基础 | 基于注意力机制的seq2seq网络
作者:黑龙江大学nlp实验室本科生甄冉冉
Seq2seq
seq2seq的用途有很多,比如机器翻译,写诗,作曲,看图写文字等等用途很广泛!该模型最早在2014年被Cho和Sutskever先后提出,前者将该模型命名为“Encoder-Decoder Model”也就是编码-解码模型,后者将其命名为“Sequence to Sequence Model”也就是序列到序列模型,两者有一些细节上的差异,但总体大致思想基本相同。
seq2seq根据字面意思来看就是序列到序列,再具体点就是输入一个序列(可以是一句话,一个图片等)输出另一个序列。这里以RNN为基础的机器翻译为例,介绍seq2seq和attention注意力机制。(seq2seq实现的方法有很多,比如MLP,CNN,RNN等)
这是机器翻译的部分数据 (法语->英语):

我们先了解下机器翻译的大致流程:
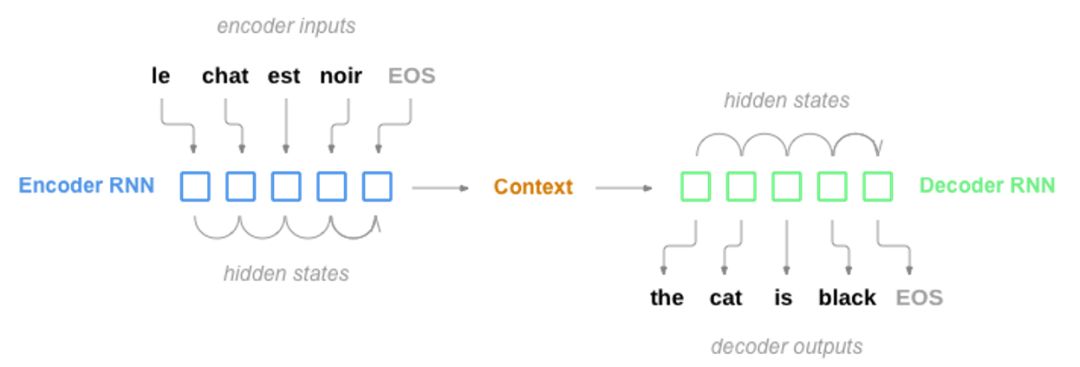
大致意思就是根据输入的文本,神经网络开始学习和记忆,这个就是所谓的Encoder编码过程;然后根据自己的记忆,把文本一一翻译出来,这个就是所谓的Decoder解码过程。
现在再让我们更进一步了解seq2seq的具体流程:
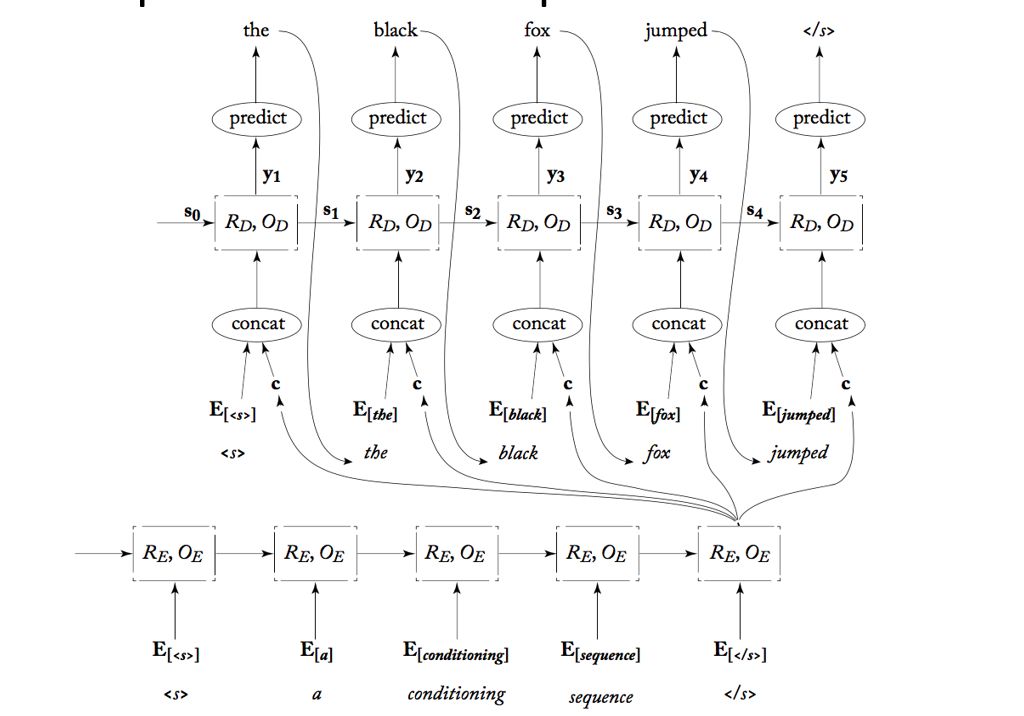
我来一一讲解这张图的每一个细节:
所以需要传到个个Decoder中。
下面这个是Decoder的核心过程,拿一次预测举例子:
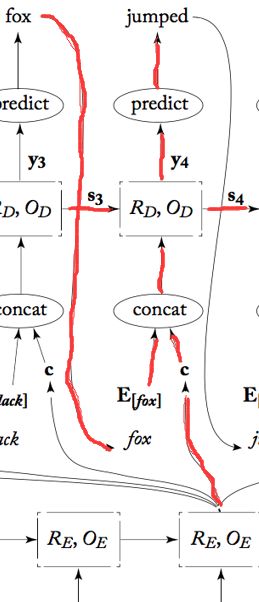
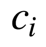
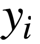
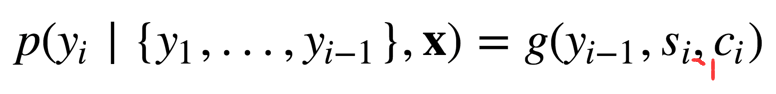
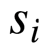
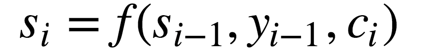
这是简单的理论部分,看看这个实践图吧:
Encoder
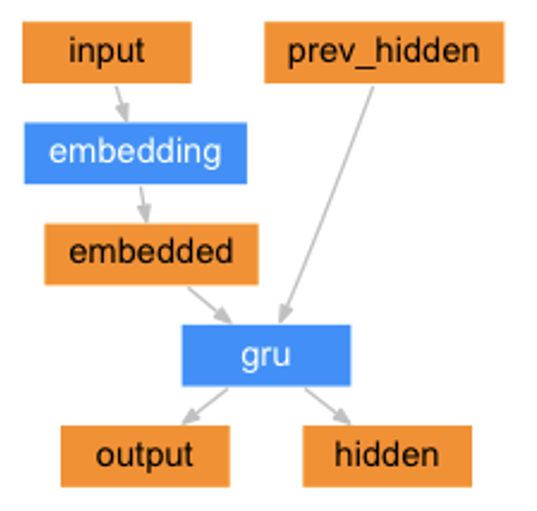
Decoder
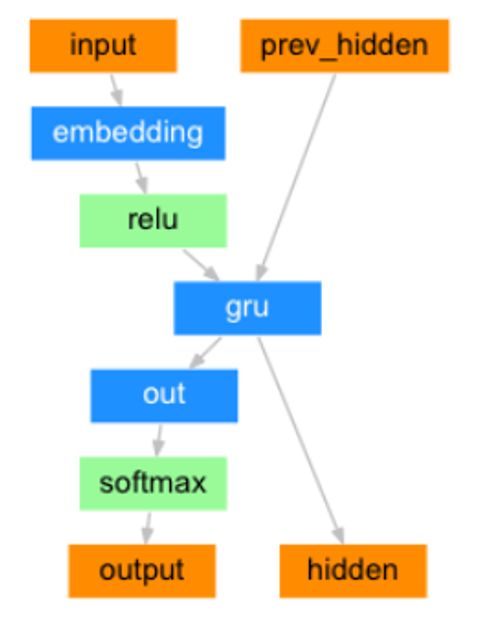
虽然这个model是GRU,但不光是GRU,LSTM等都可以。
seq2seq就这样讲完了。下面该到注意力机制登上历史舞台!
Attention Mechanism 注意力机制
从字面意思我们能联想到自己的注意力吧。对,就是这样的。每当我们专注学习时,我们的目光会聚焦在正在学的东西上,但是我们眼前不能专注的也不是啥也看不见,仅仅是模糊而已。转移到数学分析下,就是我们专注的占得我们经历的大部分,比如给个数值0.8(满分为1),其他的模糊情景为0.01,0.03,0.07。。。总和为0.2。这个注意力机制就是这样的!在机器翻译中,我们需要一个词一个词的翻译,当我们翻译某个词的时候,我们主要是需要这个词,而其他的词信息用的就是很少了,所以就是说网络把精力大部分放到了将要翻译的这个词了,但是其他也得照顾到,因为翻译一个词需要上下文的意思,比如单复数的写法就需要上下文吧。你看,这个是不是和人的注意力差不多啊。这个也可以从我们生活经常做的例子来说就是你看着手机走路,你的注意力在手机上,但是你也能走路,而且还能避开各种人群(当然,撞树啥的只能怪你给手机分配的注意力太大了QAQ)。
看一下基本的流程图:
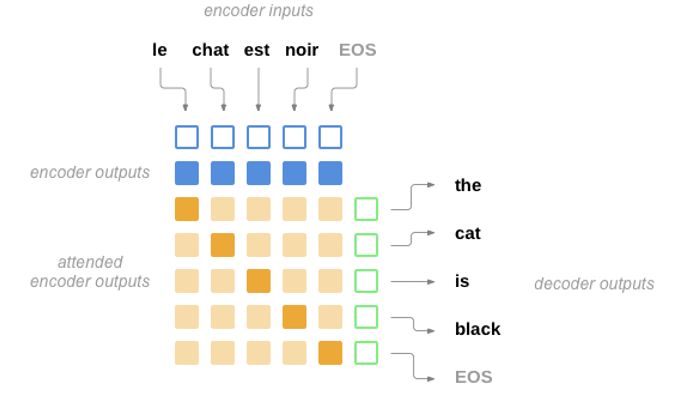
这些黄色的深浅代表当翻译每个词的注意力的分配。
具体网络分布图为:
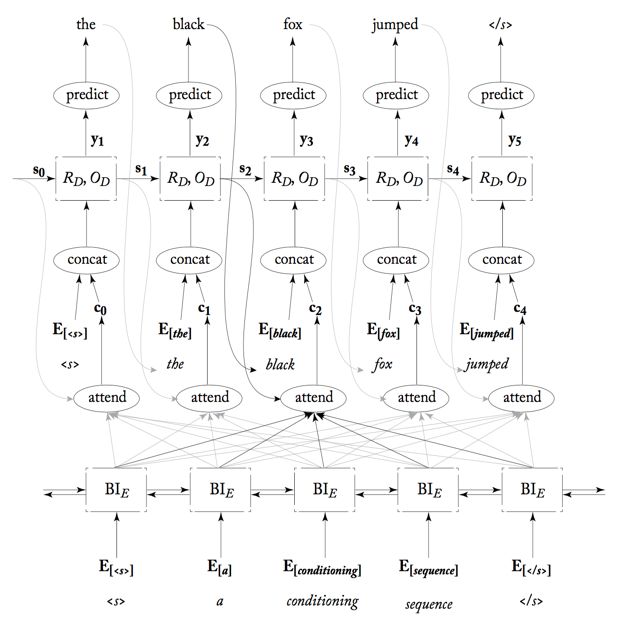
再具体下,以这个例子为例:
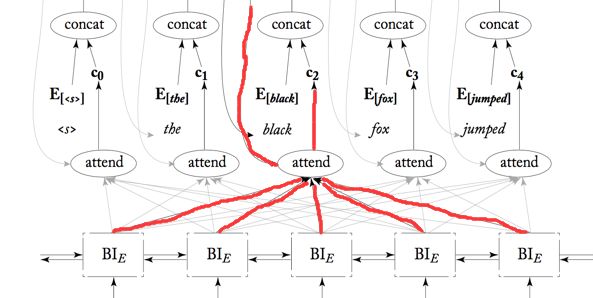
Encoder用的是是双向RNN,当RNN单元循环回来的时候都会有一个输出给了你将要翻译的词对应的attend,而此时肯定是它的最下方的词应该是注意力最集中的,所以它对应的权重肯定是最大的。
这里的权重分配公式为:
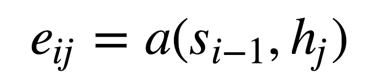
从最上面下来的是
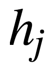
所有的分打出来后,要做下归一化:
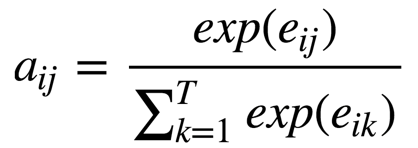
这个跟Softmax差不多。
然后对他们进行求和传送给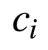
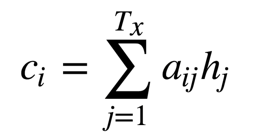
这个注意力机制大大提高了机器翻译的能力当然也包括其他的领域。
这次讲完了,你可以休息下消化消化,有问题的随时提问,我们一起进步!
感谢实验室宋阳师姐的讲解以及上面的图来自哈工大社会检索讨论班。

推荐关注甄冉冉同学自己的公众号-深度学习自然语言处理,冉冉同学在公众号里分享了自己学习路上的一点一滴,想要入门自然语言处理的童鞋,可以和他一起哦!






