CVPR 2018值得一看的25篇论文,都在这里了 | 源码 & 解读
作者丨李光睿
学校丨重庆大学本科在读
研究方向丨计算机视觉


#Image Synthesis
CVPR 2018 Spotlight 论文,ReID + GAN 换 pose。
本文用了较多的篇幅讲 loss function,pose 的提取用的是 OpenPose 这个库。
其 loss 分为三部分:
1. Image Adversarial Loss:即传统 GAN 的 loss;
2. Pose Loss:pose 差异,生成后的图片再用 OpenPose 提取 pose 信息做差值;
3. Identity Loss:此为关键,又分为两部分,分别是 content 和 style loss,其中 content 用于保证生成图和原图在某 pretrain model 生成的 feature map 一致, style 则是利用 Gram matrix 生成某种 feature map,然后作比对。

#Person ReID
CVPR 2018 RE-ID Spotlight 一篇,这篇文章主要 contribution 有以下两点:
1. 提出了一个新的更大的数据集,更为细致:考虑到了视角,光照等更为细致的因素,具体参数可以直接看文章;
2. 多个数据集间的差异,即 domain-gap,通过 GAN 来生成和模仿,类似文章:Camera Style Adaptation for Person Re-identification,个人认为创意是有的,可以作为 data augmentation 的一个方法,但实现难度上并没有很大。

Disentangled Person Image Generation
#Image Generation
在 NIPS 2017 上,该团队已经为我们贡献了 Pose Guided Person Image Generation 这篇非常棒的文章,在 CVPR 2018 中,他们推出的更新的这篇文章不仅仅解决了换 pose 问题,还实现了”随心所欲“的换装换 pose,入选今年的 Spotlight。
在这里提到的前一篇文章可复现度很高,可以尝试。
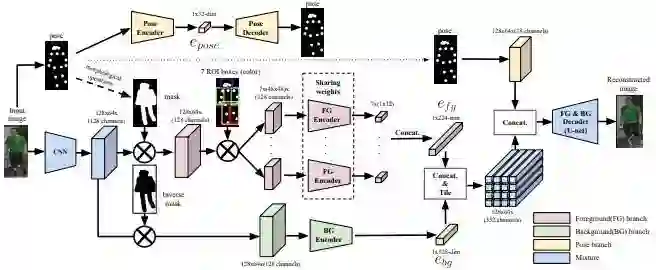
该模型分为三个分支:
1. 运用 OpenPose 这个库,生成 pose 的 18 个 dots,并将这 concat 进 decoder 之前的 feature map 中;
2. 在经过卷积运算后的 feature map 上,运用 mask 将前后景分离,背景的 feature map 也是直接 concat 进最后的 feature map 中;
3. 核心是前景的处理上,用 7 个 ROI 进一步将前景解开,然后用公用的 encoder 生成前景的 feature map。

#Network Generation
CVPR 2018 Oral 一篇,本文主要提出了通过封装模块(block-wise)的方法,运用增强学习设计生成网络架构的方法。
封装模块思路:
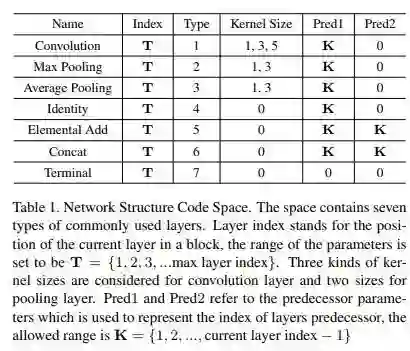
作者本人对增强学习和动态规划理解有限,模块生成的总体思路是 Q-Learning 及动态规划,其中提到了运用 reward shaping 优化设计过程,当是本文亮点之一。
设计完网络后,生成对应任务的准确率,作为 q-value(即 reward),然后再次重新生成网络。
此外,文章还提到了部分 trick:
在 reward 中将复杂度和计算复杂度纳入;
early-stopping

#Convolutional Neural Networks
CVPR 2018 Oral,topic:网络设计模块化。
如名所示,提出了 aggregation 的具体思路,并在层融合上提出了具体方式。
#Face Age Progression
CVPR 2018 Oral,intro 和 related works 主要讲了现有方案大多将年龄信息优先而 identity 信息次之,换句话说,就是生成不同年龄的同时,identity 信息不能很好保留。
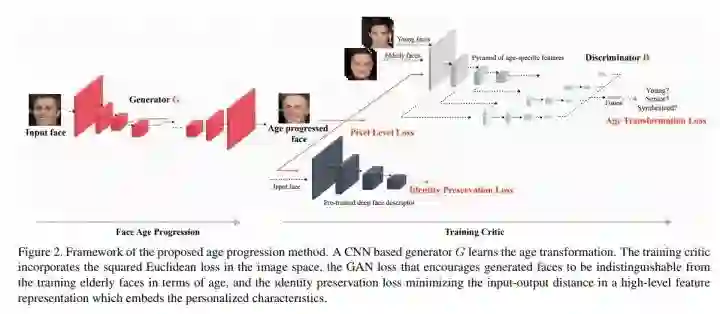
Generator 部分不做介绍,无亮点,本文亮点在 loss 部分。
文中提出了特征提取器用于提出特定特征,原因是作者认为相同年龄段的不同人脸有着相同的的纹理等特定信息,而这个提取器就是提取出这些特征。此外,该分类器是经过 age 分类任务预训练好了的。

文中和今年很多思路一样,考虑到了 low-level 和 high-level 信息,将第 2、4、7 等层信息 concat 起来,作为 d 的输入。
identity 信息的保留和上一个 extractor 类似,在人脸分类数据集上预训练,然后拿来直接当 extractor。
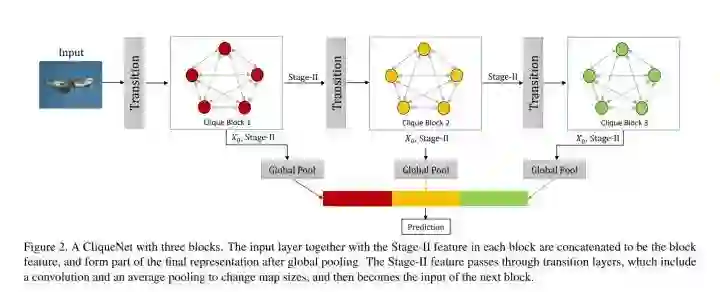
#Convolutional Neural Network
北大团队提出的新的 block 设计,achieves the performance of the state of the art with less parameters.
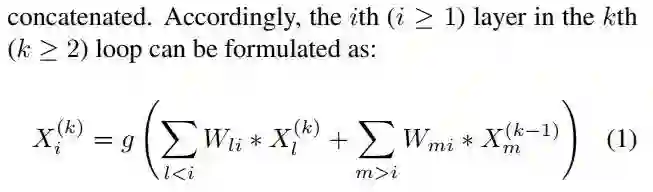
block 内部更新的核心思路可以直接看这个公式,每一层更新时的输入是比他低的层的更新后的输出加上比他高的层更新前的输出。
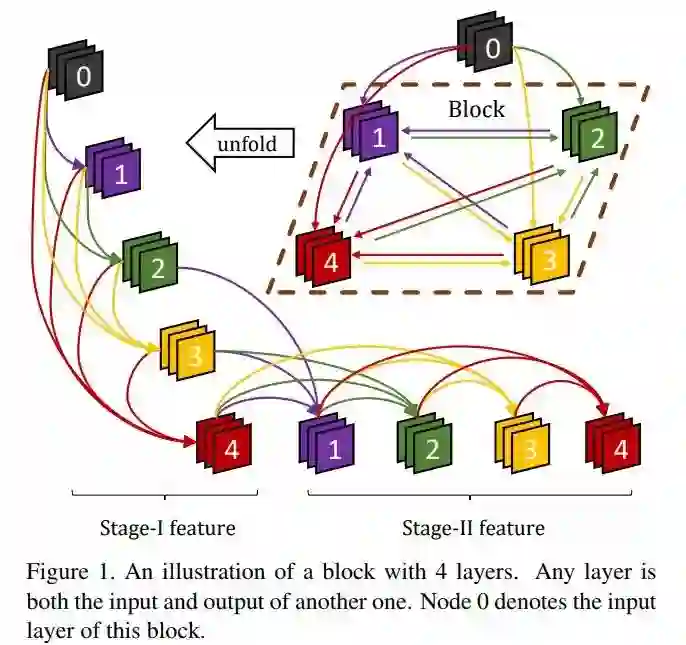
由于 block 内任意两层互连,故实现了 top-bottom refinement,也就实现了 attention 机制。
还提到了部分 technique:
1. channel-wise attention mechanism
2. Bottleneck and compression
#Object Detection
CVPR 2018 Oral, 今年 CVPR Landmark 和 Attention 这两个词出现的频率很高。
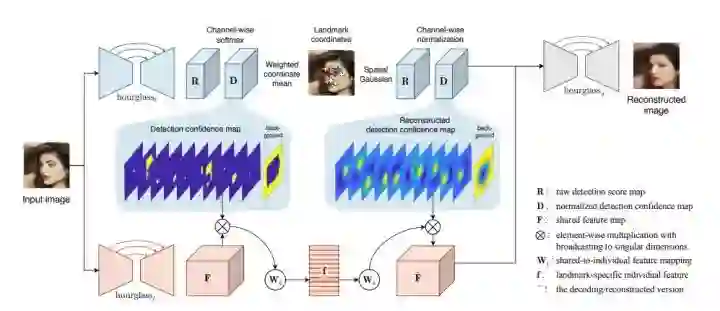
Landmark Detector
本文采用的是名为 hourglass 的网络构架,以图片作为输出,该网络输出 k+1 个 channel,含有 k 个 landmark 和背景。对不同 landmark 用 softmax 生成 confidence。
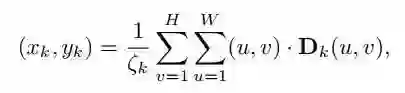
在如图公式中,Dk(u,v) 意思是第 k channel 中坐标为 (u,v) 的值,Dk 是 weight map,与对应坐标相乘,再除以总的权重和坐标乘积的和,从而生成该 channel 的 landmark 的 normalized 坐标。
Soft Constrain
为了保证我们生成的诸 landmark 及其坐标是表达的我们想要的 landmark 而非其他 latent repre,文章提出了几个 soft constrain:
1. Concentration Constrain:

计算两个坐标轴上坐标的方差,设计如图示 loss 是为了使方差尽可能小。

这里做了一个近似,使之转换成了 Gau dis,更低的熵值意味着 peak 处更多的分布,换句话说,就是使 landmark 尽可能地突出出来。
2. Separation Constrain:
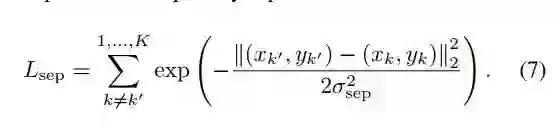
由于刚刚开始训练时候的输入时纯 random distribution,故可能导致提取出的 landmark 聚集在中心,可能会导致 separation 效果不好,因此而落入 local optima,故设计了该 loss。
这个 loss 也不难理解,将不同 channel 间的坐标做差值,使得不同 landmark 尽可能不重叠。
3. Equivariance Constrain
这个比较好理解,就是某一个 landmark 在另一个 image 中变换坐标时应该仍能够很好地定位,在这里,作者介绍了他们实现 landmark 变换坐标的几个trick。
4. Cross-object Correspondence

本文模型认为不能保证同一 object 在不同情况检测时绝对的 correspondence,文章认为这应该主要依赖于该特定 pattern 能够在网络生成的激活值展现一定的共性。
Local Latent Descriptors
这个 des 的目的是解决一个 delimma:除了我们定义的 landmark,可能还有一些 latent representation,要复原一个 image,仅仅 landmarks 是绝对不够的,所以需要一些其他的信息作为一个补充,但表达他们又有可能影响 landmark 的表达。

在这里,文章又用了另一个 hourglass network,如图中左下角的 F,就在我们之前提到的 concentration costrain 中,用一个高斯分布来将该 channel 对应的 landmark 突出出来。
在这里,文章将他当做 soft mask 来用,用 mask 提取后再用一个 linear operator 来讲这些 feature map 映射到一个更低维的空间,至此,local latent descriptor 就被生成了。
Landmark-based Decoder

第一步,Raw score map.
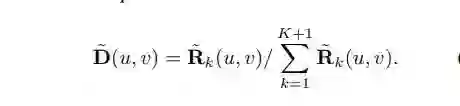
第二步,normalize.
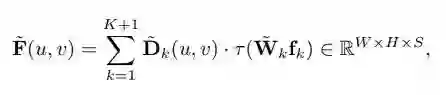
第三步,生成最终图像。
在这里,wk 是 landmark-specific operator。
简言之,Dk 是我们提出的 landmark 位置信息,fk 是对应 landmark 的 descriptor。
这里又提到了一个 dilemma:在用 mask 的时候,越多的 pixel 被纳入是最理想的,但纳入太多又使得边缘的锐利不能体现,因为该文用了多个不同的超参数来尝试。
#Object Detection
CVPR 2018 Oral,如下图,文章主要解决网络处理不同 scale 图片的网络策略。
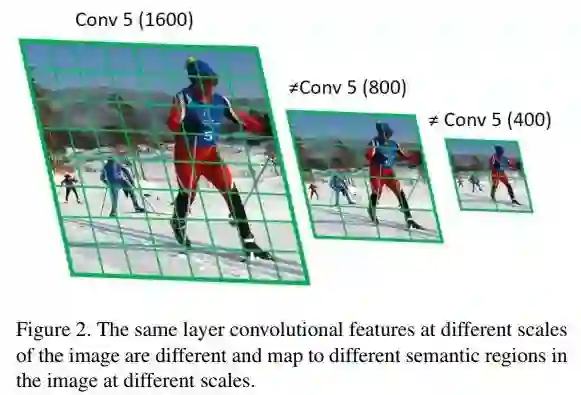
▲ 读图中配字,理解文章针对的问题

▲ 图2

▲ 图3
如上面两个图示,三种网络的训练方式和效果一目了然。
结论是:当我们要检测小的物体时,在输入是大的 scale 的网络上预训练、在高分辨率作为输入的网络上预训练、在upsample后的图片作为输入的网路上预训练,对检测小物体有益。
第 4 部分讲了用了 DeformableRFCN 模型,第 5 部分主要讨论了在不同分辨率下训练,在同样的高分辨率 test 的结果及其分析:

1. 在中分辨率下训练的模型比在高分辨率下训练的模型效果差,原因很简单,因为后者训练测试的分辨率相同,但并没有拉开很大的差距,为什么呢?因为中高 scale 的 object 被变得太大以致不能被检测到;
2. 作者随后在高分辨率下训练了只针对 80pixel 下 Object 检测的模型,但结果比在中分辨率下的效果差了很多,为什么呢?因为忽视中高 scale 的 Object 对训练影响非常大;
3. 作者又用多分辨率训练模型(MST),但仍因为过小或过大的 Object 影响,效果仍不理想。
Scale Normalization for Image Pyramids
第 6 部分,作者提出了最终的模型。该模型的输入分辨率最低 480*800,最高 1400*2000,对于训练中过大或者过小 scale 的 Object,模型选择直接忽略,训练只针对在 scale 的一个范围内的 Object。
后面就是训练细节和 trick,详情可以翻看论文。
#Introspective Neural Networks
CVPR 2018 Oral,同时也是目前为止个人印象最深刻的一篇文章。
文章主要做的事情就是提出了基于 Wasserstein 的 INN,该组已经在 ICCV,NIPS 等多次提出并改进该模型,该模型主要做的就是将 GAN 中的 G 和 D 结合起来。
文章最开始给了一下最基本的 notation,然后介绍了如何将 INN 与 Wasserstein 结合起来并给出了必要的数学证明。

▲ 算法

上图为分类过程 loss 的设计,图中两个公式,前者是目标函数,很容易理解,后者则是正则项,正则项是以随机的 a 来生成真数据(x+)与生成的假数据(x-)的 mixture。
合成部分

合成部分的公式中,简言之,就是以生成图与原图的相似度作为衡量标准。
图中引用的 21,29 是作者的前面两篇文章,分别是 NIPS 2017 和 ICCV 2017,作者在这篇文章中并未给出任何证明,后期本人应该会补上这两篇的笔记。
#Action Recognition
CVPR 2018 Oral,本文思路很清晰且已读,具体细节可以看文章,这里仅仅把总体思路讲一下。
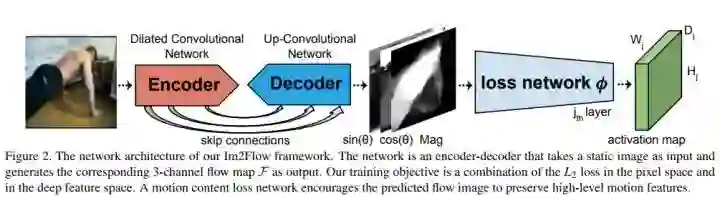
用 u-net 训练一个模型:输入是一个静态的帧,输出的预测的五帧光流信息,模型在 YouTube 数据集上训练。
该模型 loss 分两部分,一部分是将生成的五帧光流信息与 YouTube 数据集的 groundtruch 对比,另一部分是将生成的光流信息与真实的光流信息送进某网络(在 ucf101 上预训练过的 resent)计算欧式距离;前者是要求准确,后者是为了更好保留 high-level 的动作信息。
最终将 rgb 和预测的光流作为标准 two-stream 模型的输入进行预测。
#Deep Spatiotemporal Representations
CVPR 2018 Zisserman 的新论文,这篇文章就是 two-stream 模型中间层的可视化方法,换句话说,就是探寻 two-stream 模型学到了怎样的时空信息。
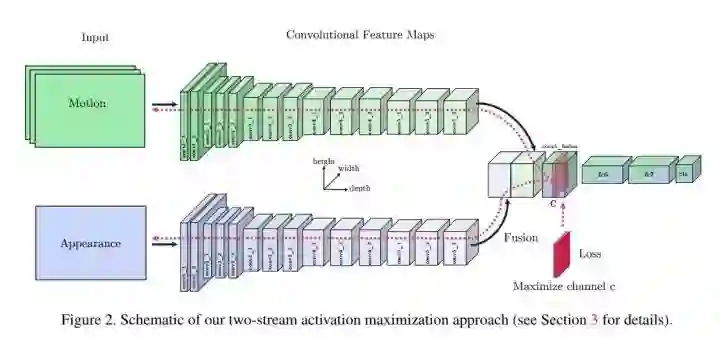
生成总共分为两个步骤,详情如上图:计算出输入的偏导,将计算出来的梯度用学习率 scale 并加到当前输入上。
Activation Maximization

本文还提到了两个正则方法:
1. 防止过大的值

2. 限制低频信息

#Neural Networks
今年的 Oral,令人印象深刻的一篇文章,网上解读很多,相当于在 channels 上加了一个 attention 机制,给不同的 channel 不同的权重。
这篇文章行文思路清晰,哪怕学习写论文也要看一看。
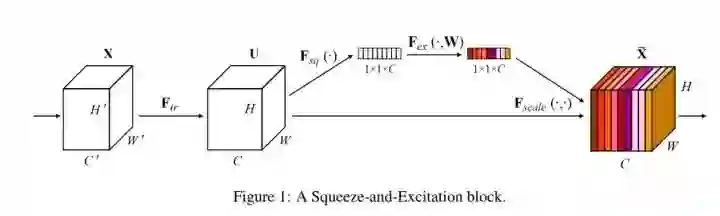
Squeeze
简言之就是全局平均池化,是因为低层的感受野太小导致效果差。
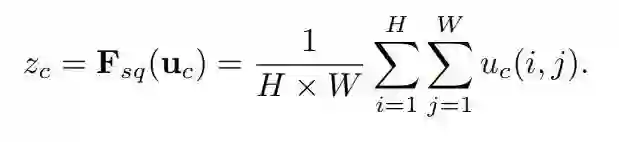
Excitation
这个环节主要是搞清 channels 之间的关系及重要性。这里作者提出了两个要求:
1. 灵活,作者解释:能够学习 channels 间非线性的关系;
2. 必须学习一个非互斥关系,因为设计的 block 是为了强调多个 channels 而非一个。

这里设计了两个全连接层,一个降维,一个升回原来的维度。对于降维再升维,作者给出的解释是为了降低计算复杂度和协助泛化。
#Video Object Segmentation
CVPR 2018 Oral,本文定义了一个新的任务:给出一个句子,根据该句子分割视频中的 actor 及其 action。
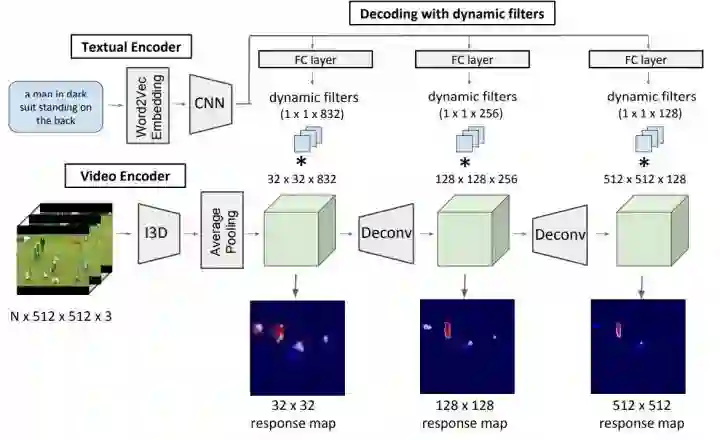
主要有三大部分:
1. Textual Encoder:使用 word2vec 的预训练模型,句子中的每个词被编码成 1x300 的 vector,一个句子则声称 nx300 的 matrix,通过 padding 使句子们 size 统一,网络构造详情见文章;
2. Video Encoder: encode the actor and its action. 网络构型采用 state of the art 的运用 3d filte r的 I3D model,后面又提到 follow 了 two stream 模型,未做很多解释,只说同时学习 RGB 和光流信息;
3. Decoding with dynamic filters:这里又提到了 dynamic conv filters,这是我第二次见到这个,感觉还是有必要读一下,若网上解读不多,会后期发出笔记。

为了保持同样的分辨率,使用了 deconv,deconv 的应用上有一些创新和 trick,详情请翻读论文。
模型的训练
训练时模型的输入:视频片段,sentence,segmentation mask。
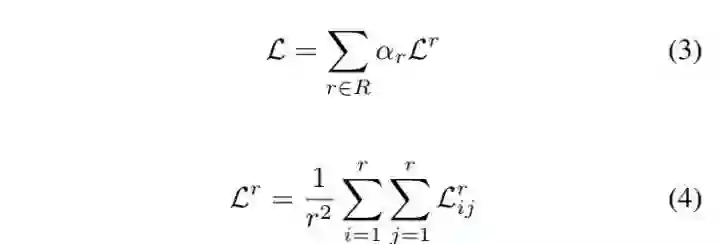
▲ loss function
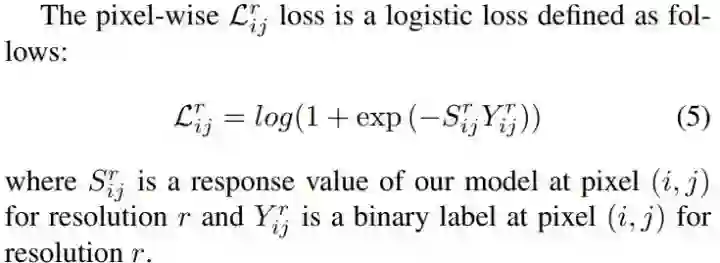
公式中的 r 表达的是不同的分辨率,作者解释是将多个分辨率纳入考虑,形成一种类似 skip-connnection 的效果。
#Visual Question Answering
CVPR 2018 Oral,主题是 attention+VQA,这是笔者作者读的第一篇关于这个领域的问题,可能难免会有讲得不够透彻的地方,欢迎批评指正和讨论。
本文的主要思路是用 faster-rcnn 提取出 proposal,然后用其做 image captioning 或者 VQA,该方法取得了 2017 VQA Challenge 的第一名。
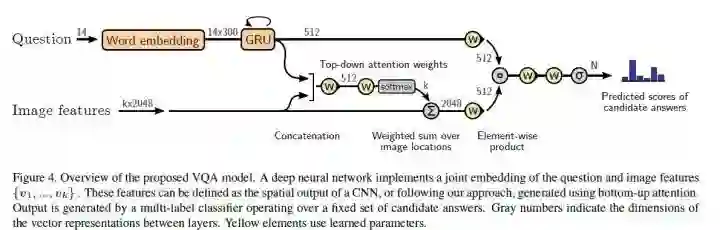
Bottom-Up Attention Model
简言之,该部分就是直接复用了 faster-rcnn,提取出超过特定阈值的区域,并提取出其平均池化特征。
Captioning Model
在这里作者提到,该文的 captioning 系统即便在没有基于 faster rcnn 的前提下,也有着相当好的体现,具体效果可以看 experiment 部分。
该部分作者未能讲得非常透彻,主要是对 NLP 理解相当有限,后面会更新这部分的讲解,这部分主要做的事情是用两层 lstm,以 faster rcnn 生成的 feature 和 sentence 做输入,生成对应 features 的 attention weights。
该部分由两层 LSTM 组成:
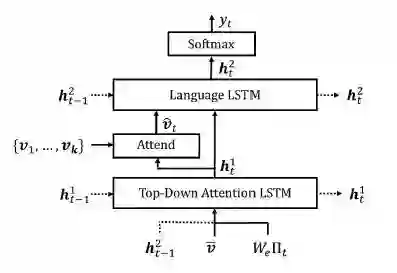
▲ h的右上标的12分别代表attention,language lstm的输出
1. 第一层 LSTM:top-down attention
在这里直接将 faster-rcnn 阶段生成的 region feature 称为 V,该层的输入时将:平均池化后的 v,上一时刻 language LSTM 的输出,之前生成的 words,concat 起来。
对于某一个时刻 attention lstm 的输出,生成一个 normalized attention weight,如下图:

2. 第二层 LSTM:language
该层将 faster-rcnn 阶段生成的 region feature 与 attention LSTM 的输出 concat 起来作为这一层的输入。

▲ 很容易理解,不做解释
3. Objectives
该部分作者只是引用并复用了已有方法。
VQA Model
先将问题用 GRU encode 成 the hidden state q,这个 q 又当做 top-down 系统的输入,即上面提到的两层 lstm,生成 attention weight。
#Visual Question Answering
CVPR 2018 Schedule 上的第一篇 Oral,这篇文章主要定义了一个新的 task 并给出了一个数据集。
任务定义:将一个 agent 随机丢进一个房间,向他提出一个问题,这个 agent 需要自己导航并回答问题。


▲ 问题类型,大家可以大致理解下
数据集问题,场景的生成都是用已经存在的 method 生成的,详情可以翻阅论文。
这个 task 总体来说对于 agent 提出了四个要求:vision,language,navigation,question answering,文章还给出了各个部分的具体结构,很容易理解。

▲ 训练策略
#Transfer Learning
CVPR 2018 Oral,本文定义了一个新的任务,针对在视觉内的迁移学习,并提出了一个蛮大的数据库,然后还有 Malik,Savarese 两位大牛挂名,感觉很值得关注。
定义的任务是这样的:vision task 类目很多,只针对某个问题来解决的话,会需要很大的标注的数据集,但我们不难想到的是,一个视觉任务的解决应该能够一定程度的解决另一个视觉任务,毕竟一个成熟模型的构建意味着对该 image 的一定的理解,而这部分的理解的一部分或许对另一个 task 有助益,例,物体 relation 的理解对深度信息的学习毫无疑问是有着助益的。
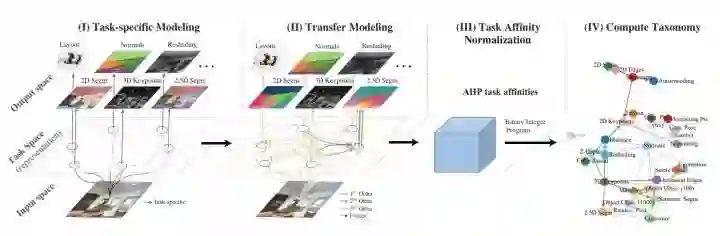
首先做一个 notation 说明:source task 是指我们已经有着足够标注数据集或者信息,能够解决的问题,target task 则是指待解决,希望通过前者的迁移学习来解决的问题。
有三个阶段:
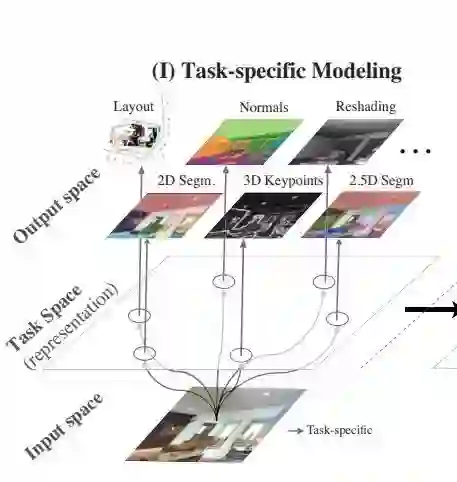
Step I: Task-Specific Modeling
encoder-decoder 结构,不需过多解释。
Step II: Transfer Modeling
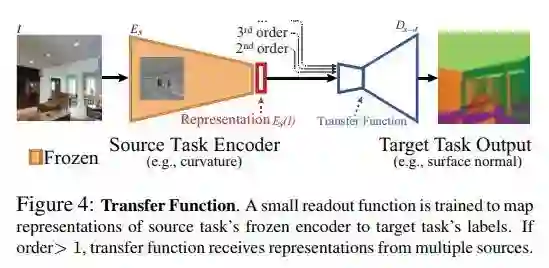
这里的 transfer function 就是一个 decoder,他的输入时多个 source task encoder 的 encoder 的输出。
这里作者提出了设计时应当考虑到的因素:
1. accessibility:首先,应该含有潜在的能够解决 target task 的信息,因此文章设计了一个小结构,用其基于小规模数据测试 accessibility;
2. higher-order transfers:多输入,过滤掉有着更低 contribution 的 representation 的 filter 策略;
3. transitive transfers
Step III: Ordinal Normalization using Analytic Hierarchy Process (AHP)
简言之,就是计算不同的 source 对一个 target task 的贡献度。
Step IV: Computing the Global Taxonomy
计算全局的一个 contribution graph。
#Convolutional Neural Networks
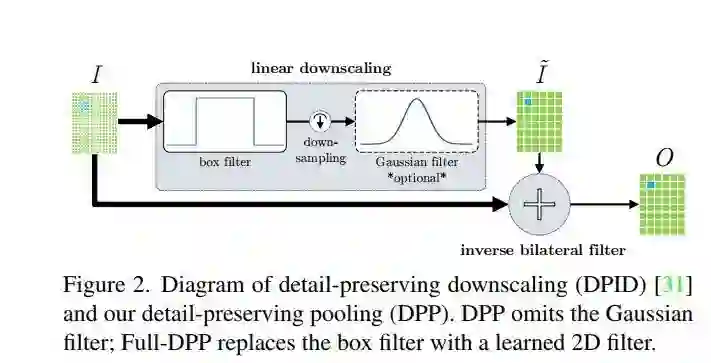
CVPR 2018 Oral,顾名思义,提出了保留 detail 的池化方法。
max/avg pooling 一个只选取最大而忽略与周围像素的关联性,一个重视关联性却又直接抹平,并且在实际梯度计算中也有一些 drawback,所以该文提出了这个新方法,一句话概括,就是在池化过程中学了一个动态的 weight。
Notation:在此,我们以 I& 代替文章中出现的,ID 代指
。
Detail-Preserving Image Downscaling
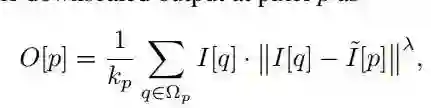
▲ I是原图,O是output,[]表示取对应坐标像素值

▲ 如图所示,ID是用近似高斯分布的filtersmooth后的图像
作者总结:DPID 计算的是 weighted average of the input,周围的像素中,越近或者 difference 越大的值能够给最终的 output 更高的 contribution。
以上这一部分是一个铺垫。
Detail-Preserving Pooling
作者这部分就是将上一部分提出的 downscale 思想转化成文章的 DPP(如 title) 简言之,就是将上部分中的 L2 NORM 替换成一个可学习的 generic scalar reward function。
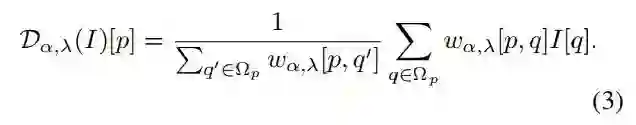
首先给出 weight 的表示:
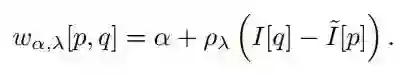
▲ α和λ就是我们要学习的参数
这里用了 constrain 来保证两个参数为非负。
这里给出了两种 reward function:
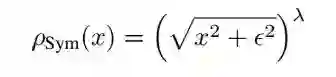
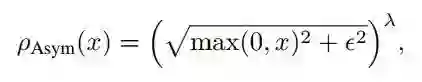
▲ 这里为了简洁,将λ省略掉了
可以看到,相对而言,后者更倾向与给比中心像素高的像素更高权重,前者则是给差距大的更高权重。
后面,作者又补充了 I& 的生成:
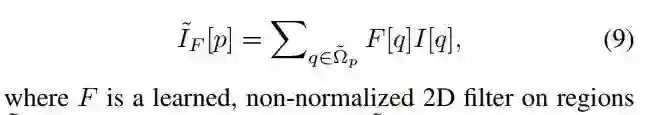
#Image Synthesis
CVPR 2018 Oral,本文解决了 GAN 生成高分辨率突破的问题,分辨率达到了 2048*1024,方法精细,值得深入来看。
先来看 Generator:
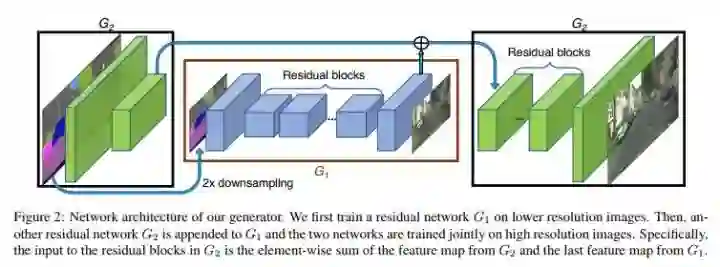
如图所示,中间部分的 G1 在低分辨率情况下训练,然后在前后又分别加上 G2,注意左边部分的 G2 的输出和 G1 的输出 concat 之后,作为右边 G2 的输入。
再来看 D:这里的 discriminator 是 multi-scale,有着三个针对不同尺寸的 D,三个尺寸分别是原尺寸,二分之一,四分之一。 放缩尺寸的理由不难理解,receptive field 大小的问题。

▲ objective中,三个D都纳入考虑
Improved Adversarial Loss
一句话概括:在 D 的中间多个层抽取 feature map,作为分类和训练依据。
Using Instance Map
个人认为是本文最 inspiring 的一点,先放对比图。
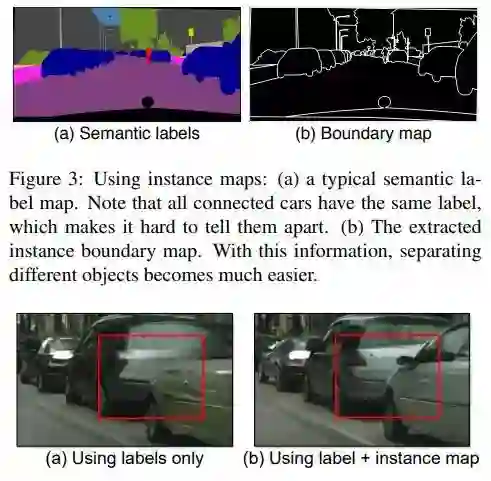
图胜千言,boundary map 一方面更加精细,也对边缘的处理上给出了看起来很理想的解决方案。具体的对比解释可以去文中寻找。
b map 的提取不难理解,主要是基于 semantic labels。
Learning an Instance-level Feature Embedding
这部分是基于前面提到的 instance level 信息,做一个精细化的 embedding。在 generator 的输入中,除了 ori img,boundary map 之外,还有 low-dimensional feature。
为了生成这些 low-dim feature,作者又设计了一个标准的 encoder-decoder 来生成。在这个 encoder 训练好之后,还用生成的特征做了一个聚类,从而可以控制生成图片的 style。
#Data Augmentation
CVPR 2018 Oral,简言之,就是用 GAN 生成新数据。
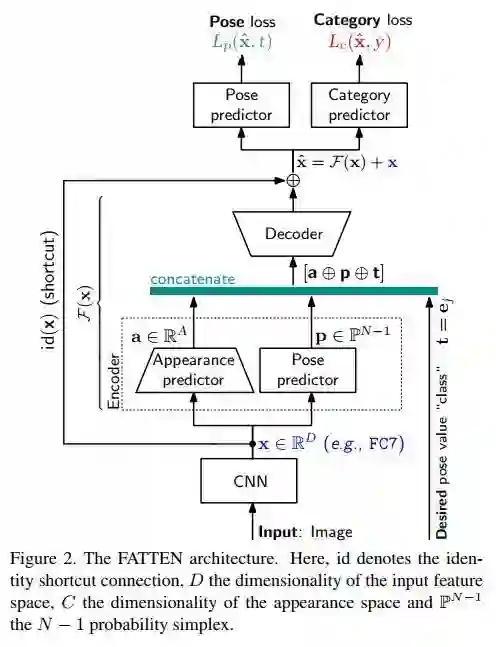
结构没太多新意,也不会很难理解,就是在 appearance 和 pose 上分离。
在网络设计上,作者提到了三点:
1. 为了避免网络只是单纯的 match feature pairs,如上图所示,只是学习 the residual;
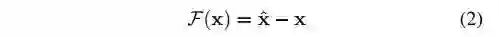
▲ 即source和target的feature vector的差
2. appearance 和 pose 分开训练,pose 的学习便可以全监督训练学习;
3. appearance 和 pose 分开训练,能够使对这两个属性的学习上更加 balance。
#GAN
CVPR 2018 Oral,首先要解释一下 domain 的定义:
这里的 domain 是指针对数据集中的 attribute,根据 attribute 来划分的,比如就性别这个 attri 而言,男是一个 domain,女是一个,相对于发色而言,金发是一个 domain,黑发是一个 domain。
随后作者提出,如果要 cross domain 来训练 GAN,太麻烦了,n 个 domain 需要 n(n-1) 个 translator,作者在本文提出了一个可以解决 multiple domain translation 的 translator。
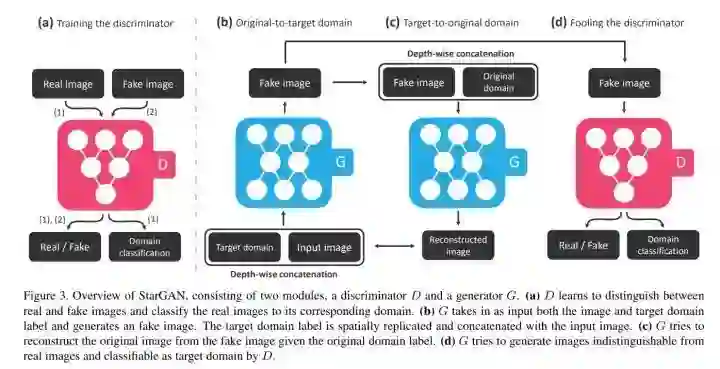
▲ 整个网络结构,下面文字讲得很清楚了
Adversarial Loss:这部分设计无太多新意。
Domain Classification Loss:简言之,分成了两个部分,第一个部分负责在 D 讲 real img classify 到正确 domain label,第二个部分,则是负责激励 G 将 fake img 向 target domain label 靠近。
Reconstruction Loss:简言之,就是 cycleGAN 采用的那种 loss,具体请参见 cycleGAN,是为了保证 cross-domain 过程中只更改我们想要更改的部分。
#Zero-Shot Learning
CVPR 2018 Oral,Zero-Shot Learning 就是寻求将学习到的特征映射到另一个空间中,从而 map 到 seen 及 unseen 的属性或者 label 上。
这篇文章的主要亮点在于学习了已定义label的同时,学习了latent attribute(隐含属性)。
已有方案的 drawbacks:
1. 在映射前,应当抽取 image 的 feature,传统的用 pretrain model 等仍不是针对 zero-shot learning (ZSL) 特定抽取特征的最优解;
2. 现有的都是学习 user-defined attribute,而忽略了 latent representation;
3. low-level 信息和的空间是分离训练的,没有大一统的 framework。
本文便是对应着解决了以上问题。
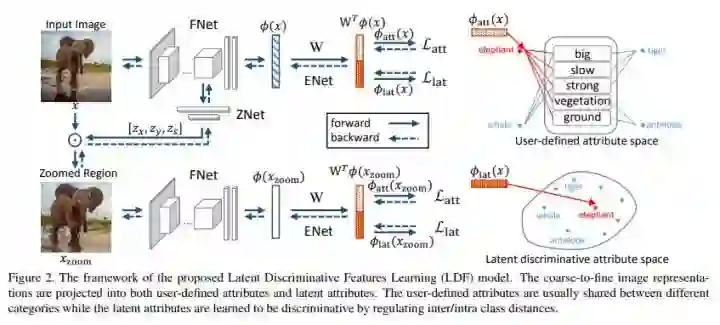
Notation:
FNet:抽取 img 的 feature;
ZNet: 定位最 discriminative 的区域并将其放大;
ENet:将 img feature 映射到另一个空间。
下面我们先介绍各个子网络 :
FNet (The Image Feature Network)
这部分直接借用了已有的 VGG19、GoogleNet,不细讲。
ZNet (The Zoom Network)
这里的目的是定位到能够增强我们提取的特征的辨识度的r egion,这个 region 同时也要与某一个我们已经定义好了的 attribute 对应。
ZNet 的输入是 FNet 最后一个卷积层的输出。在这里运用某个已有的激活函数方法,将我们定位好了的 region 提取出来,即将 crop 操作在网络中直接实现。
然后,将 ZNet 的输出与 original img 做 element-wise 的乘法,最后,将 region zoom 到与 original img 相同的尺寸。
如图,再讲该输出输入到另一个 FNet(第一个 Fnet 的 copy)。
ENet (The Embedding Network)
这里作者提出了一个 score 用于衡量 img feature 和 attribute space 的相似性(兼容性)。


ENeT 将 img feature 映射到 2k dim 的空间中,1k 是对应于已经定义了的 label,并用 softmax loss。另 1k 则是对应潜藏属性,为了使这些特征 discriminative,作者使用了 triplet loss。
#Object Detection
CVPR 2018 Oral,本文设计了一个考虑 relation 的 module,来增强 object detection 的性能。
对于每一个 object,都将其余所有 object 的 appearance 和坐标纳入考虑,增加在已有的 feature 上。
文中以倒推的方式给出表达,首先是最终表达(n-th Object 的 relation feature):
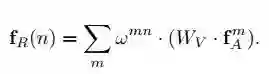
▲ fA的上标m是指第m个
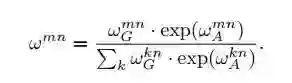
▲ 式子左边的值是其余objects对这个Object的影响
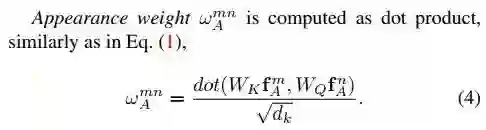
▲ 本式的更具体解释清翻看论文
再一点就是 fG 的处理:
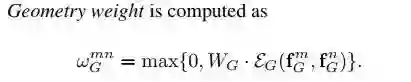
这里有两步,首先将两个物体的 fG 映射到高维表示,即 εG。
第二步则是将该特征用 wG 映射到 scalar weight,max 的使用起到了类似 RELU 的作用,对几何关系表示的权重做了一个限制。
再一个就是为了保证几何特征在变换中的不变性(invariant to translation and scale transformations),做了如下变换:
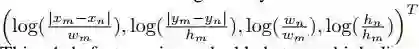
再将上图特征做了一个映射,映射过程未做过多解释,只是做了一个引用。该文与其他类似方法最大的区别便是将几何信息纳入考虑。
最终的表示不难理解:
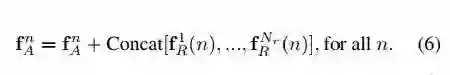
就是将某一物体原有的 appearance feature 和其余所有 Object 与该物体的 realation feature 加起来,为了保证维度一直,在 relation feature 生成时就已经将 feature 维度压缩,从而 concat 之后的 relation feature 与 fA 对应。
随后给出了证明,该 module 输入输出维度一致。
总得来说,这篇笔记还不够透彻,后面会更新更补充,核心思想就是将文中引用的 scaled dot product attention 做了一个应用。
#Image Synthesis
CVPR 2018 Oral,来自 CUHK,这里设计的模型以 semantic layout 输入,输出真实的相片般的图片。

▲ 最上面一排是输入,下面是输出
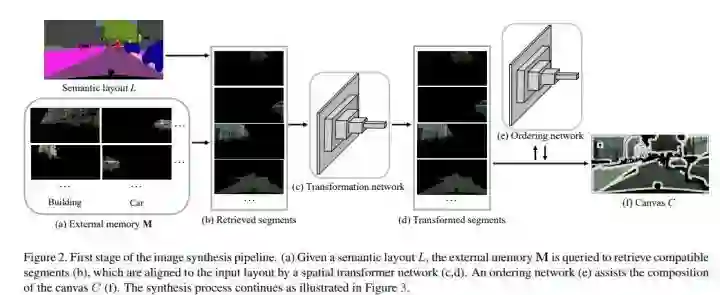
模型的训练基于是由 layout 和 color img 组成的 pair,用这样的 pair 生成 memory bank。
Notation:我们用 M 表示 memory bank。
test 的时候,对于一个 semantic label map,我们的模型将其 segment,并从 M 中基于形状等信息找到对应的component。match 的块的填充将要被填充到一个 canvas 上,由一个网络完成;为了预防重叠,设计了另一个网络来设计填充的顺序。
canvas 和 input layout 作为 synthesis network 的输入,生成最终的输出。
M 的表示
所谓的 memo bank 就是 segments 的一个 bank,基于 semantic label map 生成。
每一个 segment 定义了三个属性,颜色,binary mask,semantic map(该 segment 周围的 context,并在一个 bounding box 范围内)。
Retrieval
对于一个新的 semantic layout,对于每一个 segment,计算出上面提到的三个属性,基于下面的 score 计算方法, 从 M 选出最 match 的块:
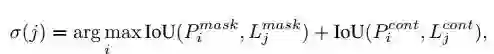
▲ 两个iou分别衡量的是segment本身shape,该segment周围context
Transformation
在本阶段,通过旋转,放缩等变换,将选取的 segment 变得更加 match。
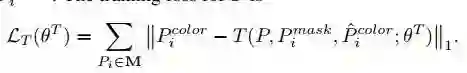
▲ objective
test 的时候 segment 之间不是完美契合的,所以训练的时候我们的训练数据也应当是不完全契合的,故直接用 mask 来做 map 是不行的,这里作者用 random affine transformation。

Canvas
这一阶段则是将 transform 后的 segment 放到一个 canvas 上,为了解决重叠问题,设计了一个 ordering network,这里的思路挺让人耳目一新的,为了训练这样一个网络,使用了深度信息,对于没有深度信息的数据集,则是使用预测 depth 信息的网络生成。
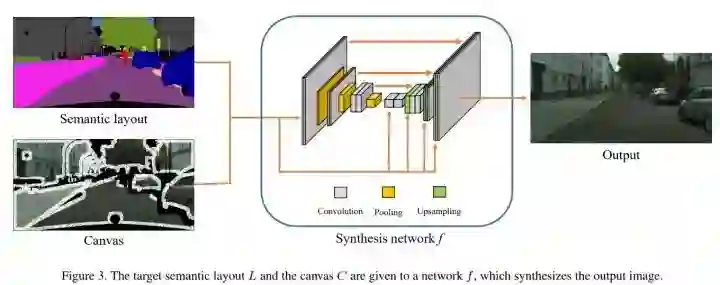
Image Synthesis
The image synthesis network f takes as input the semantic layout L, the canvas C, the target semantic layout and a binary mask that indicates missing pixels in the canvas.
#Action Recognition
CVPR 2018 Oral,Pose 合成。
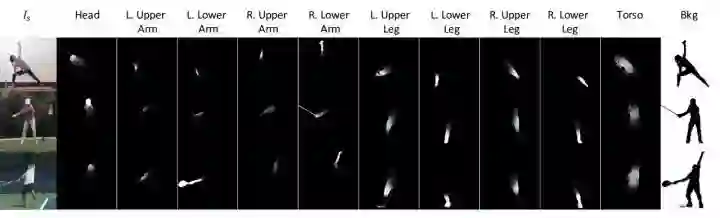
网络的输入是 original img,original pose,target pose,并预设 original img 和 target img 背景一样,人是同一个。 首先前后景分离,然后针对前景(即人),针对身体的不同部分做细致的 segment。
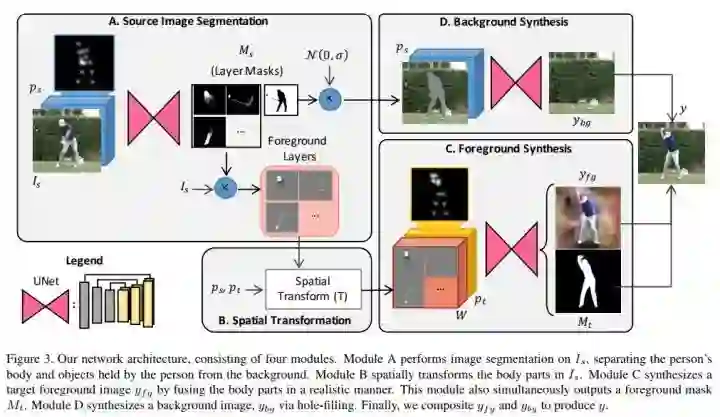
Pose Representation
人身体的 pose 用 14 个 dots 表示,在 dots 处还加入了高斯噪声,有利于 regularization,且有利于网络更快学习到这个特征。
Source Image Segmentation
分前后景,前景又对应着已经定义好了的身体部分(10 个)。采用 u-net,输入是 original img 和 pose 的 concat,输出是各个部分的 mask。
Foreground Spatial Transformation
这一过程则是将分割后的 segment 和 target pose 一一对应起来,并作相应的旋转,放缩等。
Foreground Synthesis
前一阶段我们已经根据 target pose 将各个 segment 位置变换好了,简言之,就是把人的是个部分拆开来,然后根据目标姿势重新组合,这一步则是将其彻底的合成,使其具备和真实照片一眼的一致性。
也是用的 u-net,输入为 target pose 和已经 segments,输出时 foreground 和 target mask。
Background Synthesis
这部分则是处理新的 target 之间的孔洞,无新意。
Loss Function
两部分组成 VGG LOSS:将 VGG19 的前 16 层的输出 concat 并计算 L1 距离。传统的 GAN loss。

点击标题查看更多论文解读:

▲ 戳我查看招聘详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 访问作者知乎专栏



