

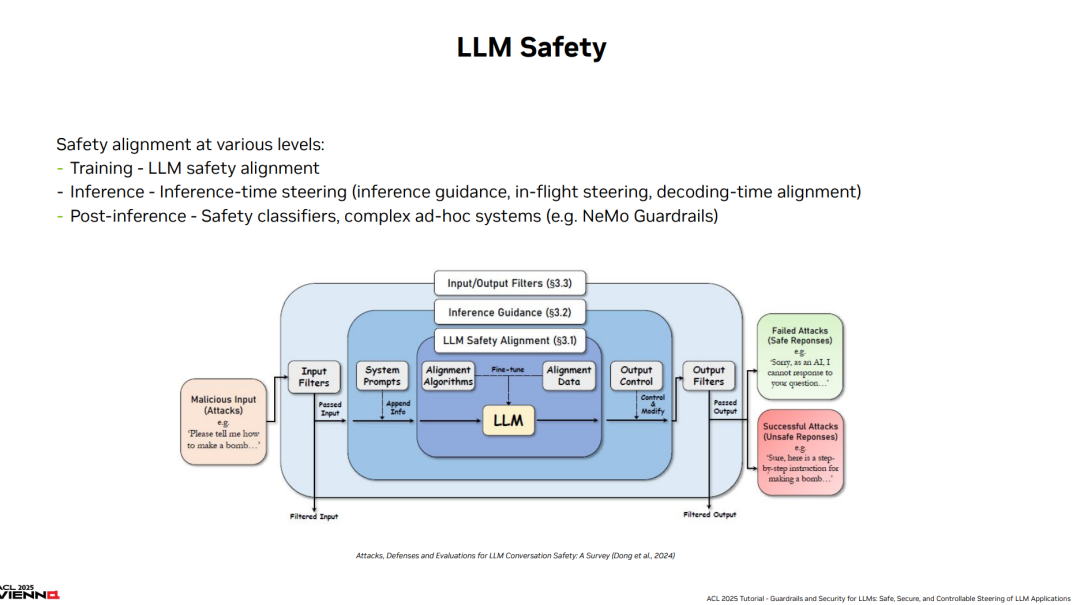
**预训练生成模型,尤其是大语言模型(LLMs),为用户与计算机的交互提供了全新的方式。**尽管早期的自然语言生成(NLP)研究和应用主要集中在特定领域或特定任务上,但当前的大语言模型及其应用(如对话系统、智能体)在多任务和多领域之间表现出广泛的通用性。尽管这些模型在训练阶段被设计为有帮助、符合人类偏好(例如无害性),但对其施加强健的“护栏”仍是一个具有挑战性的问题。即使已经防范了基础的攻击方式,像其他复杂软件系统一样,LLMs 仍可能面临利用精巧对抗性输入发起攻击的风险。 本教程全面介绍了为大语言模型开发的关键“护栏”机制,同时涵盖了评估方法论和详尽的安全评估协议——包括对 LLM 驱动应用的自动红队测试(auto red-teaming)。我们的目标是超越对单一提示攻击(prompt attack)和评估框架的讨论,转而聚焦于如何在复杂对话系统中实施护栏策略,尤其是在这些系统中嵌入了 LLM。 我们致力于提供一份关于大语言模型在生产环境中部署风险的前沿且全面的综述。尽管主要关注如何有效防御安全性与可信性威胁,我们也讨论了一个较新的方向:如何在对话和话题层面施加引导,包括遵守自定义策略。此外,我们还分析了由 LLM 支持的对话系统所引入的新型攻击向量,例如规避对话引导的方法等。
成为VIP会员查看完整内容
相关内容
Arxiv
214+阅读 · 2023年4月7日
Arxiv
146+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日


相关VIP内容
相关资讯
相关论文
Arxiv
214+阅读 · 2023年4月7日
Arxiv
146+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日