【泡泡图灵智库】基于有限姿态监督的单目三维重建
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Learning Single-View 3D Reconstruction with Limited Pose Supervision
作者:Guandao Yang, Yin Cui1, Serge Belongie, Bharath Hariharan
来源:ECCV 2018
播音员:
编译:谭艾琳
审核:杨宇超
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Learning Single-View 3D Reconstruction with Limited Pose Supervision,基于有限姿态监督的单目三维重建,该文章发表于ECCV 2018。
由于训练基于单视图的三维重建模型需要为图像标记三维结构或精确的相机姿态,而完成这项标记任务又非常耗费精力;相比之下,不带标签或是仅带有类别标签的图像更易获得,但是当前很少有模型使用这种弱监督方式。因此,本文提出了一种能够将两种监督方式结合起来的统一框架,一种是将少量相机姿态标注用于加强姿态不变性和视角连续性的监督,另一种是将带有对抗损失且未被标注的图像用于加强渲染生成的模型的真实性的监督。本文使用这个统一框架测量了每一种监督方式在三种范式下的影响:半监督、多任务和迁移学习。最后将这些方法结合到一起,并且在仅使用了1%姿态标注的训练数据时,单目三维重建模型性能就提升了7个百分点(平均准确率)。
主要贡献
1、本文发现没有任何准确实例或相机姿态标注的数据集能帮助单目三维重建模型提升性能,且这类数据集极易获取。
2、本文发现基于类别的监督是不必要的,但是基于姿态的监督十分必要。研究表明,在拥有足够多的姿态注释时,没必要加入无标签图像训练;但在有限姿态监督或只有极少量的实例标注情况下,加入无标签图像训练将会使模型性能有很好的提升。
3 、经本文研究发现,在有限姿态监督情况下,通过小样本迁移学习并对模型进行微调能够使模型在极少的训练样本情况下很快地去适应一个新类别。
算法流程
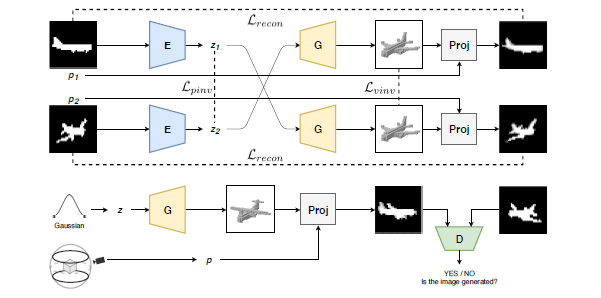
图1 本文所用模型结构概述
1、框架构成
1.1 三个主要组成部分
编码器(E):输入图像(轮廓),输出可能的形状;
解码器(G):输入可能的形状,输出体素网格;
分类器(D):区分解码器输出体素的渲染视角和真实物体的视角。
1.2 投影模块P
将体素和视点作为输入,模块P将会从输入的视点渲染体素。
2、姿态标注的图像训练
2.1 训练过程
如图1所示,每一次的图像传递过程中,编码器E都会接收到来自相同三维物体不同相机姿态p1和p2的两张图像,编码器E将每张图像凝练成可能的向量z1和z2;而解码器G则根据向量z1和z2来预测三维体素网格。
2.2 三种损失函数
重建损失:
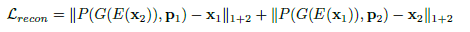
形状姿态不变性损失:
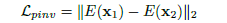
体素姿态不变性损失:
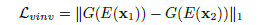
在对姿态注释的图像进行每一步训练的过程中都在尽可能地将总监督损失最小化:
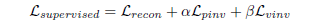
3、对无标签的图像训练
本文使用对抗损失来学习无标签图像,如图1底部所示。直观来讲就是让解码器G学习生成三维体素网格。当从一个任意视点投射时,三维体素网格应该生成一张与真实图像无二致的图像。
对抗损失的另外一个好处就是正则化。具体来说,先从正态分布采样一个向量z,从训练集中出现过的相机姿态范围均匀地采样一个视点p。然后解码器G将会用可能的向量z重建三维形状。该三维形状将会被投射成使用任意姿态p的图像。无论投射哪种相机姿态,投射出来的图像都应该和数据集中采样到的图像看起来一样。本文使用了和PrGAN相似的对抗损失更新解码器和分类器:
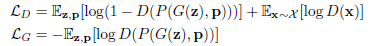
4、实现细节
模型结构中的编码器、解码器和分类器的有关细节如图2所示。投射器P(该图中未出现)中,先相对其中心旋转体素的三维模型,然后根据相机姿态用透视投影生成图像。
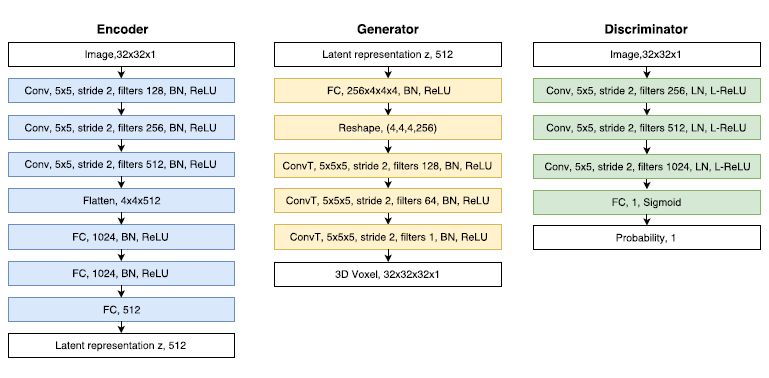
图2 编码器,解码器和分类器的模型结构
图中Conv:卷积,BN:批量标准化,LN:层标准化,L-ReLU:斜率为0.2的ReLU
,ConvT:在生成过程中常用的转置卷积。FC,k:有k个输出的全连接层。
整个模型通过对有姿态标注的图像和无标签图像的轮流迭代实现端到端的训练,对三种结构采用了Adam优化方法,当训练使用对抗损失时,用DRAGAN提出的梯度惩罚来提高训练稳定性。代码可见https://github.com/stevenygd/3d-recon.
主要结果
1、 数据集
使用了来自ShapeNetCore数据集的体素化的32x32x32三维形状。其中选取了十类物体:飞机,汽车,椅子,陈列柜,电话,扬声器,桌子,长椅,船舶和橱柜。对于每一类,都是用ShapeNet的默认分割进行训练,验证和测试。
2、评估指标
mean IoU(交并比)。去掉了极值,并计算出最大平均IoU。为了和以前的工作进行比较,列出了IoU0.4和 IoU0.5,AP(平均准确率)。
3、半监督单类训练
在该过程中,我们对每一类物体训练了一个单独的模型。我们对0到100%的姿态监督都进行了实验。我们将模型与现有的单目三维重建模型进行性能比较,结果如表1所示。
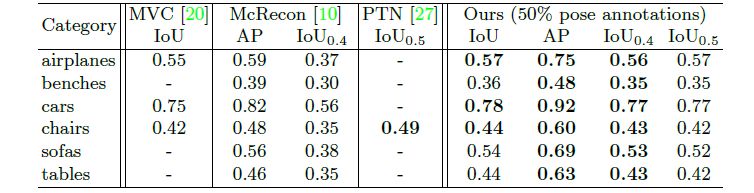
表1 本文模型与现有的单目三维重建模型比较
从表中可以看出,该模型在仅使用50%姿态监督时与现有的其他模型性能相当。
接下来为了讨论使用无标签的图像和对抗损失来提供额外的监督和正则化是否有用,本文比较了以下三种训练方法:1)用姿态注释图像和无标签图像同时训练;2)仅用姿态注释图像训练;3)仅用无标签图像训练。性能比较如图3所示。
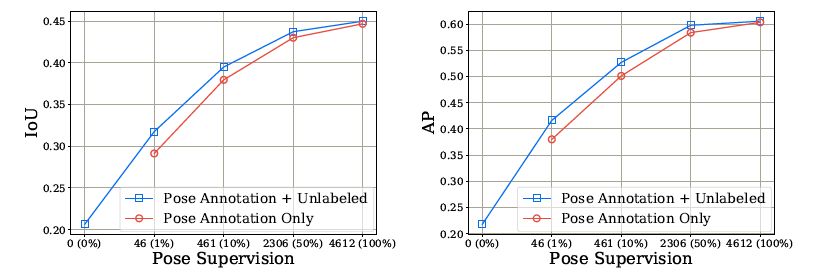
图3 三种训练模型的比较
由图3的比较可以看出:首先,姿态监督十分必要。第二,基于无标签图像的对抗损失在姿态监督和视点十分有限(≤10%)的情况下十分有效。第三,当图像有足够的姿态注释时,利用无标签图像是不必要的。
4、半监督多类训练
训练汇总时,本文用7类物体的组合训练数据的类别无关模型进行实验,该实验也是在不同的姿态注释量下进行的,结果见表2。
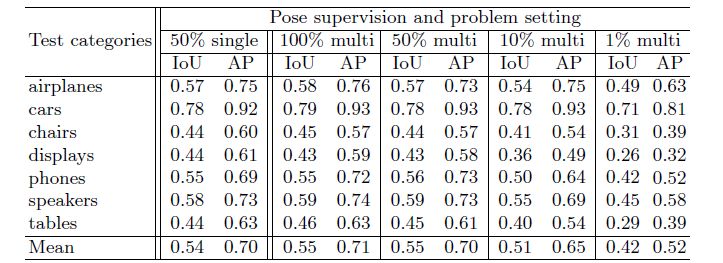
表2 不同姿态监督数量下的类别无关模型的表现
表中显示,在使用相同数量(50%)的姿态监督时,类别无关模型的表现与类别相关模型对等,从表中可以看书并不需要类别监督。
5、小样本迁移学习
通过比较三种模型,来寻找系统在面对一个全新的类别时迁移能力最好的方法。结果如图4所示。
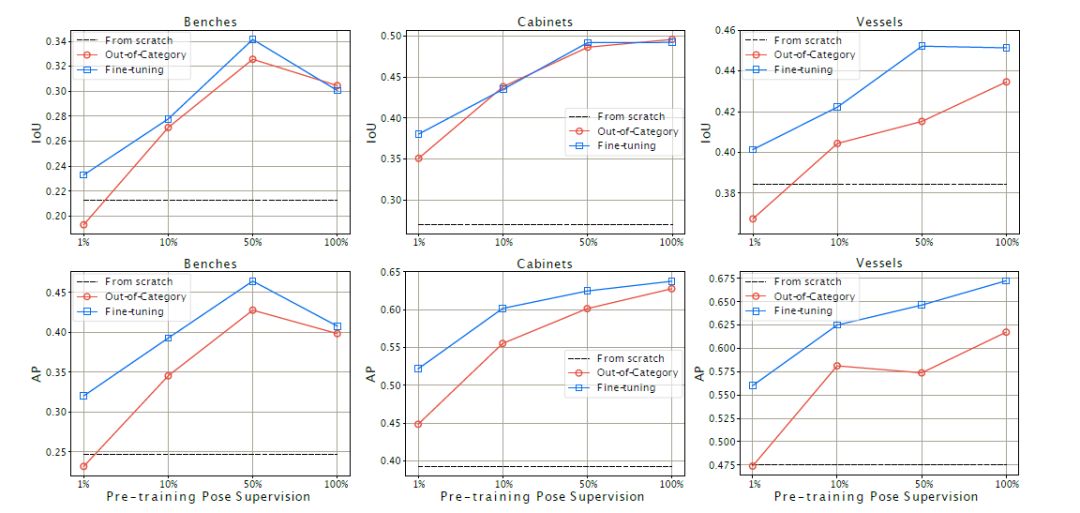
图4 对新类别的小样本迁移学习
从表中可以看出,从预训练模型上学习到的知识进行迁移对新类别的小样本学习非常重要;相比直接使用预训练模型的out-of-category基准方法,微调Fine-tuning的模型性能有很大的提升,尤其是在有限的自他监督情况下,即本文模型可以在极少的训练样本的情况下通过微调很快地适应一个新的类别。
6、定性分析结果
6.1 半监督的类别相关模型定性结果

图5 验证集上的三维形状生成
该图最上面的一行表示输入图像(32x32灰度图)。中间一行和最底部一行则分别是相应的ground truth体素和模型生成的体素。
6.2 空间插值
给出最左边形状的可能向量z1和最右边形状z2,根据
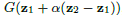
推测中间的形状。

图6 同类(上三行)和跨类(下三行)插值过程
6.3 隐空间算术

图7 隐空间运算过程
6.4 减少注释的定性影响
当监督量减少时,三维重建中出现大量噪声,但当加入无标签图像进行训练时,噪声似乎有所减少。

图8 不同数量的姿态监督训练的模型进行的形状预测
从左到右依次为:输入图像,ground truth体素和来自图3所示模型的形状。
结论
综上所述,本文提出了一个端到端的统一模型,该模型用带有相机姿态标签的图像和无标签图像作为监督来实现单目三维重建,还在有限的注释情况下评估了不同的训练方法。实验表明,通过利用无标签图像,即使只有极少的姿态注释,也可以训练单目三维重建模型。未来研究方向:在更加实际的设定上(如高分辨率的RGB图像和任意相机位置)进一步验证和扩展我们的实验结果。

Abstract
It is expensive to label images with 3D structure or precise camera pose. Yet, this is precisely the kind of annotation required to train single-view 3D reconstruction models. In contrast, unlabeled images or images with just category labels are easy to acquire, but few current models can use this weak supervision. We present a unified framework that can combine both types of supervision: a small amount of camera pose annotations are used to enforce pose-invariance and view-point consistency, and unlabeled images combined with an adversarial loss are used to enforce the realism of rendered, generated models. We use this unified framework to measure the impact of each form of supervision in three paradigms: semi-supervised, multi-task, and transfer learning.We show that with a combination of these ideas, we can train single-view reconstruction models that improve up to 7 points in performance (AP) when using only 1% pose annotated training data.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




