神经网络常微分方程 (Neural ODEs) 解析

在本文中,我将尝试简要介绍一下这篇论文的重要性,但我将强调实际应用,以及我们如何应用这种需要在应用程序中应用各种神经网络。
原标题 | Neural ODEs: breakdown of another deep learning breakthrough
作 者 | Alexandr Honchar
翻 译 | had_in(电子科技大学)、HERAT(中山大学)、王鑫雨(山东科技大学)
编 辑 | Pita
大家好!如果你正在读这篇文章,意味着你一直留意着AI前沿技术。今天所要谈及的话题来自于NIPS2018,而且这篇文章还是NIPS2018会议的最佳论文:神经常微分方程(Neural ODEs,论文地址:https://arxiv.org/abs/1806.07366)。在本文中,我将尝试简要介绍一下这篇论文的重要性,但我将强调实际应用,以及我们如何应用这种需要在应用程序中应用各种神经网络,如果可以的话。与往常一样,如果您想直接浏览代码,可以查看此GitHub储存库(https://github.com/Rachnog/Neural-ODE-Experiments),我建议您在Google Colab中启动它。
为什么我们关注常微分方程呢?
首先,让我们快速简要概括一下令人讨厌的常微分方程是什么。常微分方程描述了某些由一个变量决定的过程随时间的变化。这个时间的变化通过下面的微分方程来描述。
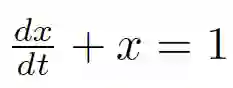
简单的常微分方程的例子
通常情况下,如果我们知道了某些初始条件(过程开始的地方),并且我们想了解这个过程将如何变化成某些最终状态,我们才能讨论解这个微分方程。求解函数也被叫做积分曲线(因为我们可以通过对这个方程积分得到方程的解x(t)).让我们尝试用SymPy软件包来解一下上面图片上的方程:
from sympy import dsolve, Eq, symbols, Functiont = symbols('t')x = symbols('x', cls=Function)deqn1 = Eq(x(t).diff(t), 1 - x(t))sol1 = dsolve(deqn1, x(t))
这将会得到下面的解:
Eq(x(t), C1*exp(-t) + 1)
其中C1为常数,可以在给定初始条件时进行确定。如果以恰当的形式给出微分方程,我们可以用解析法进行求解,但通常是采用数值方法求解。最古老和最简单的算法之一是欧拉法:其核心思想是用切线逐步逼近求解函数:
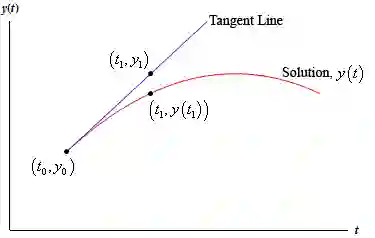
http://tutorial.math.lamar.edu/Classes/DE/EulersMethod.aspx
请访问上图下方的链接可以获得更详细的解释,在最后,我们得到了一个非常简单的公式,如下
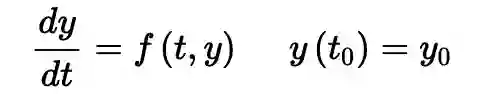
http://tutorial.math.lamar.edu/Classes/DE/EulersMethod.aspx
其在n个时间步长的离散网格上的解是
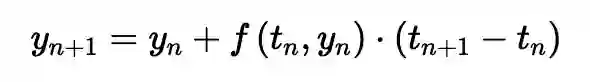
http://tutorial.math.lamar.edu/Classes/DE/EulersMethod.aspx
关于微分方程的更多细节,特别是如何用Python编写它们以及它们的解决方法,我建议你去看看这本书(https://www.springer.com/gp/book/9783319781440),在化学、物理和工业领域中也有很多这种时间演化过程的例子,均可以用微分方程来描述。此外,对于微分方程与ML模型相关的其他想法,请访问此资源(https://julialang.org/blog/2019/01/fluxdiffeq)。与此同时,仔细看看欧拉方程,难道它没有让你想起最近的深度学习架构中的任何东西吗?
残差网络是一种微分方程的解吗?
确实是这样的!y_{n+1} = y_n + f(t_n, y_n)就是ResNet中的一个残差连接,表示该层的输出y_{n+1}是f(t_n,y_n)本身的输出和该层的输入y_n的总和。
如果我们记住,这些残差连接是欧拉法离散化的时间步长,这意味着我们可以通过选择离散方案来调节神经网络的深度,从而使解(又名神经网络)或多或少的精确,甚至使它像无限层!
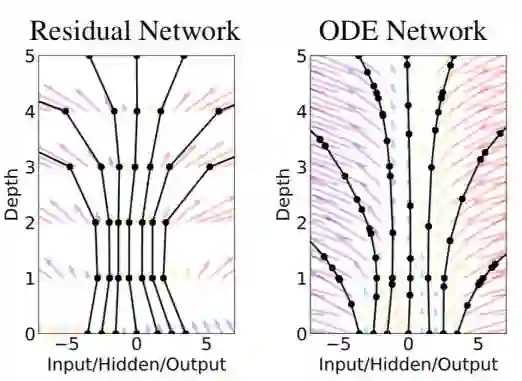
固定层数的ResNet与可以灵活改变层数的ODENet的区别
欧拉法是不是太粗糙了呢?的确如此,所以让我们用一些抽象的概念来代替ResNet / EulerSolverNet,比如ODESolveNet,其中ODESolve是一个函数,它提供了ODE(低调点:我们的神经网络本身)的解决方法,其精度比欧拉法高得多。现在的网络架构可能是如下所示:
nn = Network(Dense(...), # making some primary embeddingODESolve(...), # "infinite-layer neural network"Dense(...) # output layer)
我们忘了一件事…神经网络是一个可微函数,所以我们可以用基于梯度的优化手段来训练它。我们应该如何通过ODESolve()函数进行反向传播呢?在我们的例子中,ODESolve()函数实际上也是一个黑盒吗?在这里,我们可以利用一个由输入和动态参数组成的损失梯度函数。这种数学技巧叫做伴随灵敏度法。关于更多细节,我将参考原始论文(https://arxiv.org/pdf/1806.07366.pdf)以及这篇教程(https://nbviewer.jupyter.org/github/urtrial/neural_ode/blob/master/Neural%20ODEs%20%28Russian%29.ipynb),但其本质如下图所示(L代表我们要优化的主要损失函数):
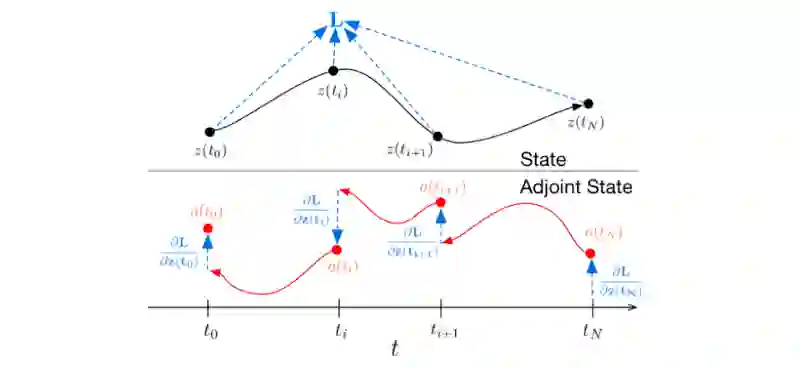
获得ODESolve法的反向传播梯度
简单地说,伴随系统除了描述初始的动态系统的过程外,还通过链式法则(这就是众所周知的反向传播法的关键所在),描述了反向过程中每一点的导数状态。正是通过伴随系统,我们可以得到微分的初始状态,并以类似的方式,获得一个描述动态系统的函数(“残差块”或欧拉法离散化过程)的参数。
神经网络常微分方程可能的应用场景
首先,让神经网络微分方程代替普通的残差网络的动机和优势如下:
存储效率:我们不需要在反向传播时存储所有的参数和梯度
自适应计算:采用离散化方案,既能平衡速度和精度,又能在训练和推理过程中保持不同的精度
参数效率:将相邻的“网络层”的参数自动连接在一起(见论文:https://arxiv.org/pdf/1806.07366.pdf)
标准化流,是一种新型的可逆密度模型
连续时间序列模型:连续定义的动态过程可以方便地接受任意时刻输入的数据。
根据这篇论文,除了将ResNet替换为ODENet用于计算机视觉之外,我现在认为有些还未应用的场景如下:
将复杂的微分方程压缩成单个的动态建模神经网络
将其应用于缺少时间步的时间序列
可逆标准化流(超出本博客的讨论范围)
这种方法也有一些缺点,请参考原论文。在介绍了足够的理论后,让我们现在看一些实际的例子。提醒一下,所有的实验代码都在这里(https://github.com/Rachnog/Neural-ODE-Experiments)。
学习动态系统
正如我们之前所看到的,微分方程被广泛用于描述复杂的连续过程。当然,在实际生活中,我们把它们看作是离散的过程,而且,最重要的是,在t_i的时间步上可能会丢失很多观察值。假设你想用神经网络来构建这样的一个系统。在经典的序列建模过程中,您会如何处理这种情况呢?把它扔给递归神经网络,甚至不需要进一步设计模型。在这一部分中,我们将检查神经网络微分方程如何解决这个问题。
我们的设置如下:
将微分方程定义为PyTorch的一个网络模块nn.Module()
定义一个简单的(或者不是完整的)神经网络,它将在从h_t到h_{t+1}的两个连续动态步骤之间建立动态模型,或者在动态系统的情况下,为x_t和x_{t+1}。
运行利用微分方程求解器反向传播进行的优化过程,并最小化实际动态过程和建模的动态过程之间的差异。
在接下来的所有实验中,神经网络都是如下所示(这应该足以用两个变量来模拟简单的函数):
self.net = nn.Sequential(nn.Linear(2, 50),nn.Tanh(),nn.Linear(50, 2),)
我们所有的例子都深受一个代码库(https://nbviewer.jupyter.org/github/urtrial/neural_ode/tree/master/)的启发,并这个代码库给出了非常好的解释。在下一小节中,我将展示我们所建模的动态系统如何利用代码进行可视化,以及系统如何随时间演化,以及ODENet如何拟合相位图。
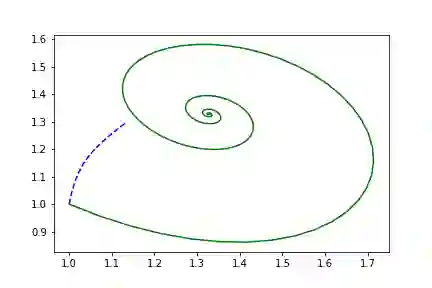
简单的螺旋形函数
在这里以及接下来所有的可视化中,虚线代表拟合模型。
true_A = torch.tensor([[-0.1, 2.0], [-2.0, -0.1]])class Lambda(nn.Module):def forward(self, t, y):return torch.mm(y, true_A)
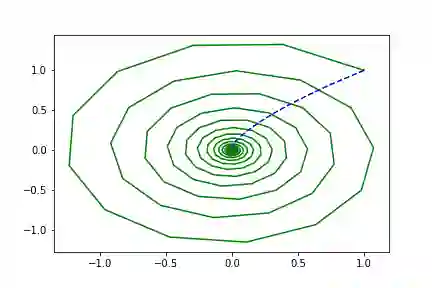
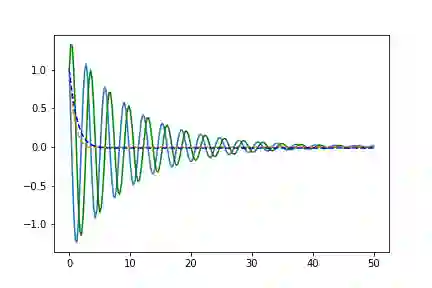
左边是相位空间,右边是时间空间。直线代表真实的轨迹,虚线代表由神经ODE系统学习的演化轨迹
随机矩阵函数
true_A = torch.randn(2, 2)/2.
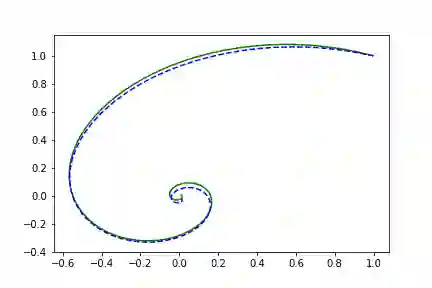
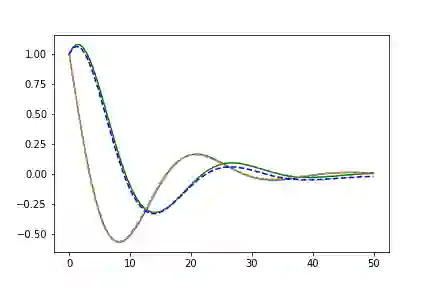
左边是相位空间,右边是时间空间。直线代表真实的轨迹,虚线代表由神经ODE系统学习的演化轨迹
Volterra-Lotka系统
a, b, c, d = 1.5, 1.0, 3.0, 1.0true_A = torch.tensor([[0., -b*c/d], [d*a/b, 0.]])
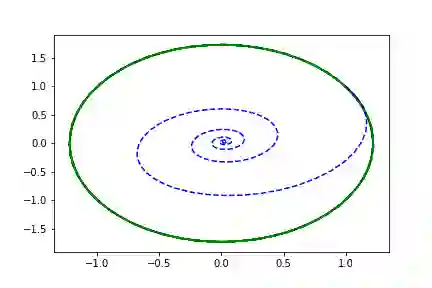
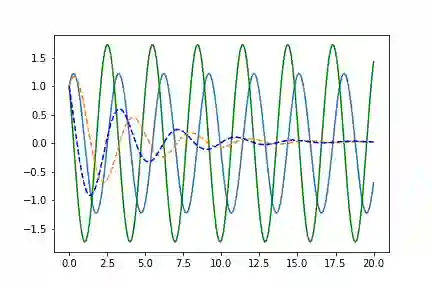
左边是相位空间,右边是时间空间。直线代表真实的轨迹,虚线代表由神经ODE系统学习的演化轨迹
非线性函数
true_A2 = torch.tensor([[-0.1, -0.5], [0.5, -0.1]])true_B2 = torch.tensor([[0.2, 1.], [-1, 0.2]])class Lambda2(nn.Module):def __init__(self, A, B):super(Lambda2, self).__init__()self.A = nn.Linear(2, 2, bias=False)self.A.weight = nn.Parameter(A)self.B = nn.Linear(2, 2, bias=False)self.B.weight = nn.Parameter(B)def forward(self, t, y):xTx0 = torch.sum(y * true_y0, dim=1)dxdt = torch.sigmoid(xTx0) * self.A(y - true_y0) +torch.sigmoid(-xTx0) * self.B(y + true_y0)return dxdt
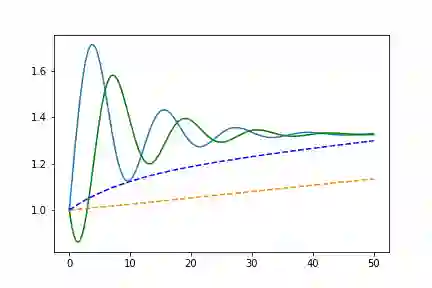
左边是相位空间,右边是时间空间。直线代表真实的轨迹,虚线代表由神经ODE系统学习的演化轨迹
正如我们所看到的,单个“残差块”不能很好地学习这个过程,所以我们会使用更加复杂的结构。
神经网络函数
让我们利用多层感知器与随机初始化的权重构建一个完全参数化的函数:
true_y0 = torch.tensor([[1., 1.]])t = torch.linspace(-15., 15., data_size)class Lambda3(nn.Module):def __init__(self):super(Lambda3, self).__init__()self.fc1 = nn.Linear(2, 25, bias = False)self.fc2 = nn.Linear(25, 50, bias = False)self.fc3 = nn.Linear(50, 10, bias = False)self.fc4 = nn.Linear(10, 2, bias = False)self.relu = nn.ELU(inplace=True)def forward(self, t, y):x = self.relu(self.fc1(y * t))x = self.relu(self.fc2(x))x = self.relu(self.fc3(x))x = self.relu(self.fc4(x))return x
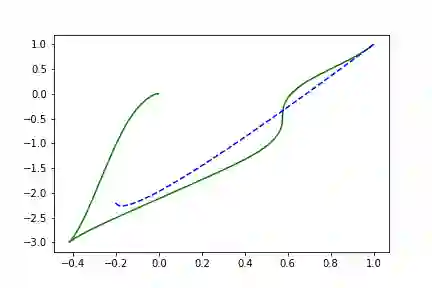
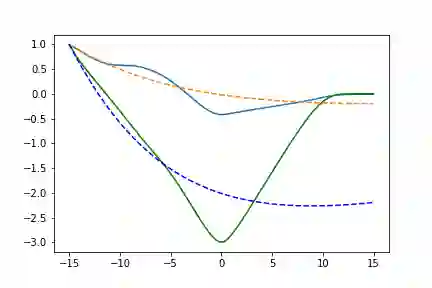
左边是相位空间,右边是时间空间。直线代表真实的轨迹,虚线代表由神经ODE系统学习的演化轨迹
这里2-50-2的网络效果十分不理想,因为它太简单了,现在我们增加网络的深度:
self.net = nn.Sequential(nn.Linear(2, 150),nn.Tanh(),nn.Linear(150, 50),nn.Tanh(),nn.Linear(50, 50),nn.Tanh(),nn.Linear(50, 2),)
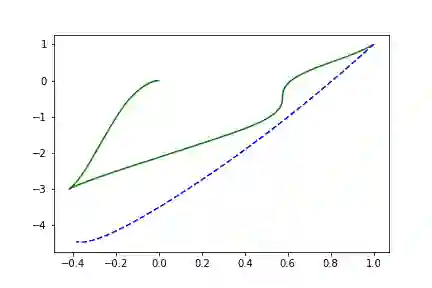
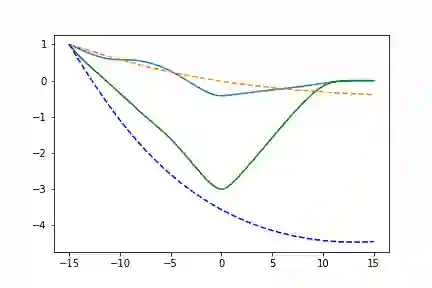
左边是相位空间,右边是时间空间。直线代表真实的轨迹,虚线代表由神经ODE系统学习的演化轨迹
现在结果或多或少像有预期的效果了,不要忘记检查代码:) (代码链接:https://github.com/Rachnog/Neural-ODE-Experiments)。
神经网络常微分方程作为生成模型
作者还声称他们可以通过变分自编码器(VAE)框架构建一个时序信号生成模型,并将神经网络ODE作为其中的一部分。那它是如何工作的呢?
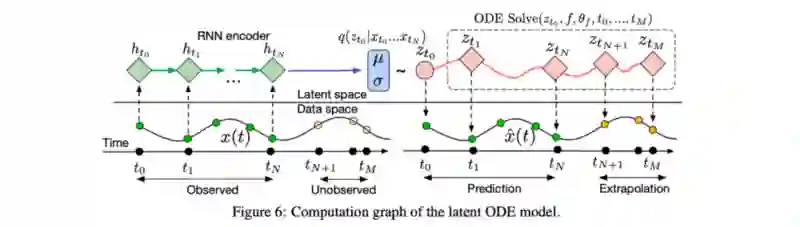
原论文插图(https://arxiv.org/pdf/1806.07366.pdf)
首先,我们用一些标准的时间序列算法对输入序列进行编码,比如RNN,以获得时序过程的初始嵌入向量。
将嵌入向量输入到神经网络常微分方程中,得到连续的嵌入向量
从连续的嵌入向量中,利用变分自编码器恢复初始序列
为了证明这个观点,我只是重新运行了这个代码库中的代码,看起来在学习螺旋轨迹方面效果比较不错:
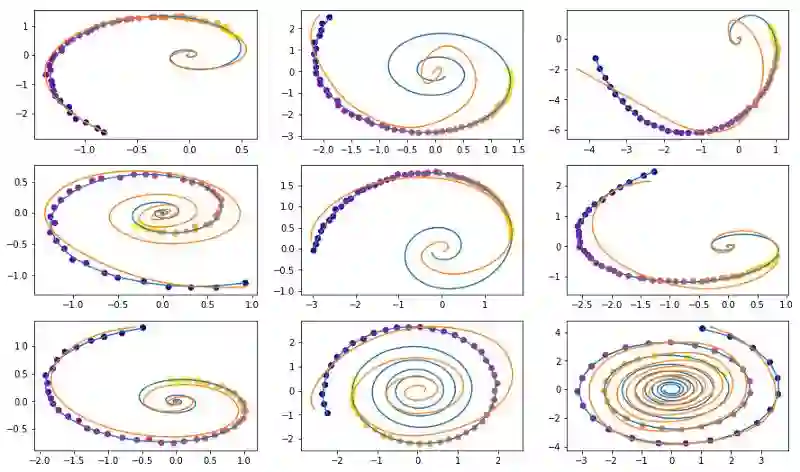
点为采样的噪声轨迹,蓝线为真实的轨迹,橙色线为恢复的和插值的轨迹
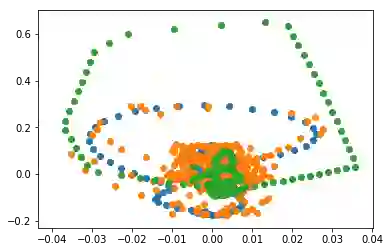

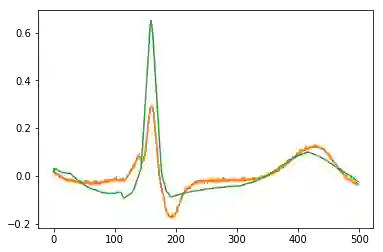
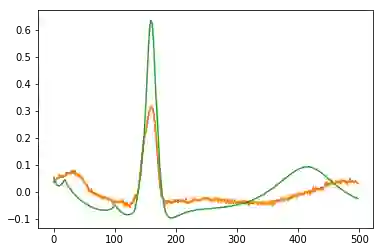
下一步干什么呢?
增强神经网络常微分方程: https://github.com/EmilienDupont/augmented-neural-odes
神经跳跃随机微分方程:https://www.groundai.com/project/neural-jump-stochastic-differential-equations/1
我们也会花些时间去探索:) 。
结 论
目前我只能看到两个实际应用:
在经典神经网络中,使用ODESolve层来平衡速度与精度
将常规常微分方程“压缩”到神经网络结构中,将它们嵌入到标准的数据科学处理过程中。
就我个人而言,我希望这个方向进一步发展(我在上面展示了一些链接),使这些神经网络(常)微分方程能表达更丰富的函数类,我将密切关注这些信息。








