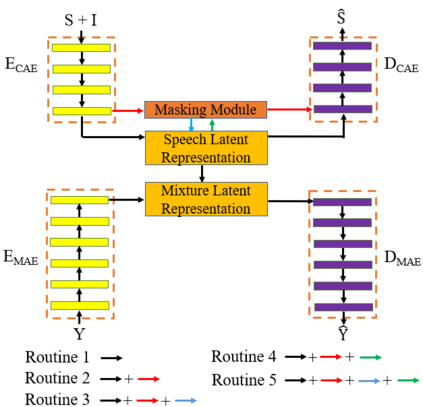
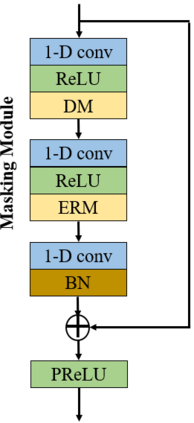
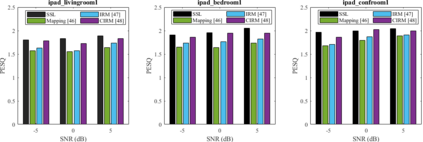
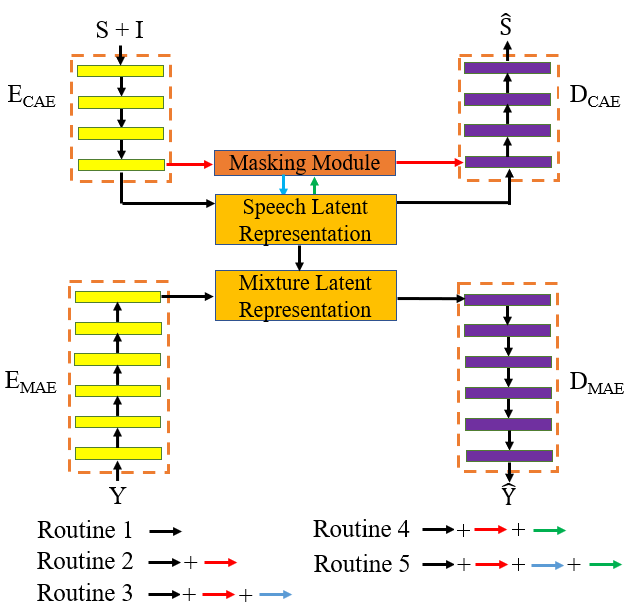
Self-supervised learning (SSL) achieves great success in monaural speech enhancement, while the accuracy of the target speech estimation, particularly for unseen speakers, remains inadequate with existing pre-tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, and spoken content, the latent representation for speech enhancement becomes a tough task. In this paper, we study the effectiveness of each feature which is commonly used in speech enhancement and exploit the feature combination in the SSL case. Besides, we propose an ensemble training strategy. The latent representation of the clean speech signal is learned, meanwhile, the dereverberated mask and the estimated ratio mask are exploited to denoise and dereverberate the mixture. The latent representation learning and the masks estimation are considered as two pre-tasks in the training stage. In addition, to study the effectiveness between the pre-tasks, we compare different training routines to train the model and further refine the performance. The NOISEX and DAPS corpora are used to evaluate the efficacy of the proposed method, which also outperforms the state-of-the-art methods.
翻译:自我监督的学习(SSL)在提高音调方面取得巨大成功,而目标的言语估计准确性,特别是对于隐蔽的发言者来说,与现有的预言任务相比仍然不够。由于言语信号包含多方面的信息,包括演讲者身份、语言学和口头内容,因此增强言语的潜在表述就是一项艰巨的任务。在本文件中,我们研究在加强言语方面常用的每个特征的有效性,并利用SSL案件中的特征组合。此外,我们提议了一项共同培训战略。清洁言语信号的潜在表述方式是学习的,与此同时,皮肤面罩和估计比例蒙面被利用来淡化和淡化混合物。潜在表述方式的学习和口罩估计在培训阶段被视为两项预设任务。此外,为了研究预言的有效性,我们比较了不同的培训程序,以培训模式并进一步改进性能。NOISEX和DAPS Corora被用于评估拟议方法的功效,这也超越了目前采用的方法。