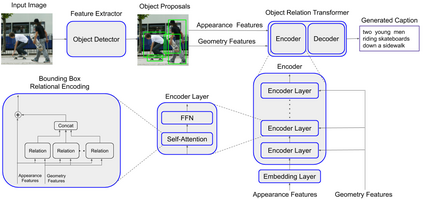
Image captioning models typically follow an encoder-decoder architecture which uses abstract image feature vectors as input to the encoder. One of the most successful algorithms uses feature vectors extracted from the region proposals obtained from an object detector. In this work we introduce the Object Relation Transformer, that builds upon this approach by explicitly incorporating information about the spatial relationship between input detected objects through geometric attention. Quantitative and qualitative results demonstrate the importance of such geometric attention for image captioning, leading to improvements on all common captioning metrics on the MS-COCO dataset.
翻译:图像说明模型通常遵循编码器-解码器结构,该结构使用抽象图像特征矢量作为编码器的投入。最成功的算法之一使用从一个物体探测器获得的区域建议中提取的特征矢量。在这项工作中,我们引入了对象关系变换器,该变换器以这种方法为基础,通过几何注意明确纳入关于输入检测到的物体之间的空间关系的信息。定量和定性结果表明,这种几何关注对于图像说明的重要性,从而改进了MS-COCO数据集上所有通用说明指标。