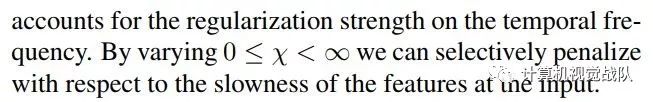CVPR 2018 笔记
CVPR 2018笔记,感谢李光睿的分享,谢谢~
知乎号:https://www.zhihu.com/people/chang-you-li-92/activities
Discriminative Learning of Latent Features for Zero-Shot Recognition
CVPR 2018 ORAL
zero-shot learning的解释可以详情见郑哲东在知乎中的回答,就是寻求将学习到的特征映射到另一个空间中,从而map到seen及unseen的属性或者label上
这篇文章的主要亮点在于学习了已定义label的同时,学习了latent attribute(隐含属性)。
已有方案的drawbacks:
1,在映射前,应当抽取image的feature,传统的用pretrain model等仍不是针对zero-shot learning (ZSL)特定抽取特征的最优解。
2,现有的都是学习user-defined attribute,而忽略了latent representation
3,low-level信息和的空间是分离训练的,没有大一统的framework
本文便是对应着解决了以上问题。
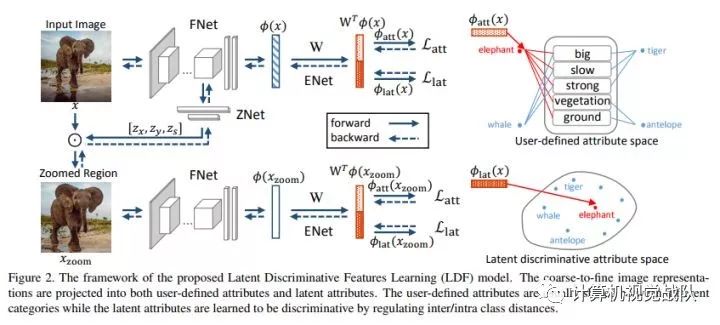
notation:
FNet:抽取img的feature;
ZNet: 定位最discriminative的区域并将其放大
ENet: 将img feature映射到另一个空间
下面我们先介绍各个子网络
FNet(The Image Feature Network)
这部分直接借用了已有的VGG19、GoogleNet,不细讲
ZNet(The Zoom Network)
这里的目的是定位到能够增强我们提取的特征的辨识度的region,这个region同时也要与某一个我们已经定义好了的attribute对应。
ZNet的输入是FNet最后一个卷积层的输出。
在这里运用某个已有的激活函数方法,将我们定位好了的region提取出来,即将crop操作在网络中直接实现。
然后,将ZNet的输出与original img做element-wise的乘法,最后,将region zoom到与original img相同的尺寸。
如图,再讲该输出输入到另一个FNet(第一个Fnet的copy)
ENet(The Embedding Network)
这里作者提出了一个score用于衡量img feature和attribute space的相似性(兼容性)


Enet将img feature映射到2k dim的空间中,1k是对应于已经定义了的label,并用softmax loss。
另1k则是对应潜藏属性,为了使这些特征discriminative,作者使用了triplet loss。
Synthesizing Images of Humans in Unseen Poses
pose 合成
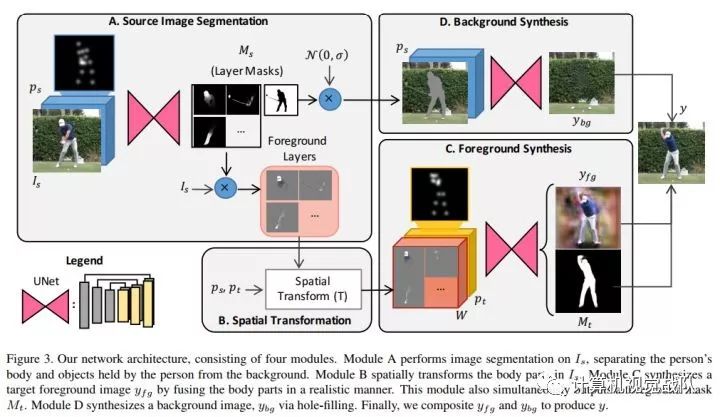
网络的输入是original img, original pose, target pose,并预设original img和target img背景一样,人是同一个。
首先前后景分离,然后针对前景(即人),针对身体的不同部分做细致的segment
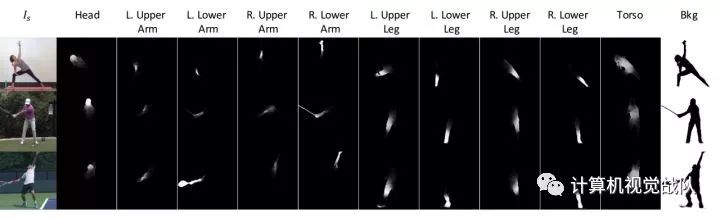
Pose Representation
人身体的pose用14个dots表示,在dots处还加入了高斯噪声,有利于regularization,且有利于网络更快学习到这个特征。
Source Image Segmentation
分前后景,前景又对应着已经定义好了的身体部分(10个)。
采用u-net,输入是original img和pose的concat,输出是各个部分的mask。
Foreground Spatial Transformation
这一过程则是将分割后的segment和target pose一一对应起来,并作相应的旋转,放缩等。
Foreground Synthesis
前一阶段我们已经根据target pose将各个segment位置变换好了,简言之,就是把人的是个部分拆开来,然后根据目标姿势重新组合,这一步则是将其彻底的合成,使其具备和真实照片一眼的一致性。
也是用的u-net,输入为target pose和已经segments,输出时foreground和target mask。
Background Synthesis
这部分则是处理新的target之间的孔洞,无新意。
Loss Function
两部分组成
VGG LOSS: 将VGG19的前16层的输出concat并计算L1距离
传统的GAN loss。
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
本文解决了GAN生成高分辨率突破的问题,分辨率达到了2048*1024,方法精细,值得深入来看。
先来看generator:
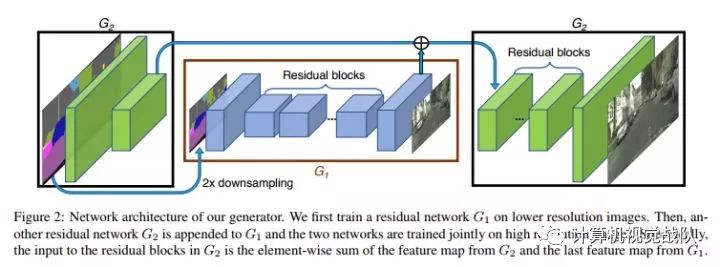
再来看D:
这里的dsicriminator是multi-scale,有着三个针对不同尺寸的D,三个尺寸分别是原尺寸,二分之一,四分之一。
放缩尺寸的理由不难理解,receptive field大小的问题。

Improved adversarial loss
一句话概括:在D的中间多个层抽取feature map,作为分类和训练依据。
Using Instance Map:
个人认为是本文最inspiring的一点,先放对比图
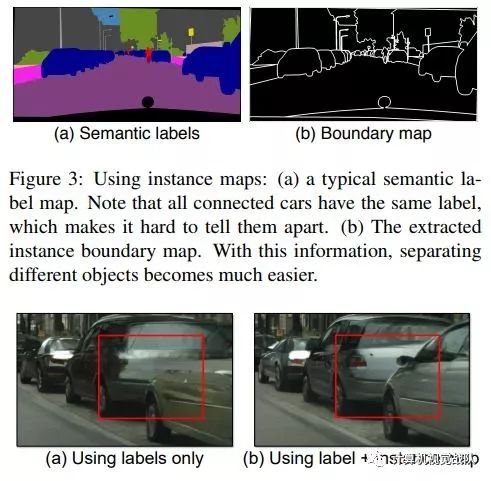
图胜千言,boundary map一方面更加精细,也对边缘的处理上给出了看起来很理想的解决方案。具体的对比解释可以去文中寻找。
b map的提取不难理解,主要是基于semantic labels。
Learning an Instance-level Feature Embedding
这部分是基于前面提到的instance level信息,做一个精细化的embedding。
在generator的输入中,除了ori img,boundary map之外,还有low-dimensional feature。
为了生成这些low-dim feature,作者又设计了一个标准的encoder-decoder来生成。
在这个encoder训练好之后,还用生成的特征做了一个聚类,从而可以控制生成图片的style。
What have we learned from deep representations for action recognition?
这篇文章就是two-stream模型中间层的可视化方法,换句话说,就是探寻two-stream模型学到了怎样的时空信息。
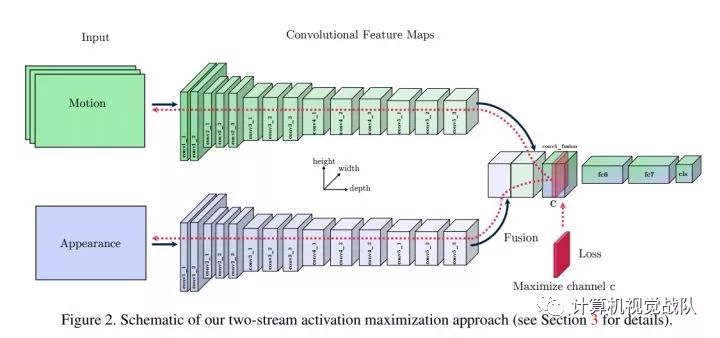

Activation maximization

本文还提到了两个正则方法:
1,防止过大的值

2,限制低频信息