从语言模型到Seq2Seq:Transformer如戏,全靠Mask

作者丨苏剑林
单位丨追一科技
研究方向丨NLP,神经网络
个人主页丨kexue.fm
相信近一年来(尤其是近半年来),大家都能很频繁地看到各种 Transformer 相关工作(比如 BERT、GPT、XLNet 等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到 XLNet 的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么 Transformer 可以实现乱序语言模型?是怎么实现的?RNN 可以实现吗?
本文从对 Attention 矩阵进行 Mask 的角度,来分析为什么众多 Transformer 模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer 如戏,全靠 Mask”,这是各种花式 Transformer 模型的重要“门道”之一。
读完本文,你或许可以了解到:
1. Attention 矩阵的 Mask 方式与各种预训练方案的关系;
2. 直接利用预训练的 BERT 模型来做 Seq2Seq 任务。
背景
自 Attention is All You Need 以后,基于纯 Attention 的 Transformer 类模型逐渐变得流行起来,而 BERT 的出现则将这股潮流推向了一个新的高度。而后,各种基于大规模预训练的 Transformer 模型的工作不断出现,有基于现成的模型做应用的,有试图更好地去解释和可视化这些模型的,还有改进架构、改进预训练方式等以得到更好结果的。
总的来说,这些以预训练为基础的工作层出不穷,有种琳琅满目的感觉。甚至一定程度上来说,如果你还没有微调过 BERT ,那已经算是落后于主流的 NLP 技术了。
花式预训练
众所周知,传统的模型预训练手段就是语言模型,比如 ELMo [1] 模型就是以 BiLSTM 为基础架构、用两个方向的语言模型分别预训练两个方向的 LSTM 的,后面的 OpenAI 的 GPT、GPT-2 [2] 也是坚定不移地坚持着用祖传的(标准的、单向的)语言模型来预训练。
然而,还有更多花样的预训练玩法。比如 BERT [3] 就用了称之为“掩码语言模型(Masked Language Model)”的方式来预训练,不过这只是普通语言模型的一种变体;还有 XLNet [4]则提出了更彻底的“Permutation Language Modeling”,我们可以称之为“乱序语言模型”;还有 UNILM [5] 模型,直接用单个 BERT 的架构做 Seq2Seq,你可以将它作为一种预训练手段,又或者干脆就用它来做 Seq2Seq 任务。
如此花样百出,让我们不禁疑问:为什么刚好在 Transformer 流行的时代,才出现这种各种大型预训练模型“百花齐放,百家争鸣”的现象?
Transformer专属
事实上,除了单向语言模型及其简单变体掩码语言模型之外,UNILM 的 Seq2Seq 预训练、XLNet 的乱序语言模型预训练,基本可以说是专为 Transformer 架构定制的。说白了,如果是 RNN 架构,根本就不能用乱序语言模型的方式来预训练,至于 Seq2Seq 的预训练方式,则必须同时引入两个模型(encoder 和 decoder),而无法像 Transformer 架构一样,可以一个模型搞定。
这其中的奥妙主要在 Attention 矩阵之上。Attention 实际上相当于将输入两两地算相似度,这构成了一个大小的相似度矩阵(即 Attention 矩阵,n 是句子长度,本文的 Attention 均指 Self Attention),这意味着它的空间占用量是
量级,相比之下,RNN 模型、CNN 模型只不过是 𝒪(n),所以实际上 Attention 通常更耗显存。
然而,有弊也有利,更大的空间占用也意味着拥有了更多的可能性,我们可以通过往这个级别的 Attention 矩阵加入各种先验约束,使得它可以做更灵活的任务。说白了,也就只有纯 Attention 的模型,才有那么大的“容量”去承载那么多的“花样”。
而加入先验约束的方式,就是对 Attention 矩阵进行不同形式的 Mask,这便是本文要关注的焦点。
分析
在一文读懂「Attention is All You Need」| 附代码实现一文中笔者已经对 Attention 做了基本介绍,这里仅做简单回顾。Attention 的数学形式为:
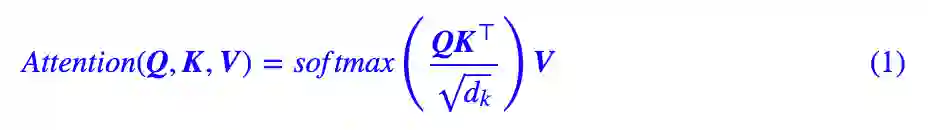
这里的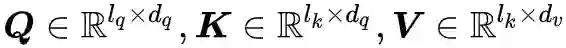
则是将 query、key 的向量两两做内积,然后用 softmax 归一化,就得到一个
的 Attention 矩阵,它描述的就是 query 和 key 之间任意两个元素的关联强度,后面我们要讲的故事,都是在这个 Attention 矩阵上下功夫。最后再与 V 相乘,相当于按照这个关联强度将 V 的各个向量加权求和,最终输出一个
的向量序列。
目前最常用的 Attention 方式当数 Self Attention,即 Q, K, V 都是同一个向量序列经过线性变换而来的,而 Transformer 则是 Self Attention 跟 Position-Wise 全连接层(相当于 kernel size 为 1 的一维卷积)的组合。所以,Transformer 就是基于 Attention 的向量序列到向量序列的变换。
在本节中,我们将会比较详细地分析 Attention 矩阵的 Mask 方式,这分别对应单向语言模型、乱序语言模型、Seq2Seq 的实现原理。
单向语言模型
语言模型可以说是一个无条件的文本生成模型,如果读者还不了解文本生成模型,可以自行查阅相关资料并配合玩转Keras之Seq2Seq自动生成标题 | 附开源代码一文来理解。单向语言模型相当于把训练语料通过下述条件概率分布的方式“记住”了:
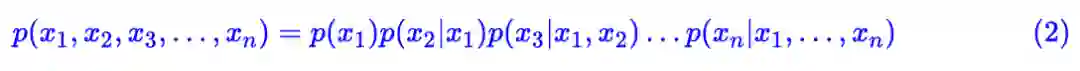
我们一般说的“语言模型”,就是指单向的(更狭义的只是指正向的)语言模型。语言模型的关键点是要防止看到“未来信息”。如上式,预测 x1 的时候,是没有任何外部输入的;而预测 x2 的时候,只能输入 x1,预测 x3 的时候,只能输入 x1,x2;依此类推。
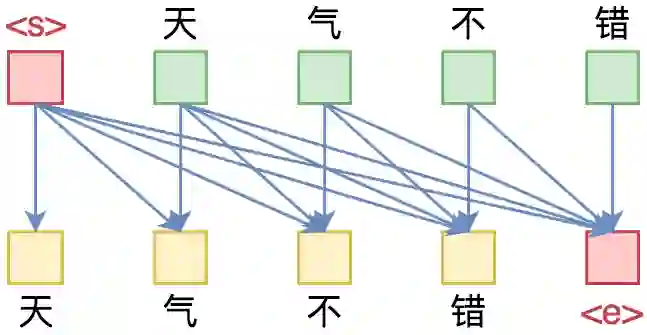
RNN 模型是天然适合做语言模型的,因为它本身就是递归的运算;如果用 CNN 来做的话,则需要对卷积核进行 Mask,即需要将卷积核对应右边的部分置零。如果是 Transformer 呢?那需要一个下三角矩阵形式的 Attention 矩阵:
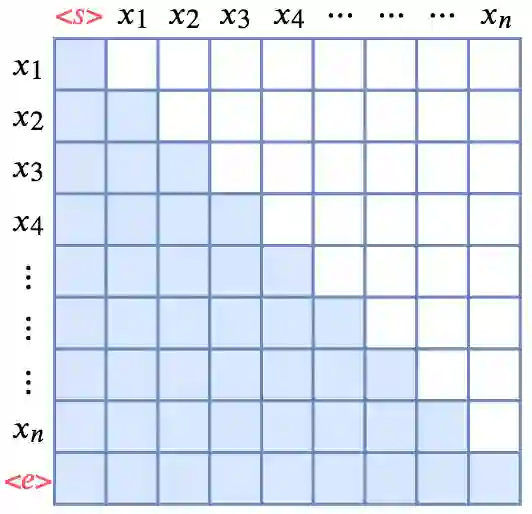
▲ 单向(正向)语言模型的Mask方式
如图所示,Attention 矩阵的每一行事实上代表着输出,而每一列代表着输入,而 Attention 矩阵就表示输出和输入的关联。假定白色方格都代表 0,那么第 1 行表示“北”只能跟起始标记 <s> 相关了,而第 2 行就表示“京”只能跟起始标记 <s> 和“北”相关了,依此类推。
所以,只需要在 Transformer 的 Attention 矩阵中引入下三角形形式的 Mask,并将输入输出错开一位训练,就可以实现单向语言模型了。至于 Mask 的实现方式,可以参考“让Keras更酷一些!”:层中层与mask的 Mask 一节。
乱序语言模型
乱序语言模型是 XLNet 提出来的概念,它主要用于 XLNet 的预训练上。说到 XLNet,我觉得它的乱序语言模型这种预训练方式是很有意思的,但是我并不喜欢它将基本架构换成了 Transformer-XL。我觉得谁有资源可以试试“BERT+乱序语言语言模型预训练”的组合,或许会有意外的发现。
乱序语言模型跟语言模型一样,都是做条件概率分解,但是乱序语言模型的分解顺序是随机的:
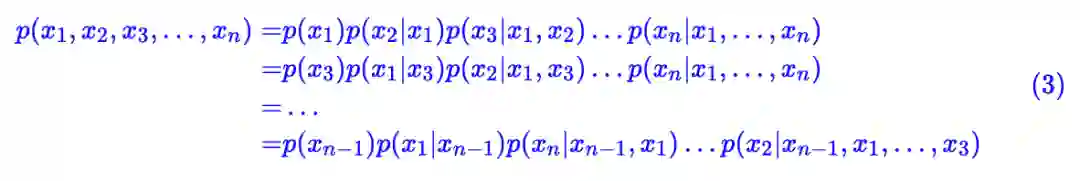
总之, x1, x2, … , xn 任意一种“出场顺序”都有可能。原则上来说,每一种顺序都对应着一个模型,所以原则上就有 n! 个语言模型。而基于 Transformer 的模型,则可以将这所有顺序都做到一个模型中去!
那怎么做到这一点呢?还是以“北京欢迎你”的生成为例,假设随机的一种生成顺序为“<s> → 迎 → 京 → 你 → 欢 → 北 → <e>”,那么我们只需要用下图中第二个子图的方式去 Mask 掉 Attention 矩阵,就可以达到目的了:
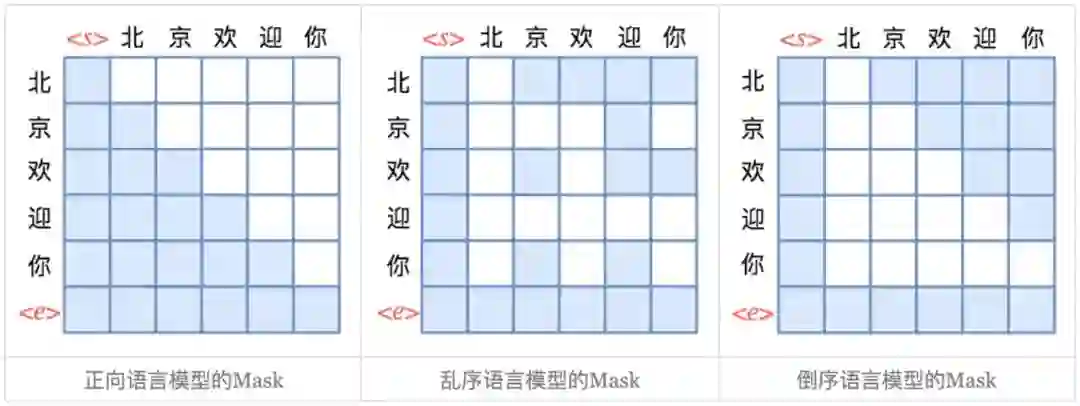
跟前面的单向语言模型类似,第 4 行只有一个蓝色格,表示“迎”只能跟起始标记 <s> 相关,而第 2 行有两个蓝色格,表示“京”只能跟起始标记 <s> 和“迎”相关,依此类推。直观来看,这就像是把单向语言模型的下三角形式的 Mask“打乱”了。
也就是说,实现一种顺序的语言模型,就相当于将原来的下三角形式的 Mask 以某种方式打乱。正因为 Attention 提供了这样的一个 n × n 的 Attention 矩阵,我们才有足够多的自由度去以不同的方式去 Mask 这个矩阵,从而实现多样化的效果。
说到这里,读者可能会有一个实现上的疑问:打乱后的 Mask 似乎没看出什么规律呀,难道每次都要随机生成一个这样的似乎没有什么明显概率的 Mask 矩阵?
事实上有一种更简单的、数学上等效的训练方案。这个训练方案源于纯 Attention 的模型本质上是一个无序的模型,它里边的词序实际上是通过 Position Embedding 加上去的。也就是说,我们输入的不仅只有 token 本身,还包括 token 所在的位置 id;再换言之,你觉得你是输入了序列“[北, 京, 欢, 迎, 你]”,实际上你输入的是集合“{(北, 1), (京, 2), (欢, 3), (迎, 4), (你, 5)}”。
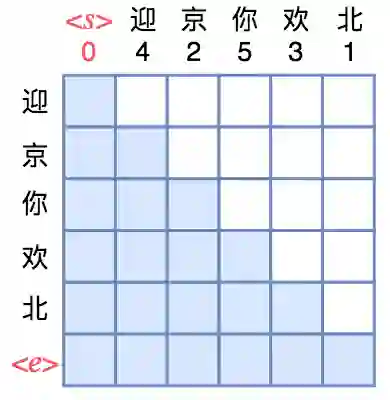
▲ 重新排序,使得正向语言模型就可以实现乱序语言模型
既然只是一个集合,跟顺序无关,那么我们完全可以换一种顺序输入,比如刚才的“<s> → 迎 → 京 → 你 → 欢 → 北 → <e>”,我们可以按“(迎, 4), (京, 2), (你, 5), (欢, 3), (北, 1)”的顺序输入,也就是说将 token 打乱为“迎,京,你,欢,北”输入到 Transformer 中,但是第 1 个 token 的 position 就不是 1 了,而是 4;依此类推。这样换过来之后,Mask 矩阵可以恢复为下三角矩阵,所以只需要在输入层面打乱即可,这样操作起来就更简单了。
Seq2Seq
现在到我们的“重头戏”了:将 BERT 等 Transformer 架构跟 Seq2Seq 结合起来。为什么说重头戏呢?因为原则上来说,任何 NLP 问题都可以转化为 Seq2Seq 来做,它是一个真正意义上的万能模型。所以如果能够做到 Seq2Seq,理论上就可以实现任意任务了。
将 BERT 与 Seq2Seq 结合的比较知名的工作有两个:MASS [6] 和 UNILM [5],两者都是微软的工作,两者还都在同一个月发的。其中 MASS 还是普通的 Seq2Seq 架构,分别用 BERT 类似的 Transformer 模型来做 encoder 和 decoder,它的主要贡献就是提供了一种 Seq2Seq 思想的预训练方案。
真正有意思的是 UNILM,它提供了一种很优雅的方式,能够让我们直接用单个 BERT 模型就可以做 Seq2Seq 任务,而不用区分 encoder 和 decoder。而实现这一点几乎不费吹灰之力——只需要一个特别的 Mask。
插曲:事实的顺序是笔者前两周自己独立地想到了用单个 BERT 模型做 Seq2Seq 的思路,然后去找资料发现这个思路已经被做了,正是 UNILM。
UNILM 直接将 Seq2Seq 当成句子补全来做。假如输入是“你想吃啥”,目标句子是“白切鸡”,那 UNILM 将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP]。经过这样转化之后,最简单的方案就是训练一个语言模型,然后输入“[CLS] 你 想 吃 啥 [SEP]”来逐字预测“白 切 鸡”,直到出现“[SEP]”为止,即如下面的左图:
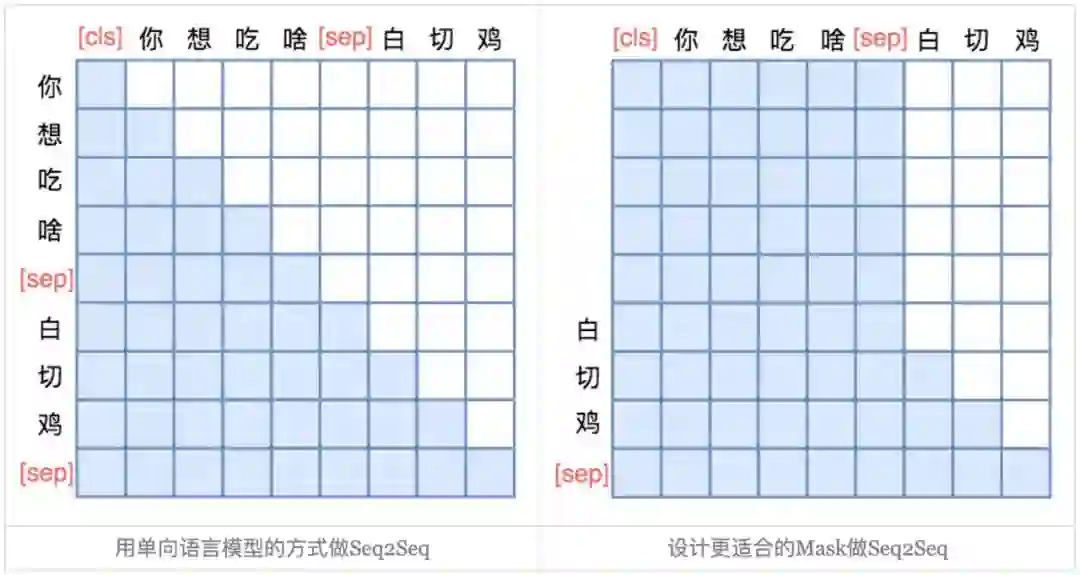
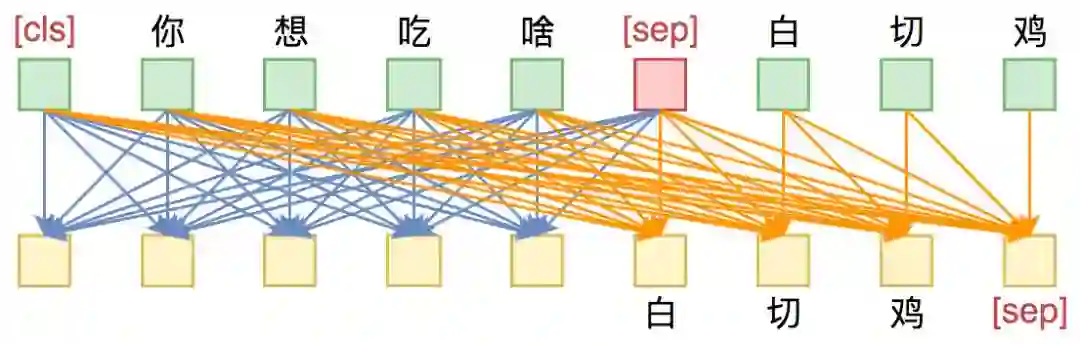
▲ UNILM做Seq2Seq模型图示。输入部分内部可做双向Attention,输出部分只做单向Attention。
实验
事实上,上述的这些 Mask 方案,基本上都已经被集成在笔者写的 bert4keras [7],读者可以直接用 bert4keras 加载 BERT 的预训练权重,并且调用上述 Mask 方案来做相应的任务。下面,我们给出一个利用 UNILM 的思路做一个快速收敛的 Seq2Seq 模型的例子。
代码开源
这次代码的测试任务依然是之前的标题生成,代码调整自玩转Keras之Seq2Seq自动生成标题里边的代码,并且得益于 bert4keras 的封装,模型部分的代码实现非常简单清爽。这一次直接使用了 THUCNews [8] 的原始数据集,读者可以自行下载数据集和源码测试复现。
详细请看:
这个效果能有多好呢?经过实验,在标题生成的任务上,只要 7000 个 iteration,就已经能生成基本可读的标题了。相应地,以前用 LSTM 做的时候,大概需要多 10 倍的 iteration 才有同样的效果。

▲ 只需要7000步的训练,就可以得到基本可读的生成结果
简单说明
下面对代码的关键部分做简要说明。
首先,输入格式还是以 token_id 和 segment_id 输入,比如:
tokens = ['[ClS]', u'你', u'想', u'吃', u'啥', '[SEP]', u'白', u'切', u'鸡', '[SEP]']
token_ids = [token_dict[t] for t in tokens]
segment_ids = [0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
segment_ids 用来区分输入句子和目标句子,0 对应的为输入句子,1 对应的为目标句子,只需要自带的 tokenizer.encode 就可以生成这种 token_id 和 segment_id 了。
至于搭建模型,就只有寥寥几行:
model = load_pretrained_model(
config_path,
checkpoint_path,
seq2seq=True,
keep_words=keep_words
)
model.summary()
y_in = model.input[0][:, 1:] # 目标tokens
y_mask = model.input[1][:, 1:]
y = model.output[:, :-1] # 预测tokens,预测与目标错开一位
# 交叉熵作为loss,并mask掉输入部分的预测
y = model.output[:, :-1] # 预测tokens,预测与目标错开一位
cross_entropy = K.sparse_categorical_crossentropy(y_in, y)
cross_entropy = K.sum(cross_entropy * y_mask) / K.sum(y_mask)
注意 load_pretrained_model 中只要设置 seq2seq=True,就会自动加载 BERT 的 MLM 部分,并且传入对应的 Mask,剩下就只需要把 loss 写好就行了。另外还有一个 keep_words,这个是用来精简 Embedding 层用的,对于中文 BERT 来说,总的 tokens 大概有 2 万个,这意味着最后预测生成的 token 时是一个 2 万分类问题。
但事实上这大多数 tokens 都不会被使用到,因此这 2 万分类浪费了不少计算量。于是这里提供了一个选项,我们可以自行统计一个字表,然后传入对应的 id,只保留这部分 token,这样就可以降低计算量了(精简后一般只有 5000 个左右)。
剩下的就是通过 beam search 来解码等步骤了,这与一般的 Seq2Seq 无异,不再赘述,大家看玩转Keras之Seq2Seq自动生成标题和代码即可。
总结
本文相对系统地总结了 Transformer 中 Attention 矩阵的 Mask 技巧,并且给出了用 UNILM 方案来做 Seq2Seq 的实现。对于同语言的 Seq2Seq 的文本生成任务来说,采用 UNILM 的思路加载 BERT 的 MLM 预训练权重,能够有效、快速地实现并提升生成效果,值得一试。
相关链接

点击以下标题查看作者其他文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客



