
【导读】最近小编推出CVPR2019图卷积网络相关论文、CVPR2019生成对抗网络相关视觉论文和【可解释性】相关论文和代码,反响热烈。最近,视觉目标跟踪领域出现了很多不同的框架和方法,CVPR 2019已经陆续放出十几篇相关文章,这一领域近期也受到大家广泛的关注。今天小编专门整理最新九篇视觉目标跟踪相关应用论文—无监督视觉跟踪、生成对抗网络、三维Siamese跟踪、SiamMask、SiamRPN++、SPM-Tracker等。
1、Unsupervised Deep Tracking (无监督的深度跟踪)
CVPR ’19
作者:Ning Wang, Yibing Song, Chao Ma, Wengang Zhou, Wei Liu, Houqiang Li
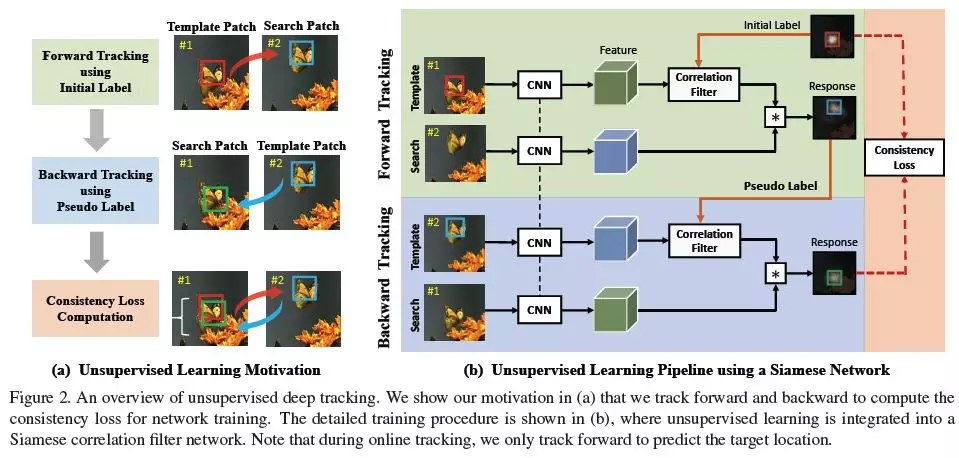
摘要:我们在本文中提出了一种无监督视觉跟踪方法。与现有的使用大量标注数据进行监督学习的方法不同,我们的CNN模型是以一种无监督的方式对大规模无标记视频进行训练的。我们的动机是,一个健壮的跟踪器应该在前向和后向预测中都是有效的(即,跟踪器可以在连续帧中对目标对象进行前向定位,并在第一帧中回溯到目标对象的初始位置)。我们在Siamese相关滤波器网络上构建了我们的框架,该网络使用未标记的原始视频进行训练。同时,我们提出了一种多帧验证方法和代价敏感的损失函数,以方便无监督学习。在没有监督信息的情况下(without bells and whistles),所提出的无监督跟踪器达到了完全监督跟踪器的baseline精度,这需要在训练过程中完整且准确的标签。此外,无监督框架显示了利用无标记或弱标记数据进一步提高跟踪精度的潜力。
网址:
https://arxiv.org/abs/1904.01828
代码链接:
https://github.com/594422814/UDT
2、Target-Aware Deep Tracking( 目标感知的深度跟踪)
CVPR ’19
作者:Xin Li, Chao Ma, Baoyuan Wu, Zhenyu He, Ming-Hsuan Yang
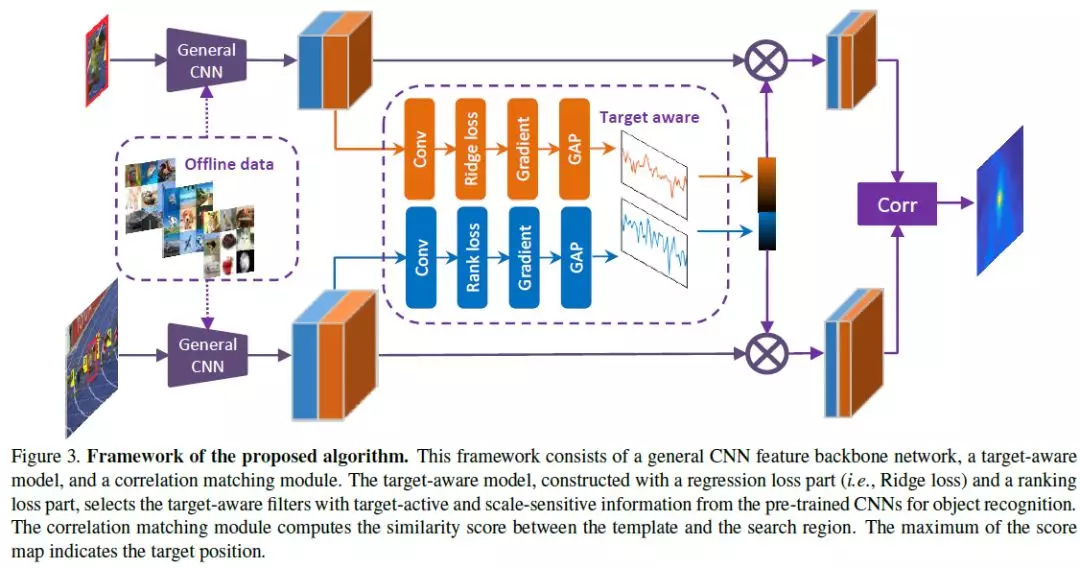
摘要:现有的深度跟踪器主要使用卷积神经网络对泛型目标识别任务进行预处理来表示。尽管在许多视觉任务中都取得了成功,但是使用预先训练的深度特征进行视觉跟踪的贡献不如目标识别那么重要。关键问题是,在视觉跟踪中的目标的可以是任意对象类与任意形式。因此,预先训练的深层特征在建模这些任意形式的目标时效果较差,无法将它们从背景中区分出来。在本文中,我们提出了一种新的学习目标感知特征的方法,该方法能够比预训练的深度特征更好地识别发生显著外观变化的目标。为此,我们提出了回归损失和排名损失来指导目标活动和尺度敏感特征的生成。我们根据反向传播的梯度来识别每个卷积滤波器的重要性,并基于用于表示目标的激活来选择目标感知特征。目标感知特征与Siamese匹配网络集成,用于视觉跟踪。大量的实验结果表明,该算法在精度和速度上均优于现有的算法。
网址:
https://arxiv.org/abs/1904.01772
代码链接:
https://github.com/XinLi-zn/TADT
3、MOTS: Multi-Object Tracking and Segmentation(MOTS:多目标跟踪和分割)
CVPR ’19
作者:Paul Voigtlaender, Michael Krause, Aljosa Osep, Jonathon Luiten, Berin Balachandar Gnana Sekar, Andreas Geiger, Bastian Leibe
摘要:本文将多目标跟踪的流行任务扩展到多目标跟踪与分割(MOTS)。为此,我们使用半自动标注程序为两个现有跟踪数据集创建密集的像素级标注。我们的新标注包含了10870个视频帧中977个不同对象(汽车和行人)的65,213个像素掩码。为了进行评估,我们将现有的多对象跟踪指标扩展到这个新任务。此外,我们提出了一种新的baseline方法,该方法通过单个卷积网络共同解决检测,跟踪和分割问题。在对MOTS标注进行训练时,我们通过提高性能来展示数据集的价值。我们相信,我们的数据集、度量metrics和baseline将成为开发超越二维边界框的多对象跟踪方法的宝贵资源。我们的注释,代码和模型可以在 https://www.vision.rwth-aachen.de/page/mots上找到。
网址:
https://arxiv.org/abs/1902.03604
代码链接:
https://www.vision.rwth-aachen.de/page/mots
4、Leveraging Shape Completion for 3D Siamese Tracking(利用形状补全三维Siamese跟踪)
CVPR ’19
作者:Paul Voigtlaender, Michael Krause, Aljosa Osep, Jonathon Luiten, Berin Balachandar Gnana Sekar, Andreas Geiger, Bastian Leibe
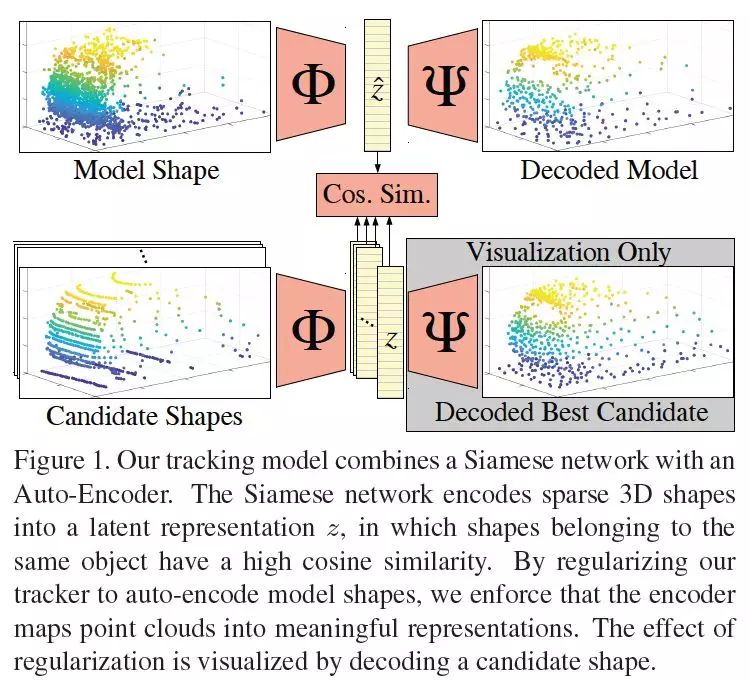
摘要:点云由于其稀疏性,处理起来很有挑战性,因此自动驾驶车辆更多地依赖于外观属性,而不是纯粹的几何特征。然而,三维激光雷达感知在具有挑战性的光或天气条件下可以为城市导航提供重要的信息。本文研究了形状补全Shape Completion在LIDAR点云三维目标跟踪中的通用性。我们设计了一个Siamese追踪器,将模型和候选形状编码成一个紧凑的潜在表示。我们通过强制将潜在表示解码为对象模型形状来规范编码。我们观察到,三维物体跟踪和三维形状补全Shape Completion是相辅相成的。学习更有意义的潜在表示可以显示更好的区分能力,从而提高跟踪性能。我们在KITTI Tracking数据集上使用汽车3D bounding boxes测试了我们的方法。我们的模型对三维目标跟踪的成功率为76.94%,精度为81.38%,形状补全Shape Completion正则化使得两种指标都提高了3%。
网址:
https://arxiv.org/abs/1903.01784
代码链接:
https://github.com/SilvioGiancola/ShapeCompletion3DTracking
5、LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking(LaSOT:基于大规模单目标跟踪的高质量基准)
CVPR ’19
作者:Heng Fan, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Hexin Bai, Yong Xu, Chunyuan Liao, Haibin Ling
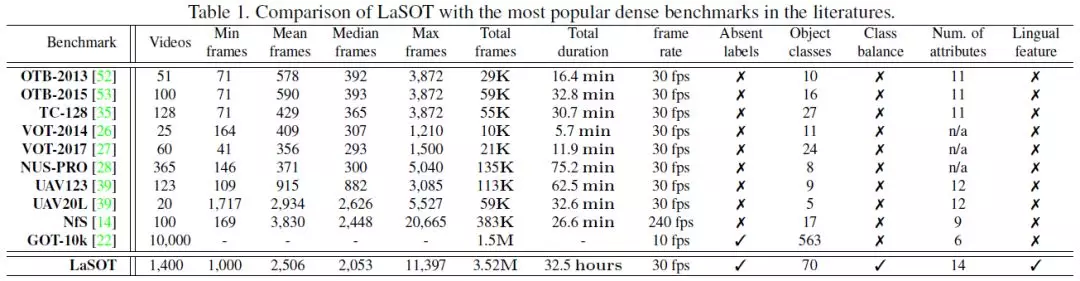
摘要:本文提出了一种用于大规模单目标跟踪的高质量基准LaSOT。LaSOT由1400个序列组成,总帧数超过350万。这些序列中的每一帧都小心翼翼地用一个边界框手工标注,使LaSOT成为我们所知最大的、标注密集的跟踪基准。LaSOT的平均视频长度超过2500帧,每个序列都包含来自野外的各种挑战,在野外,目标对象可能会消失,然后重新出现在视图中。通过发布LaSOT,我们希望为社区提供一个大规模、高质量的专用基准,用于深度跟踪器的训练和跟踪算法的真实评估。此外,考虑到视觉外观与自然语言的紧密联系,我们通过提供额外的语言规范来丰富LaSOT,旨在鼓励探索自然语言特征来进行跟踪。对LaSOT上的35种跟踪算法进行了全面的实验评估,并进行了详细的分析,结果表明,该算法仍有很大的改进空间。
网址:
https://arxiv.org/abs/1809.07845
6、Fast Online Object Tracking and Segmentation: A Unifying Approach(快速在线目标跟踪和分割: 一种统一的方法)
CVPR ’19
作者:Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, Philip H.S. Torr
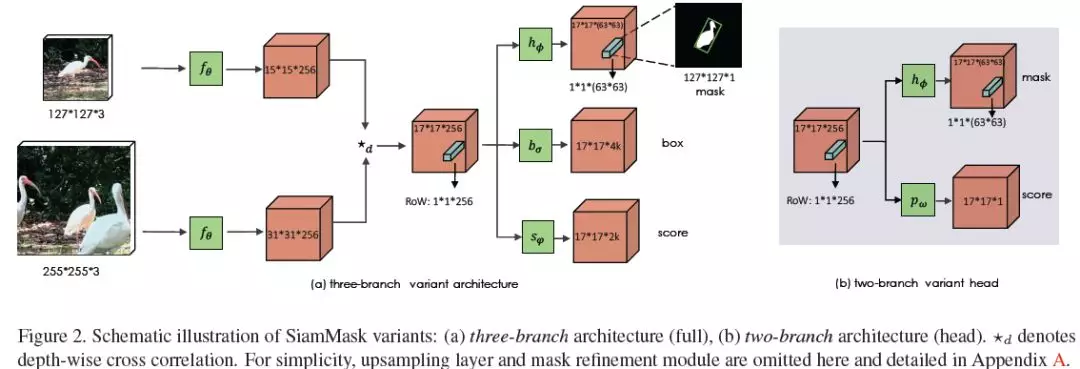
摘要:在本文中,我们将介绍如何用一种简单的方法实时地执行视觉目标跟踪和半监督视频目标分割。我们的方法,称为SiamMask,改进了流行的全卷积Siamese方法的离线训练过程,通过一个二值分割任务增加了它们的损失。经过训练,SiamMask完全依赖于单个边界框初始化并在线操作,生成与类无关的目标分割掩码,并以每秒35帧的速度旋转边界框。它不仅具有简单性、多功能性和快速性,还使我们能够在VOT-2018上建立一个新的最好的实时跟踪器,同时在DAVIS-2016和DAVIS-2017上展示出具有竞争力的性能和半监督视频对象分割任务的最佳速度。
网址:
https://arxiv.org/abs/1812.05050
代码链接:
http://www.robots.ox.ac.uk/~qwang/SiamMask/
7、SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks(SiamRPN++: 使用深层网络的Siamese视觉跟踪演化)
CVPR ’19
作者:Bo Li, Wei Wu, Qiang Wang, Fangyi Zhang, Junliang Xing, Junjie Yan
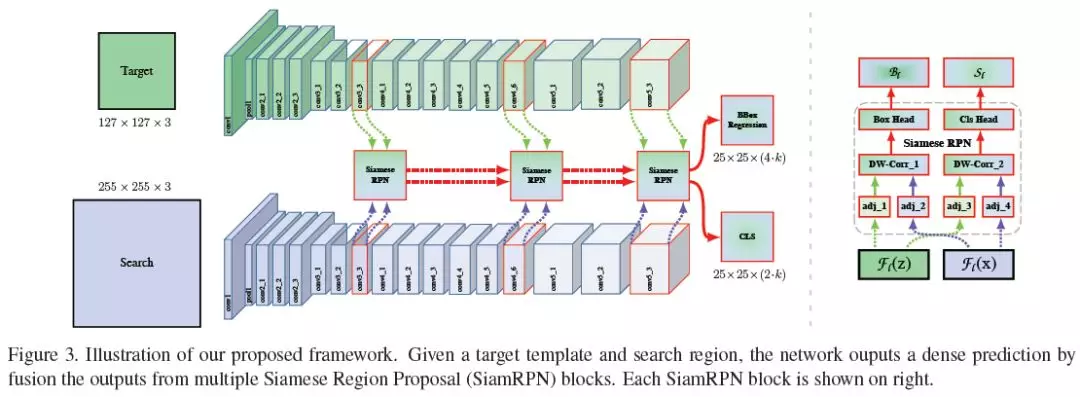
摘要:基于Siamese网络的跟踪器将跟踪描述为目标模板与搜索区域之间的卷积特征互相关联。然而,与最先进的算法相比,Siamese跟踪器仍然存在精度上的差距,它们无法利用深度网络(如ResNet-50或更深)的特性。在本文中,我们证明了其核心原因是缺乏严格的翻转不变性。通过全面的理论分析和实验验证,我们通过一种简单有效的空间感知采样策略打破了这一限制,成功地训练了一个性能显著提高的ResNet驱动的Siamese跟踪器。此外,我们提出了一种新的模型架构来执行深度和层次的聚合,这不仅进一步提高了精度,而且减少了模型的大小。我们进行了广泛的消融研究来证明所提出的跟踪器的有效性,该跟踪器目前在OTB2015、VOT2018、UAV123和LaSOT四个大型跟踪基准上获得了最佳结果。我们的模型将会发布,以方便研究人员基于这个问题做进一步的研究。
网址:
https://arxiv.org/abs/1812.11703
代码链接:
8、Deeper and Wider Siamese Networks for Real-Time Visual Tracking(更深入和更广泛的Siamese网络实时视觉跟踪)
CVPR ’19
作者:Zhipeng Zhang, Houwen Peng
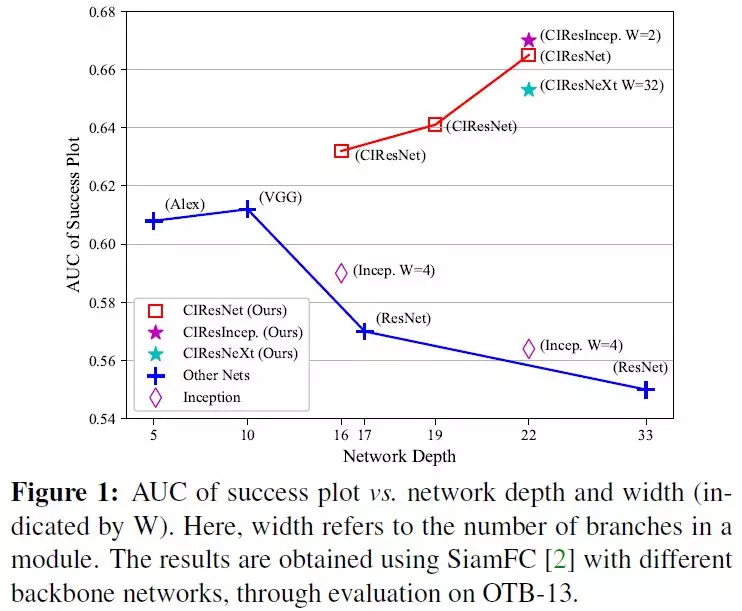
摘要:Siamese网络以其均衡的精度和速度在视觉跟踪领域引起了广泛的关注。然而,Siamese跟踪器中使用的主干网络相对较浅,如AlexNet[18],没有充分利用现代深度神经网络的优势。在本文中,我们研究如何利用更深更广的卷积神经网络来提高跟踪的鲁棒性和准确性。我们注意到,用现有的强大架构(如ResNet[14]和Inception[33])直接替换主干网络并不能带来改进。主要原因是1)神经元接受域的大量增加导致特征识别率和定位精度下降;2)卷积的网络padding导致了学习中的位置偏差。为了解决这些问题,我们提出了新的residual模块,以消除padding的负面影响,并进一步设计使用这些模块的新的架构控制感知域大小和网络步长。设计的架构非常轻巧,并且在应用于SiamFC [2]和SiamRPN [20]时保证了实时跟踪速度。实验表明,仅由于提出的网络架构,我们的SiamFC+和SiamRPN+在OTB-15、VOT-16和VOT-17数据集上分别获得了9.8%/5.7% (AUC)、23.3%/8.8% (EAO)和24.4%/25.0% (EAO)的相对改进[2,20]。
网址:
https://arxiv.org/abs/1901.01660
代码链接:
https://github.com/researchmm/SiamDW
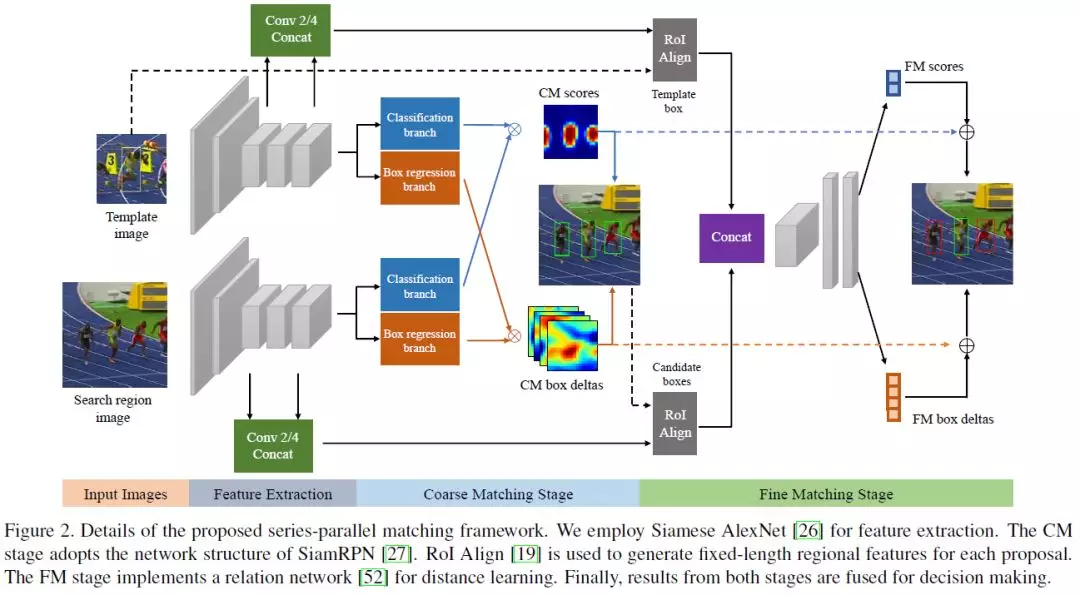
9、SPM-Tracker: Series-Parallel Matching for Real-Time Visual Object Tracking(SPM-Tracker: 用于实时视觉目标跟踪的串并联匹配机制)
CVPR ’19
作者:Guangting Wang, Chong Luo, Zhiwei Xiong, Wenjun Zeng
摘要:视觉目标跟踪面临的最大挑战是同时要求鲁棒性和识别能力。为了解决这一问题,本文提出了一种基于SiamFC的跟踪器,SPM-Tracker。基本思想是在两个独立的匹配阶段处理这两个需求。粗匹配(CM)阶段通过广义训练增强了鲁棒性,而精细匹配(FM)阶段通过远程学习网络增强了分辨能力。当CM阶段的输入提议由CM阶段生成时,这两个阶段串联连接。当匹配分数和box位置细化被融合在一起产生最终结果时,它们也被并行连接。这种创新的串并联结构充分利用了两个阶段,从而实现了卓越的性能。该SPM-Tracker在GPU上运行速度为120fps,在OTB-100上的AUC为0.687,在VOT-16上的EAO为0.434,显著超过其他实时跟踪器。
网址:
https://arxiv.org/abs/1904.04452v1
链接:https://pan.baidu.com/s/1Cuomaq3lrB6ub39Xt1Br0g 提取码:ydw4

