阅读理解得分超越人类:谷歌推出最强预训练语言理解模型BERT

点击图片查看详情↑
近日,谷歌提出了一个新的预训练语言模型 BERT,该模型横扫 11 项不同的自然语言处理任务,并在 SQuAD v1.1 的阅读理解任务上超越人类两个百分点。
该模型究竟有哪些创新?有为什么会有如此突出的效果呢?这一切需要从语言模型讲起。
语言模型 (Language Model) 通过在大规模数据上完成特定的任务来建立,在自然语言处理领域拥有里程碑式的地位。在之前的工作中,其在训练过程中设定的任务一般是给定文本中已出现词语,预测下一个单词。这可以算是最简单的语言处理任务,但通过针对这一目标的训练,模型可以把握词语的含义等语言特性。
语言模型的建立是一种无监督学习,因此可以利用现实世界大规模无标注的语料数据。尽管其概念十分简单,但却与其后自然语言处理领域的许多重要进展息息相关,例如词向量、序列到序列的学习。
目前,语言模型在自然语言处理领域的重要应用方向是,通过迁移学习与特定的任务结合。即首先在大规模语料上预训练语言模型,再在其基础上根据具体任务进行进一步处理。结合方式主要有两种:第一种是 feature-based,也就是利用预训练的语言模型获得特征向量,将其用于具体任务。第二种则是 fine-tuning,在预训练的语言模型基础上稍作改变,根据具体任务引入新的结构和参数,再次进行训练。通过与预训练语言模型的结合,许多原有的模型在任务上的效果进一步提升。这其实很好理解——以阅读理解为例,人类在做一道阅读理解题目时,并不仅仅从这一篇文章,以及类似的阅读理解任务(训练集)中学习,而是会使用在此之前积累的各项知识。大规模语料预训练的语言模型正提供了这种知识的积累。
BERT 也是一个语言模型,其基本结构由多层的双向 Transformer 组成。Transformer 是谷歌 2017 年发表的的著名论文《Attention is all you need》中提出的架构,在机器翻译任务上取得了非常好的效果。Transformer 舍弃了以往该任务上常用的 CNN、RNN 等神经网络结构,利用自注意力机制将文本中的上下文内容联系起来,并行处理序列中的单词符号。这样的结构使训练速度显著提升,效果也更为优秀。目前这一结构已经被广泛应用。
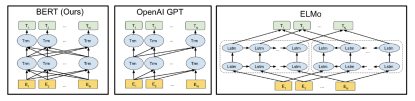
图 | 预训练语言模型间的差异 BERT 的 Transformer 使用了双向的自注意力机制(self-attention),OpenAI GPT 使用的是由左到右的 Transformer。ELMo 则使用了两个不同方向的 LSTM,将其输出结果拼接在一起。(来源:arXiv)
BERT 中,每个 token 的输入向量由三部部分组成:token embeddings、segment embeddings、position embeddings,如下图所示。
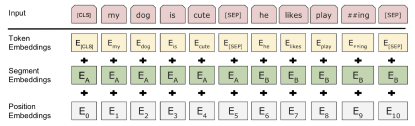
图 | BERT 输入的表示(来源:arXiv)
其中,token embeddings(上图中黄色部分)表示 token 的含义;segment embeddings 表示 token 所属的部分(上图中绿色部分。每个词语属于 A 或 B);position embeddings 表示 token 在序列中所处的位置(上图中灰白色部分)。[CLS] 标志序列的开始,在分类任务中具有重要的作用。[SEP] 出现在句子末尾,用来标注序列中不同的句子。
这样特别的输入与 BERT 的训练目标有关,与以往语言模型不同的训练目标也正是其强大性能的来源。BERT 设立了两个训练目标:MLM(Masked Language Model,马赛克语言模型)和预测下一个句子。
Task1——Masked Language Model
之前提出的语言模型在预测单词时大多是单向的,即依次通过左侧(右侧)出现的词语预测下一个词语。这样的逐个对词语进行预测无法双向进行,否则模型就可以“看到答案”。但我们知道,对语言的理解不应仅仅是单向的,一个词语的含义与其之前和之后出现的词语都紧密相关。为了达到双向理解的目的,BERT 随机为句子中的一些词语打上马赛克,用 [MASK] 进行替换,在训练的过程中对这些被遮盖的词语进行预测。在本论文中,研究人员随机遮盖了 15% 的词语。
不过,这样的做法又会带来一些问题,因为这些被遮盖的词语相当于从数据集中被抹去,再也不会出现了。为了解决这一问题,研究人员又对这些随机抽取的词语进行了三种不同的处理:
80% 的情况下用 [MASK] 替换:my dog is hairy——> my dog is [MASK]
10% 的情况下,使用其他词语随机替换:my dog is hairy——> my dog is apple
10% 的情况下保持不变:my dog is hairy——> my dog is hairy 这也可以保证模型预测的结果偏向正确结果。
Task2——Next Sentence Prediction
问答和自然语言推理任务都需要理解句子之间的关系,而这无法由语言模型直接建模。为此,研究人员引入了二值任务:预测下一个句子。

图 | Next Sentence Prediction(来源:arXiv)
每个输入序列中包含不同的句子 A 与 B。在 50% 的数据中,B 为 A 的下一个句子,另外 50% 的数据中句子 B 不是 A 的下一个句子,而是从文本中随机抽取的。训练的过程中,模型对标签进行预测,从而对句子之间的关系建模。训练后模型判断的准确性达到 97%-98%。
BERT 在 BooksCorpus 和英文维基百科组成的大规模语料上进行预训练。预训练后,模型通过 fine-tuning 的方式与具体任务结合,在 11 个自然语言处理任务上超越了之前的最佳结果。
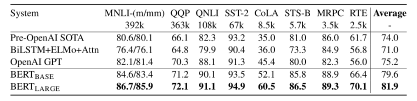
图 | GLUE 测试结果,由 GLUE evaluation server 评测(来源:arXiv)
GLUE(General Language Understanding Evaluation)是一系列自然语言处理任务的集合。其中包含的数据集大多已经存在多年,而 GLUE 将其划分为训练集、测试集和验证集,并建立了测评服务以缓解测评机制不一致和测试集的过拟合问题。GLUE 不公布测试集答案,使用者需要提交自己的预测结果进行测评。如下图所示,BERT 在 GLUE 的各项任务上均取得了最佳结果。而图中显示的仅仅是 BERT 在单个任务上进行训练的结果。若模型进行多任务的联合训练,效果还会进一步提升。
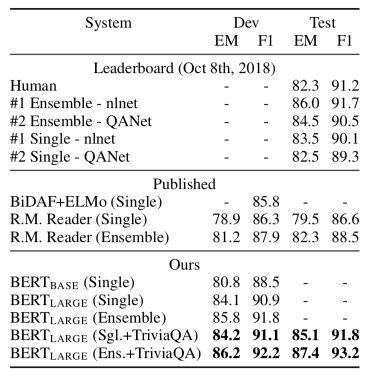
图 | BERT 在 SQuAD v1.1 上的实验结果(来源:arXiv)
SQuAD v1.1 是斯坦福公开的阅读理解问答数据集。该数据集上的任务为,给定一段文本和一个问题,需要从文本中摘取一个片段作为问题的答案。在这一任务上,BERT 不仅超越了之前提交的各个模型的最好成绩,其 F1 值更比人类的表现高出两个百分点。
除此之外,BERT 还在命名实体识别等任务上取得了更好的结果。BERT 在各项任务上的应用也不仅仅局限于 fine-tuning 的方式,还可以通过 feature-based 的方式结合。谷歌将在 10 底前公开模型的训练代码和预训练模型。
虽然 BERT 已经在多项任务上展现了其强大的威力,但未来仍需更多工作进行进一步探索。它究竟把握住了语言中的哪些特性?又遗漏了什么?这些问题的研究将帮助我们完善这一语言模型,推进对语言更深层次的理解。
-End-
编辑:维尼 责编:戴青
参考:https://arxiv.org/abs/1810.04805