【VALSE 前沿技术选介17-09期】自监督学习近期进展
什么是自监督学习?为什么需要自监督学习?
简言之,自监督学习是一种特殊目的的无监督学习。不同于传统的AutoEncoder等方法,仅仅以重构输入为目的,而是希望通过surrogate task学习到和高层语义信息相关联的特征。这方面的研究得到了大量顶级研究组的关注,一个详尽的survey参见我之前的一个talk:http://winsty.net/talks/self_supervised.pptxhttp://
Representation Learning by Learning to Count
这篇文章希望通过spatial equa-variance的信息来做self-supervised learning,即一张图片分成若干部分后得到的特征求和,应当等于整个图片直接的特征求和。数学表达如下:
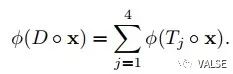
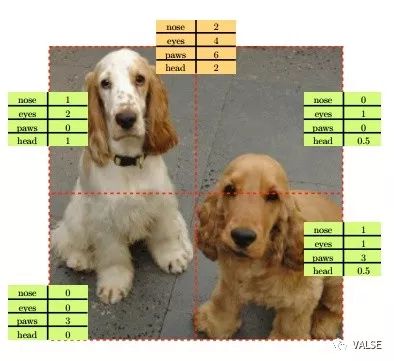
一个直观的解释便是这样一个方法其实是在“数”一些重要元素的个数,这些元素的个数是满足这样一个equivariance性质的。个人觉得这样的解释过于牵强了,这一点在后续中也会提到。文章中的例子,如下图所示:
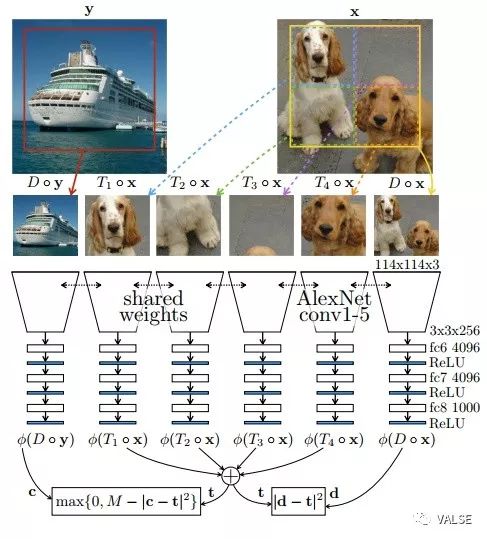
在实际操作中,如果没有别的约束,这样的学习方式一定会导致trivial solution,即所有输出全为0 。为了避免这样的问题,作者在目标函数中还加入了另外一个负样本作为约束限制,即要求这若干部分的特征求和和任意sample的一张不相关图片的特征表示差异尽量大。整个方法的示意图如下:
文章中一些有趣的观察包括:
在ImageNet和COCO上,最后fc的1000个输出中,虽然只有30和42个非零元素,但是在卷积层学到的特征仍然对于后续分类/检测/分割任务起到了极大的帮助。
在学习过程中,网络不应该区分出不同的输入是来自于crop还有downsample。否则CNN可能会使用一些low level feature来满足这样的学习条件,而不是我们希望的semantic feature。(个人觉得作者在这里举的例子并不恰当,所以不在这里列出。)所以作者使用了随机选择downsample方法和灰度图来缓解这个问题。
不出意外,通过这样预训练得到的特征可以帮助后续High level vision的任务的性能。在可视化neuron的过程中,作者发现在最后层输出“counting”特征的norm比较大的图片一般都对应有明确的语义信息,比较小的一般都是low level纹理或颜色。但是其实这里存疑的是,low level的纹理其实也可以对应着明确可以counting的信息,如下图所示,(a) (b)分别对应ImageNet数据集中最高和最低的图片,(c) (d)对应COCO数据集。可以明显看到就算在norm较低的样本中,也存在大量可数的物体。所以个人觉得counting的这个解释是十分牵强的。

Transitive Invariance for Self-supervised Visual Representation Learning
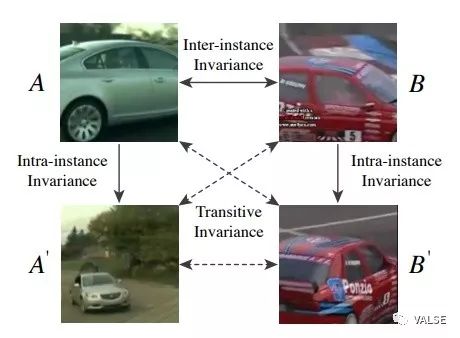
利用Context类和Video类的self-supervised方法其实本质上是互补的:Context类的方法,如预测相当位置或拼图,对于inter-instance的变化有很好的适应性,例如同一类物体之间的一些;Video类的办法对于intra-instance的变化,例如pose,viewpoint等具有很好的适应性。这篇文章呢,其实就是希望这两种办法取长补短,能够拓展出更多的training data。如下图所示:
在具体实施过程中,作者并不是简单地通过multitask来同时进行两种self-supervised learning,而是通过一个逐步构建similarity graph的方式来拓展训练集。在拓展后的训练集上,再使用一个Triplet Network(一对相似样本,和一个sample出的负样本使用Triplet Loss)来做特征学习。学习的过程相对来说传统,所以就不再赘述,下面主要介绍一下前面构建similarity graph的方式。
首先,作者在Youtube 100K数据上找到moving object proposal,然后在这些proposal上通过训练好的inter-instance模型,对训练集中所有的样本计算特征。由于样本集数目巨大,为了保证每个sub-cluster的purity,作者提出了two stage的方法:首先通过kmeans首先进行粗略聚类,然后对于每个样本,在大类内找出10近邻。为了保证足够高的精度,在此之后,作者去寻找了所有的大小为4的全连接group(即,这4个样本分别在剩余3个样本的10NN中)。通过这样的办法,可以至少保证每个sub-cluster在inter-instance模型中很相似。随后再从这些样本,通过tracking的方法拓展出去,去挖掘同样instance的intra-instance变化。这样就可以传递这些相似性到同类但不同pose不同viewpoint的样本中去了。一个直观解释如下图:
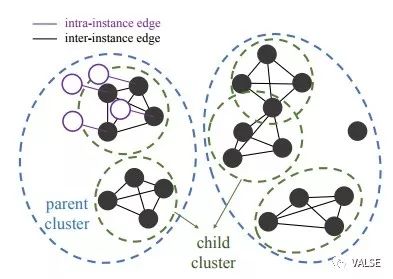
在实验中,这个方法在PASCAL VOC和COCO检测任务中得到了非常接近于ImageNet pretrain model的结果,在另外的Surface Normal Estimation任务中,成功超越了ImageNet pretrain model,足以证明结合两种视角的self-supervised方法的威力。
Multi-task Self-Supervised Visual Learning
这是一篇更偏向工程性的工作,花了大量的精力同时训练不同种类互补的self-supervised任务以期待得到最好的feature learning结果。这些互补的self-supervised任务包括:1)预测相对位置 2)颜色预测 3)单样本学习 4)运动分割 。在多任务同时训练的过程中,使用了两种结构,一种是共享trunk网络,然后针对不同任务有不同head网络的传统方式;另一种通过对不同层的feature进行稀疏组合,以期待得到更大的灵活性。如下图所示:
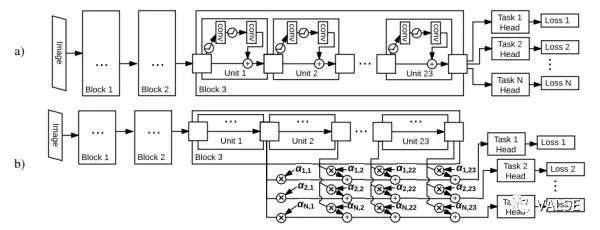
不同的alpha对应不同residual block相加的权重。除此之外,文章中还描述了大量训练细节,比如不同类型的任务需要不同输入,以及如何在多机之间能够完成大规模分布式训练等等,详情有兴趣的读者可以参见原始的paper,这里就不再赘述。
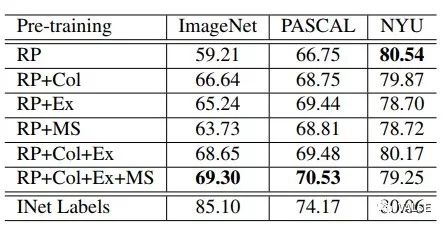
在实验中,作者在self-supervised方法中常用的几个任务中做了测试:ImageNet分类,PASCAL VOC detection,以及NYU Depth深度估计。一个有趣的趋势是在需要语义信息越强的任务中,融合多种任务得到的效果就会越好,在NYU Depth中语义信息相对来说不需要这么强的任务中,单任务甚至取得了最好的结果。
总结
可以看到现在self-supervised一个发展的趋势是往大规模,实用化发展,虽然现阶段在强语义任务上仍然比不上ImageNet大规模监督训练的结果,但是这两年差距在快速缩小,我们期待在不遥远的未来可以达到ImageNet Pre-training的结果甚至超越。




