ICCV 2019论文解读:数据有噪声怎么办?你可以考虑负学习

编辑 | 唐里

1. 研究背景

2. 贡献
3. 方法
3.1 负学习
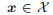 作为输入,
作为输入,
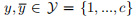 代表它的标签以及整个标签集合。
代表它的标签以及整个标签集合。
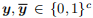 代表它们的独热码向量。假设
代表它们的独热码向量。假设
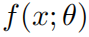 代表的是CNN将输入空间映射到一个c维的分数空间
代表的是CNN将输入空间映射到一个c维的分数空间
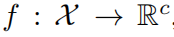 ,其中
,其中
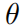 代表神经网络的参数。如果
代表神经网络的参数。如果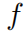 最后经过softmax函数,那么输出可以被表示为一个概率分布
最后经过softmax函数,那么输出可以被表示为一个概率分布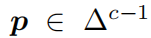 ,其中
,其中
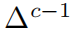 代表c维的概率分布。当使用PL训练时,网络的交叉熵损失函数变成:
代表c维的概率分布。当使用PL训练时,网络的交叉熵损失函数变成:
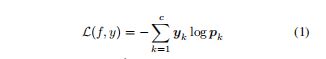
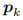 代表
代表
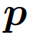 的第
的第
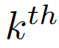 个元素。等式(1)适合使用PL训练时最终要优化的损失函数。但是NL不同于PL,因为它要求
个元素。等式(1)适合使用PL训练时最终要优化的损失函数。但是NL不同于PL,因为它要求
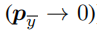 ,所以我们提出NL的损失函数如下:
,所以我们提出NL的损失函数如下:
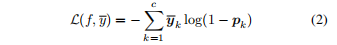

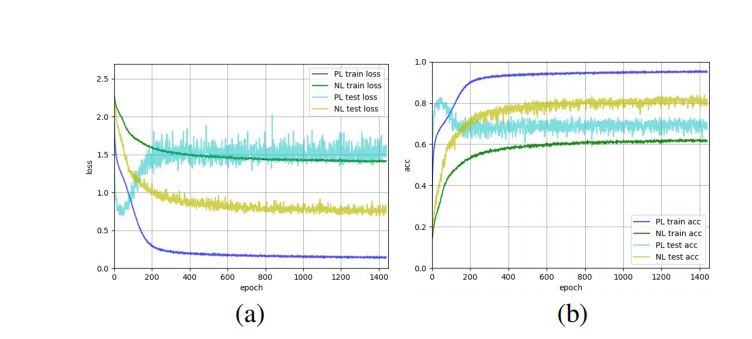
3.2 选择性的负学习
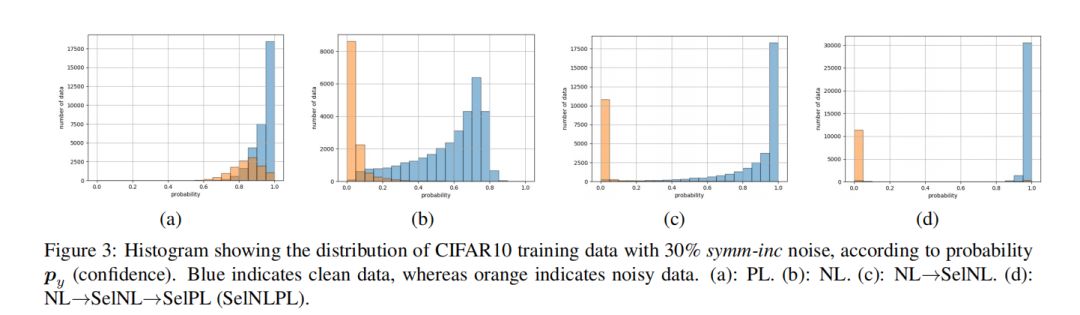
3.3 选择性的正学习
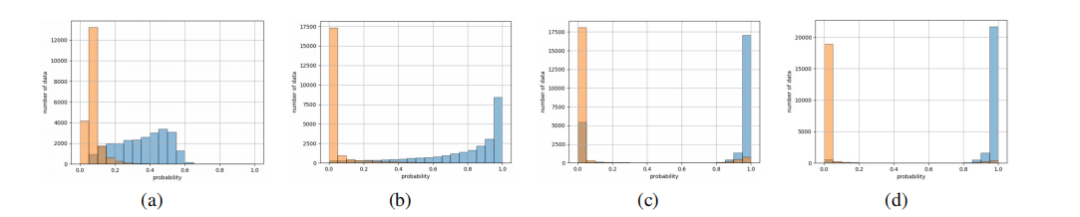
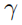 的数据来训练CNN,并保证这些数据是无噪数据。这里,我们取为0.5,Figure3(d)展示了SelPL在经过SelNL处理后训练的结果,几乎所有无噪数据的置信度都接近1。
的数据来训练CNN,并保证这些数据是无噪数据。这里,我们取为0.5,Figure3(d)展示了SelPL在经过SelNL处理后训练的结果,几乎所有无噪数据的置信度都接近1。

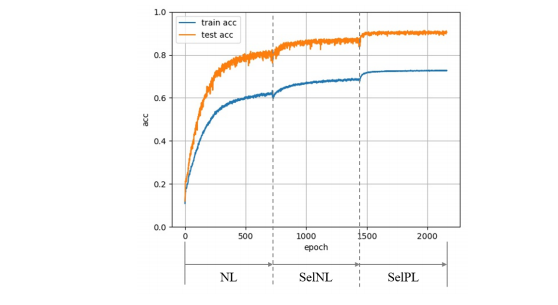
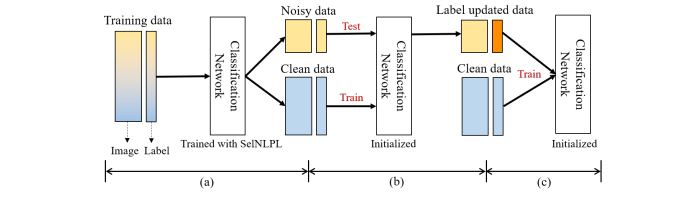
4. 过滤能力
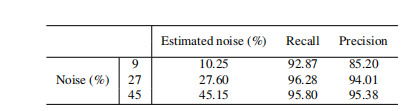
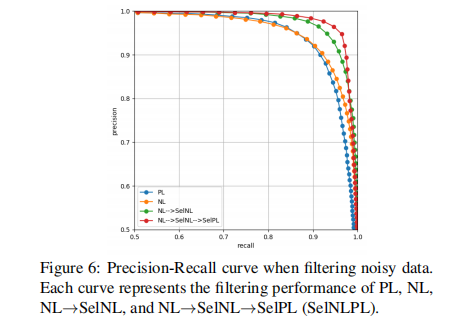
的数据认为是干净的。按照这种方法,我们将未经PL训练的数据看做是噪声数据。Table1总结了具有各种噪声比值的CIFAR10上的SelNLPL滤波结果。其中Estimated noise表示未经PL训练的数据中的噪声比。召回率和精度是衡量噪声数据过滤质量的方法。结果标签,估计的噪声比几乎和实际噪声匹配度在88%到99%之间。此外,Table1展示我们过滤噪声数据的方法可以产生较高的召回率和精度值,这代表我们的方法从训练数据中滤除了大多数纯噪声数据。这意味即使未知混入训练数据的噪声量(在实际情况中是正常现象),也可以使用SelNLPL估算噪声量,这是一个巨大的优势,因为它可以用作训练数据标注质量的判断标准。Figure6比较了我们的方法的总体过滤能力。PL曲线是在过度拟合噪声数据之前用PL训练的模型测试获得的。曲线表明,SelNLPL的每个步骤都有助于提高过滤性能。
5. 实验
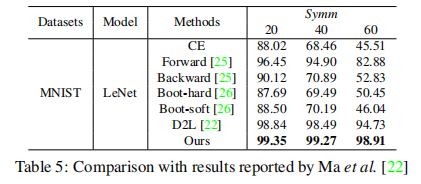
6. 分析
6.1 适应多类别数据
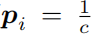 。
梯度被表示为:
。
梯度被表示为:
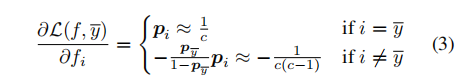
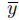 损失函数的梯度减小了,但还会出现一个梯度,以增强与其他类别(包括真实标签
损失函数的梯度减小了,但还会出现一个梯度,以增强与其他类别(包括真实标签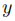 )相对应的分数。
这意味着,使用NL训练CNN后,获
得的梯度是
)相对应的分数。
这意味着,使用NL训练CNN后,获
得的梯度是
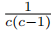 。
假设我们正在使用10个分类或者100个分类的数据集,获得的梯度是
。
假设我们正在使用10个分类或者100个分类的数据集,获得的梯度是
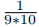 对于10类的数据,
对于10类的数据,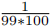 对于100类的数据。
比较这两种情况,100类数据集的梯度比10类数据集的梯度小110倍。
该分析表明,要使NL在CIFAR100上收敛,需要的时间比CIFAR10要长的多,大约是110倍。
由于训练CNN需要大量时间,因此我们扩展了方法,以便为每个图像提供多个随机互补标签。
我们为单个数据随机选择110个可重复标签,从而计算110个随机损失,因为110个损失共享同一张图像计算的特征,所以反向传播时间仅仅略有增加。
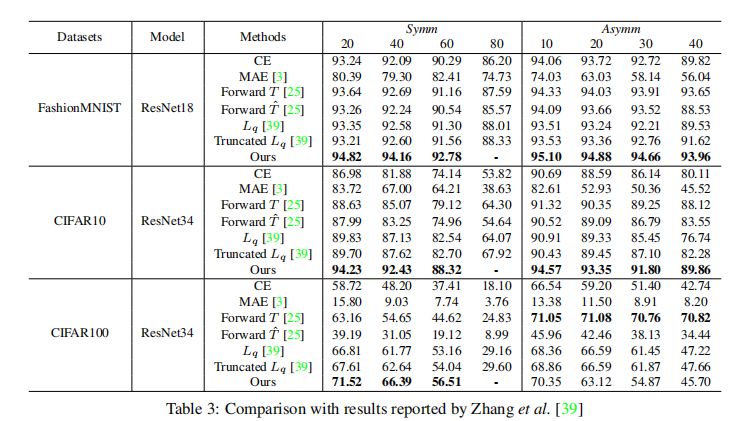
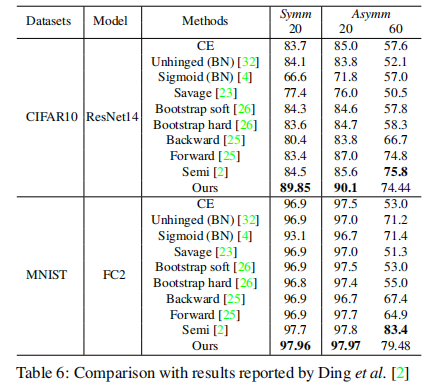
通过这种简单的扩展方法,我们观察到,在以CIFAR10训练相同的轮次时,CIFAR100可以收敛,并展示出了良好的抗噪性能,如上节的Table3所示。
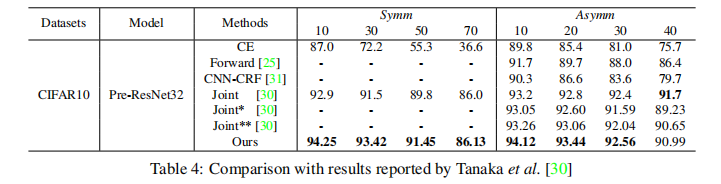
对于对称噪声,我们获得了SOAT结果。
对于非对称噪声,Forwars T展示了最好的性能。
但是,这不是一个公平的比较,因为它依赖于混淆矩阵的先验知识,该知识总结了一个类别在噪声下翻转为另一类别的可能性。
因此可以得出结论,我们的方法在不和Forward T比较时取得了SOAT结果。
在这一节中,我们展示了我们的方法可以通过为每个图像提供多个互补标签而推广到具有多个类别的数据集上。
对于100类的数据。
比较这两种情况,100类数据集的梯度比10类数据集的梯度小110倍。
该分析表明,要使NL在CIFAR100上收敛,需要的时间比CIFAR10要长的多,大约是110倍。
由于训练CNN需要大量时间,因此我们扩展了方法,以便为每个图像提供多个随机互补标签。
我们为单个数据随机选择110个可重复标签,从而计算110个随机损失,因为110个损失共享同一张图像计算的特征,所以反向传播时间仅仅略有增加。
通过这种简单的扩展方法,我们观察到,在以CIFAR10训练相同的轮次时,CIFAR100可以收敛,并展示出了良好的抗噪性能,如上节的Table3所示。
对于对称噪声,我们获得了SOAT结果。
对于非对称噪声,Forwars T展示了最好的性能。
但是,这不是一个公平的比较,因为它依赖于混淆矩阵的先验知识,该知识总结了一个类别在噪声下翻转为另一类别的可能性。
因此可以得出结论,我们的方法在不和Forward T比较时取得了SOAT结果。
在这一节中,我们展示了我们的方法可以通过为每个图像提供多个互补标签而推广到具有多个类别的数据集上。
6.2 对照研究
7. 总结



登录查看更多
相关内容

专知会员服务
36+阅读 · 2020年3月13日
专知会员服务
20+阅读 · 2020年1月26日



相关VIP内容
专知会员服务
36+阅读 · 2020年3月13日
专知会员服务
20+阅读 · 2020年1月26日
相关资讯
相关论文