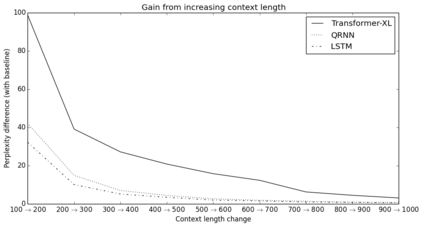
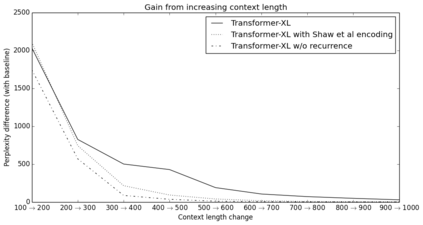
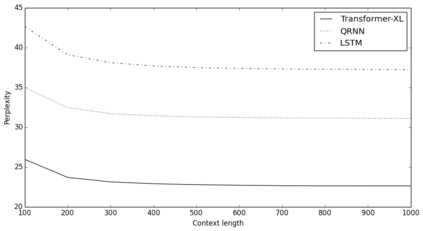
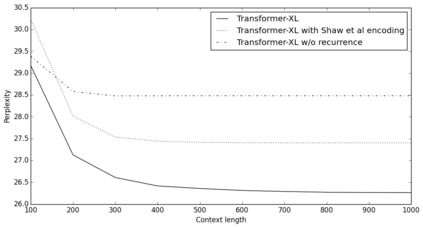
Transformer networks have a potential of learning longer-term dependency, but are limited by a fixed-length context in the setting of language modeling. As a solution, we propose a novel neural architecture, \textit{Transformer-XL}, that enables Transformer to learn dependency beyond a fixed length without disrupting temporal coherence. Concretely, it consists of a segment-level recurrence mechanism and a novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the problem of context fragmentation. As a result, Transformer-XL learns dependency that is about 80\% longer than RNNs and 450\% longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+ times faster than vanilla Transformer during evaluation. Additionally, we improve the state-of-the-art (SoTA) results of bpc/perplexity from 1.06 to 0.99 on enwiki8, from 1.13 to 1.08 on text8, from 20.5 to 18.3 on WikiText-103, from 23.7 to 21.8 on One Billion Word, and from 55.3 to 54.5 on Penn Treebank (without finetuning). Our code, pretrained models, and hyperparameters are available in both Tensorflow and PyTorch.
翻译:变换器网络具有学习长期依赖性的潜力,但受语言模型设置中固定长度背景的限制。作为一个解决方案,我们提议了一个新的神经结构,\textit{transfred-XL},使变换器能够在不扰乱时间一致性的情况下学习超过固定长度的依赖性。具体地说,它包括一个分级重现机制和一个新的定位编码计划。我们的方法不仅能够捕捉长期依赖性,而且还解决了背景分裂问题。因此,变换器-XL学会了比RNN和香草变换器长约80 ⁇ 年长,450 ⁇ 长约80 ⁇ 。作为一个解决方案,我们提出了一个新的神经结构,使变换器能够在不破坏时间一致性的情况下学习超过固定长度的对依赖性。具体地说,它包括一个分级重现机制和一个新的定位编码系统。我们的方法不仅能够捕捉到长期依赖性,而且还解决了背景变形问题。 因此,变换器-XL学会学习了比RNNN约长80 ⁇ 长,比香草变换器长450 ⁇ 长450 ⁇ 长,在短序和长的顺序上都达到更好的性工作,在短的成绩上都比Vanilla变形变换器变换器变换速度快1800+1800倍。此外比Van3比VWWe,从55.3到TWe,还有5号,从5号,从5到Tirmas,从5号,还有5号,从5号,从5号,从5号,从5号,从5号,从5号到Tirmax103.,从5号,从5号,从5号,从5号,从5号到Tirmas,从5号,从5号,从5号,从5号到1039到1039,从5号,从5号,从5号,从5号,从5号,从5号,从5号,从5号,从5号,到10,到10,到10号,从5号,从5号,从5号到1039,从5号,从5号,从5号,到10号,到10号,从5号,从5号,到10号,从5号,到10号,从5号,从5号,到10号,从