进一步改进GPT和BERT:使用Transformer的语言模型
选自 arXiv
作者:Chenguang Wang、Mu Li、Alexander J. Smola
机器之心编译
参与:Panda
BERT 和 GPT-2 是当前 NLP 领域两大最先进的模型,它们都采用了基于 Transformer 的架构。Amazon Web Services 近期一篇论文提出了一些对 Transformer 的新改进,包括架构上的改进、利用先验知识以及一种新的架构搜索方法,能得到更加高效的语言模型。

Transformer 在计算效率方面优于基于 RNN 的模型。近期的 GPT 和 BERT已经表明,使用在大规模语料库上预训练的语言模型时,Transformer 能高效地处理多种 NLP 任务。让人惊讶的是,这些 Transformer 架构对于语言模型本身而言是次优的。在 Transformer 中,不管是自注意(self-attention)还是位置编码(positional encoding),都无法整合对语言建模而言至关重要的词级序列上下文(sequential context)。
本论文探索了用于语言模型的高效 Transformer 架构,包括添加额外的 LSTM 层以在保持计算高效的同时获取序列上下文。我们提出了协调式架构搜索(CAS:Coordinate Architecture Search),可通过模型的迭代式优化来寻找高效的架构。在 PTB、WikiText-2 和 WikiText-103 上的实验结果表明 CAS 能在所有问题上实现在 20.42 与 34.11 之间的困惑度,即相比于之前最佳的 LSTM 方法,困惑度平均能提升 12.0。
引言
建模语言中的序列上下文是很多 NLP 任务成功的关键。循环神经网络(RNN)可以将序列上下文记忆在精心设计的单元中。但是,这些模型的序列性使得其计算成本高昂,由此难以扩展用于大型语料库。
Transformer 架构使用了自注意和逐点全连接层替代 RNN 单元;这种层是高度可并行化的,因此计算成本更低。搭配上位置编码,Transformer 能通过模糊的相对 token 位置求取长程依赖性。这会得到句子级的粗粒度序列表征。GPT(或 GPT2)和 BERT 等近期研究成果表明在大规模语言建模数据集上学习到的表征既可以有效用于优化句子级任务(比如 GLUE 基准),也能用于优化不依靠上下文中词序依赖性的 token 级任务(比如问答和命名实体识别)。
尽管事实上 GPT 和 BERT 都使用了语言模型来预训练,但它们在语言建模方面都没有实现当前最佳。语言模型的目标是根据之前的上文预测下一个词,这需要细粒度的上下文词序信息。已有的 Transformer 架构中的自注意和位置编码都不能有效地建模这种信息。
第二个挑战(和机会)源自这一事实:我们往往有机会获取在相关但不完全相同的任务上预训练的模型。举个例子,GPT 或 BERT 都没有针对 WikiText 进行调整,也没有直接以最小化困惑度为目标。事实上,这些架构甚至可能没有直接的用处:BERT 提供的是 p(w_i |context) 而非 p(w_i |history) 的估计。这表明,对于可以从这些任务导出(和适应得到)的网络空间,我们需要设计能系统性地探索它们的算法。这能泛化为相关任务使用预训练词嵌入的问题,只是我们这里不是处理向量,而是整个网络
最后,架构搜索问题本身已经受到了很大的关注。但是,为 GPT 或 BERT 训练单个模型所需大小的数据集的成本可能超过 1 万美元,如果要通过完全重新训练来执行完备的模型探索,成本将高得不切实际。相对而言,我们提出以远远更加受限(和经济)的方式来调研如何优化一个经过训练的架构,进而实现架构搜索。这样的成本要低得多。我们务实的方法能提升语言建模问题的当前最佳表现。我们有如下贡献:
我们提出了一种用于语言模型的 Transformer 架构。在所有 Transformer 模块之后添加 LSTM 层是有效的(这是搜索算法的一个结果)。这能获得细粒度的词级序列上下文。
我们描述了一种高效的搜索流程:协调式架构搜索(CAS)。这种算法能基于已找到的当前最佳架构随机地生成 Transformer 架构的变体。由于这种贪婪性质,CAS 比之前的架构搜索算法更简单且速度更快。
我们以 GPT 或 BERT 的形式展示了如何将其用于整合大量先验知识。而使用暴力式架构搜索获取这些信息的成本会非常高。
其中贡献 2 和 3 是通用的,可用于 NLP 领域外的其它很多情况。贡献 1 应该更特定于语言方面。我们在 PTB、WikiText-2 和 WikiText-103 这三个常用语言模型数据集上评估了 CAS。相比于当前最佳的基于 LSTM 的语言模型 AWD-LSTM-MoS,基于 BERT 的 CAS 在困惑度方面实现了平均 12.0 的增益。
用于语言模型的 Transformer
我们的 Transformer 架构基于 GPT 和 BERT。我们将复用在 GPT 和 BERT 中预训练的权重来优化语言模型。我们会修改和再训练 GPT 和 BERT 使用的权重和网络以适应语言模型任务。
GPT 和 BERT
GPT 使用了 Transformer 架构的一种变体,即它使用了基于多层 Transformer 解码器的语言模型。其原论文提供了一种预训练的架构,其模块仅有 12 层的 Transformer 解码器。每个模块都有 768 的隐藏大小和 12 个自注意头。权重是在 BooksCorpus 上训练的。这使其可生成 p(wi |history),一次一个词。
BERT 是一种多层双向 Transformer 编码器。其原论文提供了两种 BERT 结构:BERT-Base 和 BERT-Large。其中 BERT-Base 由 12 层双向 Transformer 编码器模块构成,有 768 的隐藏大小和 12 个自注意头。BERT-Large 包含 24 层双向 Transformer 编码器模块,隐藏大小为 1024,有 16 个自注意头。其权重是在 BooksCorpus 和英语维基百科上训练的。除非另有说明,我们提到的 BERT 都是指 BERT-Base。
GPT 与 BERT 的关系是怎样的?两个模型使用了几乎一样的架构。事实上,GPT 和 BERT-Base 甚至使用了一样的层数和维数。唯一的差别是 BERT 是双向的,因为它试图根据上下文填入单个词,而 GPT 则使用了掩码式自注意头。
调整 GPT 和 BERT 以用于子词语言模型
GPT 仅需少量修改,除非我们想要探索不同的架构。毕竟其已经作为语言模型经过了训练。最低程度而言,在微调期间,我们可以添加一个线性层,其隐藏大小等于词汇库大小。这些权重经过调整并被送入 softmax,进而生成目标词在词汇库上的概率分布。掩码式自注意能确保仅出现因果信息流。
回想一下 BERT 的目标:掩码式语言模型和下一句子预测。掩码式语言模型使用的是双向上下文信息,并会在训练过程中随机地掩盖某些 token。其试图基于这一点推断被掩盖的词的「身份」。不幸的是,估计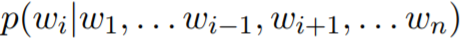
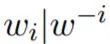
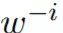
下一句子预测的目标是获取两个句子之间的二值化关系。重申一下,这不能直接用于语言模型。因此,我们移除了这一目标,并在微调过程中将其替换成了一个对数似然度量。类似于 GPT,我们添加一个输出线性层,并用掩码式自注意替代自注意头以防止信息向左流动。
注意 GPT 和 BERT 预训练权重会在语言模型微调过程中复用,以节省整个再训练的成本。因此,我们是在子词级上执行语言模型,因为 GPT 和 BERT 中都使用了子词 token 化。
微调 Transformer 权重
GPT 和 BERT 会针对前面提到的任务调整各自模型的权重。举个例子,BERT 默认并不使用开窗(windowing)。因为在针对语言建模进行微调时,调整权重是合理的。但是,更新所有权重可能导致过拟合,因为 WikiText 或 Penn Tree Bank 之类的数据集比用于训练 GPT 和 BERT 的数据小一个数量级以上。
为了解决这一难题,我们提出在微调过程中仅更新一部分层的权重。因为 GPT 和 BERT 都有 12 个 Transformer 模块,每一个模块都包含一个自注意和一个逐点全连接层,所以难以简单直接地选出参数应该固定的那部分层。于是我们转而自动搜索对语言模型任务而言最有效的那一部分层。搜索算法将在后面介绍。
添加一个 LSTM
通过 Transformer 中的傅立叶基实现的位置编码仅能提供模糊的相对位置信息,这会迫使层在每层为特定的词访问重新创建三角法(trigonometry)。这会出现问题,因为语言模型需要强大的词级上下文信息来预测下一个词。RNN 可显式地建模这种序列信息。因此我们提出向 Transformer 架构添加 LSTM 层。
理论上而言,我们可以在任意位置添加 LSTM 层,甚至可以将它们与 Transformer 交织起来。但是,LSTM 会显著影响计算效率,因为它们不支持并行计算。我们的推理过程类似于 SRU(简单循环单元 (Lei et al., 2018))的设计思路。因此,我们提出要么在所有基础 Transformer 模块之前添加一层 LSTM,要么就加在它们后面。对于前者,我们在嵌入层之后直接添加 LSTM 层,并移除位置嵌入和分段嵌入,因为我们相信 LSTM 层能够编码足够的序列信息。对于后者,我们在最后一个 Transformer 模块与输出线性层之间插入 LSTM 层。我们通过自动搜索认定这就是 LSTM 的最佳位置。
协调式架构搜索
现在我们已有了基本的组件,这里回顾一下为了获得表现优良的架构而提出的网络变换和相关的搜索过程。
网络变换
我们前面提出了多种可改变网络的变换方式,我们将它们分别称为:AddLinear、AddLSTM、FixSubset。其中 AddLinear 是添加线性输出层,AddLSTM 是添加 LSTM 层,FixSubset 是固定一部分 Transformer 模块的权重。
搜索候选项采样
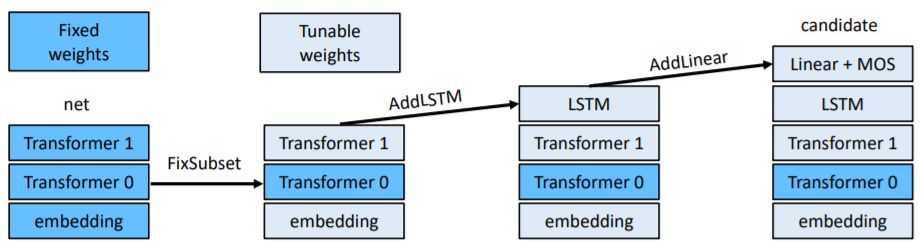
图 1:搜索候选项采样。图中 net 是指基础架构,candidate 是下一步骤返回的架构。Transformers、Embeddings、LSTM 和 Linear 是各种变换。其中颜色较浅的模块是可变的,深色模块是固定的。参见算法 1。

算法 1:搜索候选项采样
协调式架构搜索
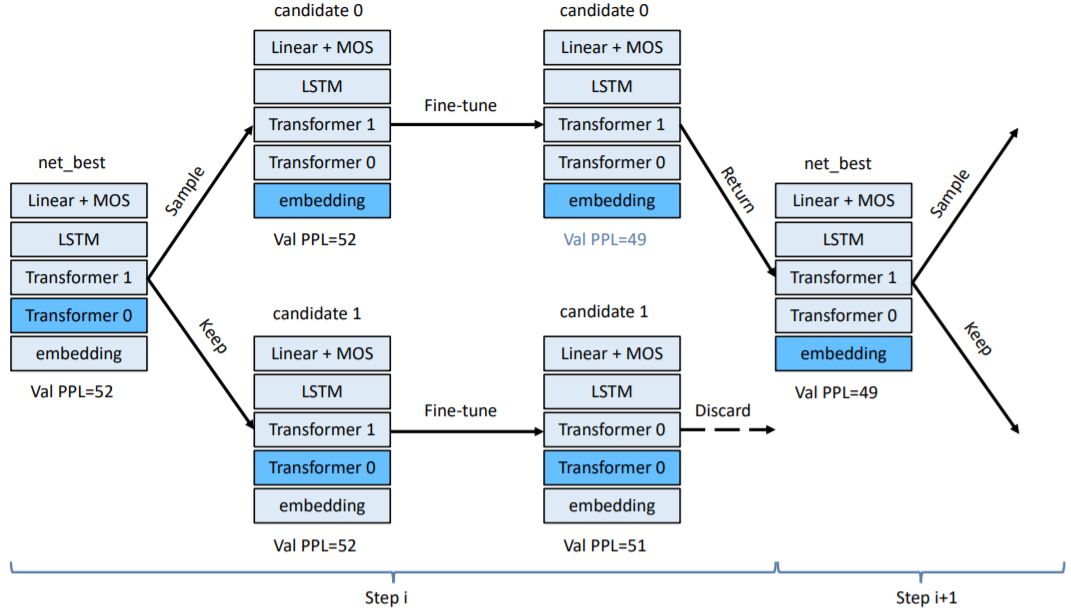
图 2:协调式架构搜索。net_best 是指搜索的第 i 步骤的最佳架构。我们采样搜索候选项,并保留表现最好的那个。我们的衡量指标是微调后在目标数据集上的困惑度(Val PPL)。参见算法 2。

算法 2:协调式架构搜索
实验
为了体现使用协调式搜索找到的 Transformer 架构的有效性,我们在 WikiText 和 Penn TreeBank 数据集上进行了实验。我们也给出了与其它已有神经搜索策略的比较。结果见表 1 和图 3。
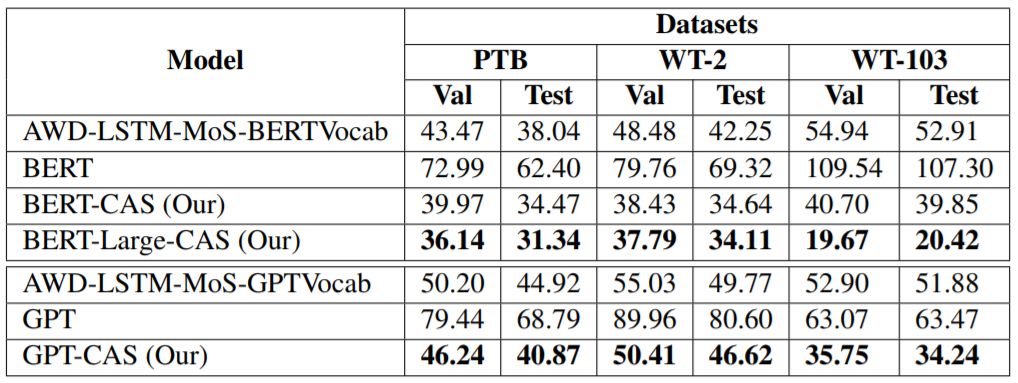
表 1:协调式架构搜索(CAS)的表现。Val 和 Test 分别指验证和测试困惑度。
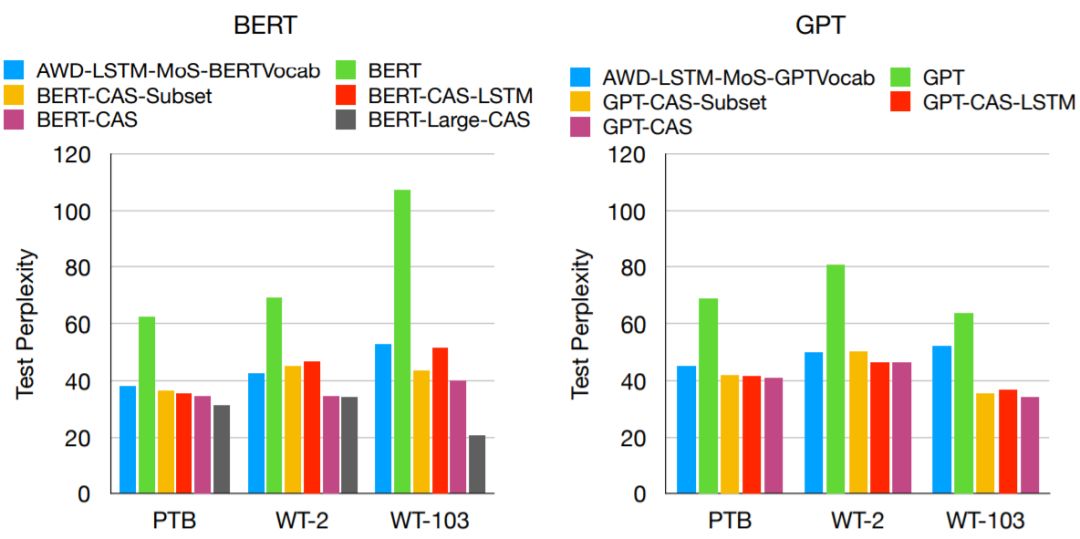
图 3:CAS 与其它模型的测试困惑度比较(左图是使用 BERT 预训练模型的结果;右图是使用 GPT 预训练模型的结果)。「Subset」是指没有使用 LSTM 的变体,「LSTM」则对应不更新 Transformer 模块的模型。
此外,我们也执行了消融实验,结果也证实了我们的直观认识,即我们需要首先使用固定子集权重保留粗粒度的表征,然后再使用 LSTM 来建模词序依赖性。
最后,我们还比较了新提出的模型与当前最佳的语言模型 GPT-2,比较指标分为三个维度:结果、参数规模、训练数据规模。结果见表 6 和表 7。可以看到,在参数方面我们的 BERT-Large-CAS 在 PTB 和 WT-103 上比 GPT-2 更高效,而在 WT-2 上的表现比 GPT-2 差,我们推测原因可能是 WT-2 的规模非常小。而在训练数据方面,BERT-Large-CAS 能用显著更少的数据达到相近的结果。
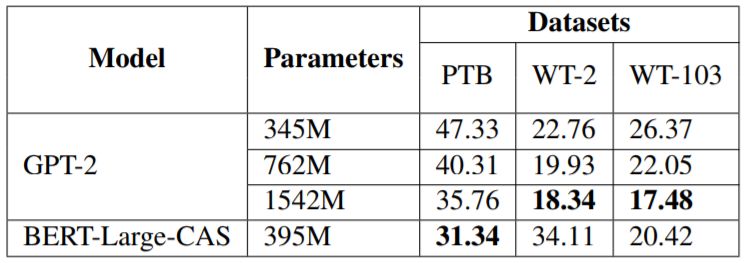
表 6:模型参数规模与模型结果的比较。GPT-2 模型大小和结果来自 Radford et al., 2019
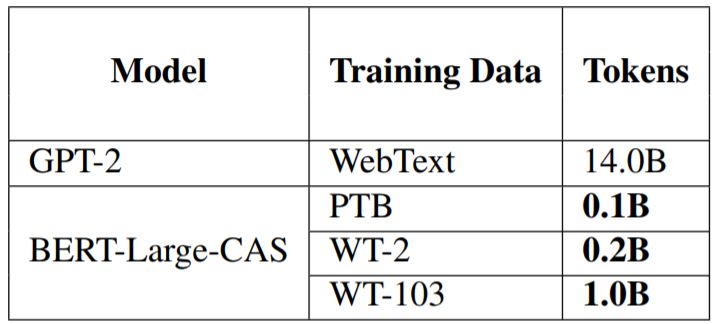
表 7:与 GPT-2 的训练数据集大小比较

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


