
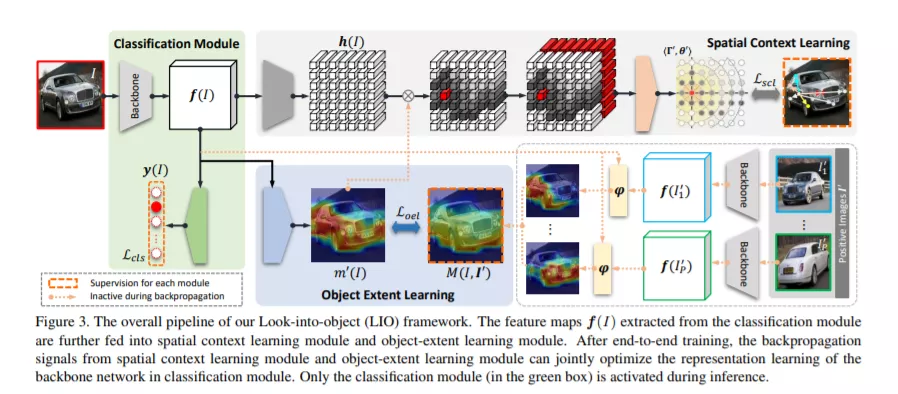
大多数的对象识别方法主要侧重于学习有判别性的视觉模式,而忽略了整体的物体结构。尽管很重要,但结构建模通常需要大量的手工注释,因此是劳动密集型的。在这篇论文中,我们提出通过将自我监督纳入传统的框架中来“观察对象”(明确而内在地对对象结构建模)。我们证明了在不增加额外注释和推理速度的情况下,识别主干可以被显著增强,从而实现更健壮的表示学习。具体来说,我们首先提出了一个对象范围学习模块,用于根据同一类别中实例间共享的视觉模式对对象进行本地化。然后,我们设计了一个空间上下文学习模块,通过预测范围内的相对位置,对对象的内部结构进行建模。这两个模块可以很容易地插入到任何骨干网络训练和分离的推理时间。大量的实验表明,我们的内视对象方法(LIO)在许多基准上获得了巨大的性能提升,包括通用对象识别(ImageNet)和细粒度对象识别任务(CUB、Cars、Aircraft)。我们还表明,这种学习范式可以高度泛化到其他任务,如对象检测和分割(MS COCO)。
成为VIP会员查看完整内容
相关内容

专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
36+阅读 · 2020年3月12日
Arxiv
15+阅读 · 2020年3月31日
Arxiv
7+阅读 · 2019年2月8日
Arxiv
7+阅读 · 2018年1月28日


相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
24+阅读 · 2020年4月4日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
36+阅读 · 2020年3月12日
相关资讯
相关论文
Arxiv
15+阅读 · 2020年3月31日
Arxiv
7+阅读 · 2019年2月8日
Arxiv
7+阅读 · 2018年1月28日