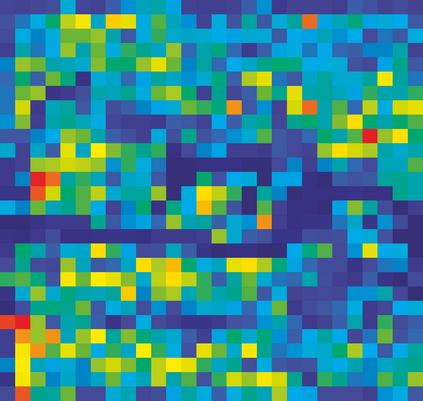
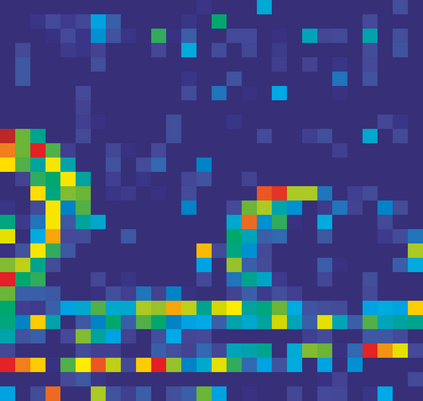
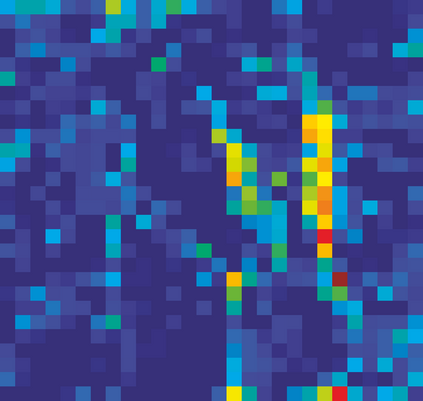
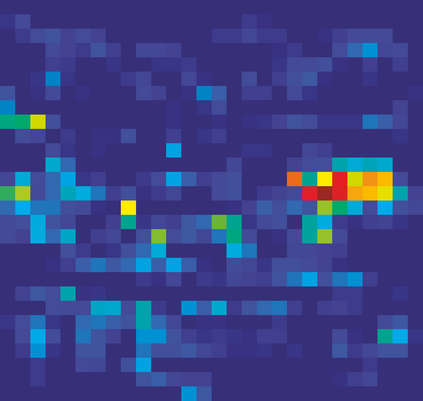
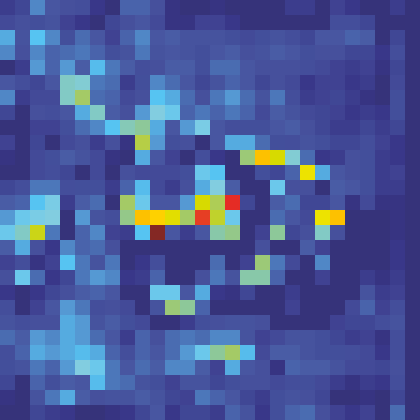
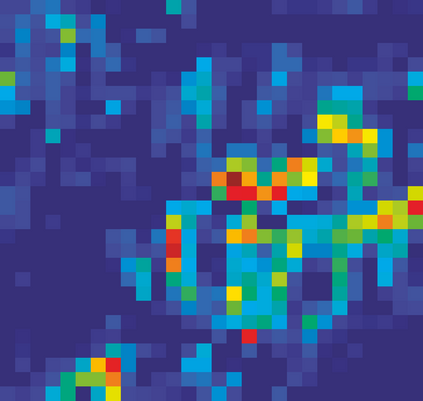
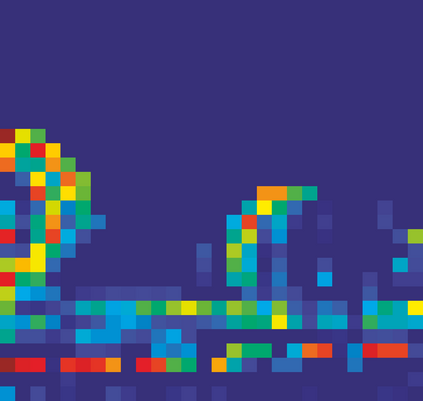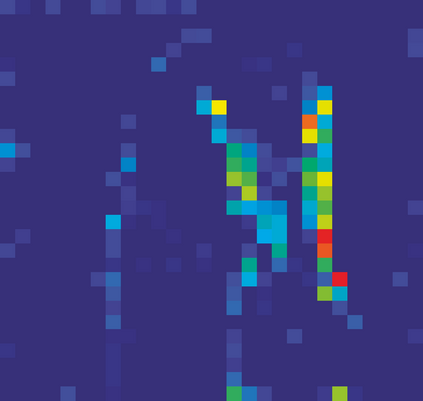Adversarial attacks to image classification systems present challenges to convolutional networks and opportunities for understanding them. This study suggests that adversarial perturbations on images lead to noise in the features constructed by these networks. Motivated by this observation, we develop new network architectures that increase adversarial robustness by performing feature denoising. Specifically, our networks contain blocks that denoise the features using non-local means or other filters; the entire networks are trained end-to-end. When combined with adversarial training, our feature denoising networks substantially improve the state-of-the-art in adversarial robustness in both white-box and black-box attack settings. On ImageNet, under 10-iteration PGD white-box attacks where prior art has 27.9% accuracy, our method achieves 55.7%; even under extreme 2000-iteration PGD white-box attacks, our method secures 42.6% accuracy. A network based on our method was ranked first in Competition on Adversarial Attacks and Defenses (CAAD) 2018 --- it achieved 50.6% classification accuracy on a secret, ImageNet-like test dataset against 48 unknown attackers, surpassing the runner-up approach by ~10%. Code and models will be made publicly available.
翻译:图像分类系统的反向攻击对图像分类系统构成挑战,使网络变异和理解它们的机会。本研究显示,图像上的对抗性扰动导致这些网络所建特征的噪音。我们受此观察的驱动,我们开发了新的网络结构,通过去除特征,提高对抗性强力。具体地说,我们的网络含有以非本地手段或其他过滤器掩盖特征的块块;整个网络都是经过培训的端对端。当与对抗性培训相结合时,我们的特征去除网络大大改进了白箱和黑箱攻击环境中的对抗性强力状态。在图像网中,在10度PGD白箱攻击下,先前艺术的精确度达到27.9%,我们的方法达到55.7%;即使在2000年极端的石化PGD白箱攻击中,我们的方法也保证了42.6%的准确性。一个基于我们方法的网络在对反向攻击和防御(CAAAAD)2018比赛中排名第一,它实现了50.6%的分类,在秘密、图像网络式10型白箱攻击中达到50.6%的精确度的分类。通过可获取的48种无名攻击者将突破式数据。