【泡泡图灵智库】基于点和体融合的实时三维重建(IROS)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Real-time 3D Reconstruction Using a Combination of Point-based and Volumetric Fusion
作者:Zhengyu Xia, Joohee Kim
来源:IROS(2018)
编译:万应才
审核:李雨昊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Real-time 3D Reconstruction Using a Combination of Point-based and Volumetric Fusion ,该文章发表于IROS2018。
利用Kinect或Xtion等低成本传感器进行实时三维重建已成功应用于增强现实、机器人远程操作和医疗诊断等广泛领域。由于当前的目前的三维重建技术如Kinect Fusion和Kinfu都假设三维重建为静态场景,因而用快速摄像机对真实重建或分割运动物体仍然是一个挑战。本文提出了一种加权迭代最近点(ICP)算法,该算法利用深度信息和RGB信息来提高相机跟踪的稳定性。此外,基于GPU的区域增长方法将深度、法向和强度三个层次作为相似性准则,也被应用于前景运动目标的精确分割。为了实时处理和GPU的存储效率,我们还设计了基于点和体积的表示相结合的方法来分别重建运动对象和静态场景。实验结果表明,该方法提高了运动目标的实时三维重建性能,降低了计算复杂度。
总结
改进三维重建的目的是要用低成本深度传感器完成重建,这些传感器在深度测量上具有系统误差,从而导致摄像机姿态估计不准确。为了克服系统误差的深层次问题,将系统误差模型与姿态估计过程相结合,形成各深度值的置信指标。在CI-ICP中,利用离摄像机较近的物体来估计姿态。在弹性融合中,提出了一种结合几何和光度信息的姿态估计联合优化方法,以解决深度测量中的误差,提高相机跟踪的稳定性。
为了有效地处理运动目标的分割与重构问题,基于点融合的作者设计了一种基于简单点表示的重构系统,该系统直接对深度传感器的输入进行处理。
尽管基于点的融合解决了计算复杂性和内存开销的问题,但它还有一些改进空间。具体来说,我们提出了一种联合加权的ICP算法来获得最佳的摄像机姿态,并采用基于点和体积的融合来有效地重建运动物体和静态背景。
主要贡献
为了解决上述动态场景实时三维重建中存在的问题,提出了一种提高摄像机跟踪精度、提高运动目标重建质量的系统。本文的贡献主要有:
1.为了补偿深度测量中的系统误差,我们在几何姿态估计中为每个深度值指定了一个权重指标。考虑到相机运动速度快时姿态估计误差增大,我们用L1范数距离代替L2范数距离,降低了光度优化的权重比。
2.为了解决基于点的融合问题,我们将半径图和置信度计数器扩展到三维,并将基于点的融合和体积表示相结合,以保持重建质量的水平,同时减少处理时间和内存使用。
3.为了提高区域生成方法的精度,我们还将正态图和强度图以及深度图作为相似性属性,并在GPU上实现,以保持其处理速度。然后将动态部分的点重建与静态背景的体素重建相结合。
算法流程
系统整体结构
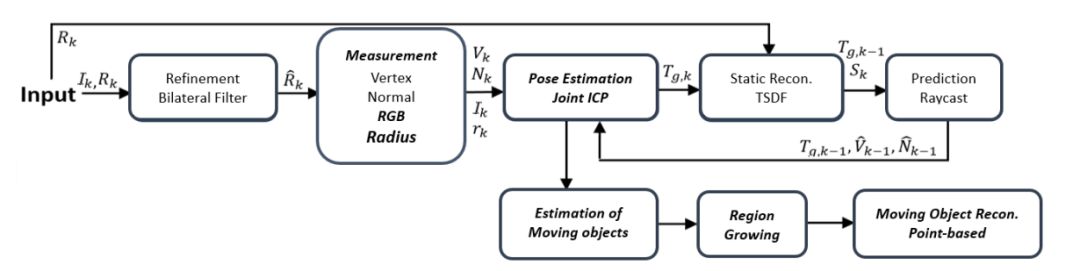
图1 重建系统框架图
为了提高动态场景实时三维重建的性能,我们提出了一种基于Kinect融合体系结构和基于点的融合方法的系统。由于低成本深度传感器在深度测量中显示出系统误差,因此基于置信指标的ICP(CI-ICP)被用于将这些误差模型纳入几何姿态估计中。考虑到摄像机快速运动时测光姿态估计误差增大,采用L1范数距离代替L2范数距离,降低了测光优化的权重比。此后,将为每个帧生成和更新一个ICP标签地图,以估计移动对象的点。根据运动点和静态点的分类结果,采用形态学方法去除杂散点和噪声。然后,我们使用基于GPU的区域增长方法来提取整个移动对象。基于GPU存储器的效率,采用简单的点融合方法对检测到的运动目标进行重构。为了获得高质量的模型和准确的预测,静态背景的三维重建仍然基于体积表示。
2.数据测量

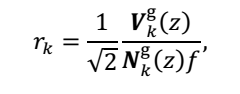

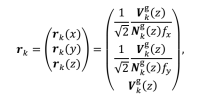
3.位姿估计
作者提出了一种加权联合ICP方法,该方法指示了光度估算的共享程度。在几何位姿估计中,我们还指定了每个深度值的置信指标,以减少深度测量中的系统误差。提出的几何位姿估计如下式所示。提出的几何位姿估计公式如下:
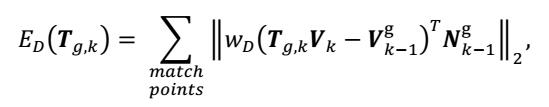
提出的联合ICP算法中降低了光度姿态估计的权重比,以减少光度估计中的误差,公式如下:
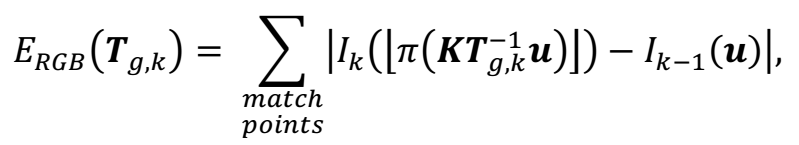
联合代价函数如下所示:
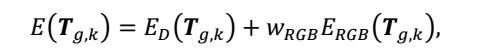
4.运动物体的估计
本文创建了一个灰度ICP标记图,在数据关联和姿态估计步骤中存储每个深度样本的信息。ICP标签图为每个点存储以下值之一:a)无效(黑色):未找到对应点,附近无稳定模型点。b)动态(灰色):找不到对应点,但附近模型点稳定。c)静态(白色):输入深度样本的稳定模型对应关系。

图2 本文方法的完整流程图
5.使用组合表示法进行三维重建
为了实现快速运行的高质量三维重建,我们对静态背景采用了体积表示,对前景运动对象采用了基于点的融合。原因是:1.体积表示可以实现高质量的三维重建。2.体积表示与光线投射一起应用TSDF。与基于点的融合相比,该算法能更准确地估计全局顶点和法线,准确的数据预测提高了相机对未来帧的跟踪能力。它也有助于更精确地检测运动物体的候选对象,因为它在ICP上具有更好的性能。基于点的融合可以在牺牲重建质量的前提下,使用更少的GPU内存实现更快的处理速度。
主要结果
本文使用了Munchen Technology University (TMU)的RGBD-SLAM数据集,它是一个公共数据集,具有用于评估视觉里程计和视觉SLAM系统的Ground-truth。由于Kinfu和 lasticFusion不能处理运动物体的场景,因此在静态三维重建环境下进行了相机跟踪能力的实验。
1.跟踪能力
如表一所示,在ATE指标方面,其表现比基线Kinfu差4.77%。我们提出的点平均法的解决方案使用校准焦距,并将半径图扩展到三维。结果表明,改进的点平均法处理管道的性能优于基线Kinfu,分别为2.16%和9.42%。
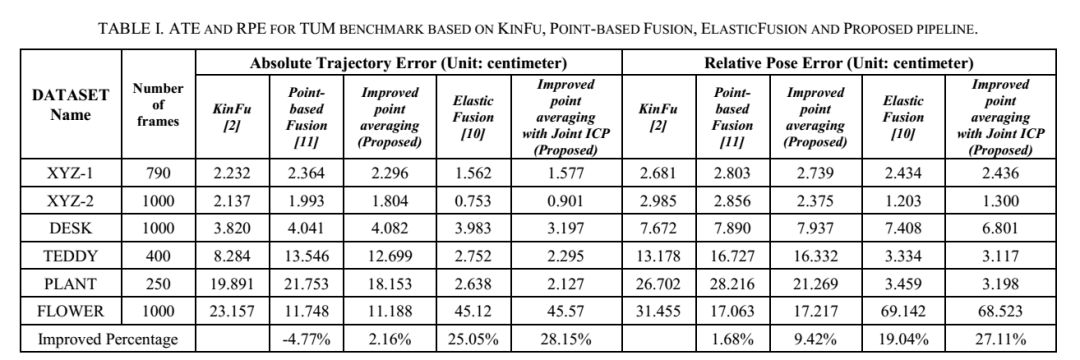
表1 基于Kinfu,点基融合,弹性融合和本文提出框架的TUM基准测试的ATE和RPE
如图4(a)Kinfu和图4(b)ElasticFusion所示,多次错误地重建了植物和植物下方的基础。另外,由于速度太快,工厂前面的桌子在两种方法中都会变形。相机运动。我们提出的方法克服了这一缺点,产生了如图4(c)所示的最佳重建质量。

图4使用(a)Kinfu、(b)ElasticFusion和(c)提出的方法对“工厂”数据集的三维重建结果进行比较。
2. 重建运动目标
图5(d)显示了我们提出的方法的结果,该方法将静态背景的体积重建与移动对象的基于点的重建结合起来。如图5(c)所示,原Kinfu无法跟踪和重建图 5(a)所示的移动组织盒,其相应区域因运动而被错误地重建。

图5比较原始Kinfu和提议的“移动盒子”数据集方法(a)RGB图像,(b)深度图,(c)使用Kinfu的三维重建,(d)使用所述方法的三维重建
在图6(a)中,区域图由静态背景获取的一部分组成。与运动对象合并,并在运动对象的三维重建中得到重建。这是因为只有深度信息被用作分割的相似性度量。为了解决这一缺点,我们引入了正态图和强度图以及深度值作为相似性度量,以避免增长到不属于运动对象的区域。图6(b)显示了第II.d节中提到的使用组合相似性标准的拟议区域生长方法的结果。

图6 区域生成结果通过(a)仅使用深度相似性和(b)同时使用深度、方向和强度相似性获得。
3.用组合表示法进行三维重建
表二给出了使用数据集“货架”的结果,其中移动对象是人。该方法的计算精度达到80.76%,比单点融合方法的计算精度高6.37%。根据我们的观察,三维分割的性能直接受输入深度的影响。
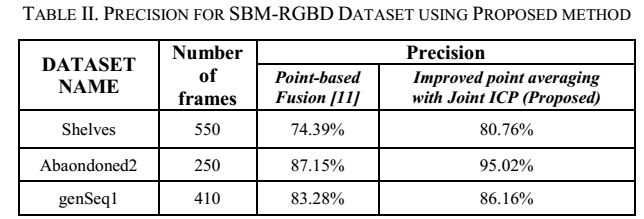
表2使用所提出的方法计算SBM-RGBD数据集的精度
在图7(a)中,头部的深度信息丢失,因为颜色接近黑色,导致传感器发出的红外线几乎被吸收。表II还表示使用SBM-RGBD数据集的其他实验的结果。

图7 一个由于深度图噪声而导致的不完全三维重建的例子:(a)深度图,(b)RGB图像,(c)地面真值,(d)前景移动物体的三维重建。

Abstract
Real-time 3D reconstruction using low-cost commodity sensors like Kinect or Xtion has been successfully applied in a wide range of fields like augmented reality, robotic teleoperation, and medical diagnosis. Due to the assumption of static scene, popular 3D reconstruction technologies such as KinectFusion and KinFu, find truthful reconstruction with fast motion camera or segmenting a moving object to be a challenge.In this paper, we propose a weighted iterative closest point (ICP) algorithm that uses both depth and RGB information to enhance the stability of camera tracking. Additionally, a GPU-based region growing method that combines depth, normal and intensity level as similarity criteria, is also applied to segment foreground moving objects accurately. For real-time processing and GPU memory efficiency, we also design a combination of point-based and volumetric representation to reconstruct moving objects and static scene, respectively. Both qualitative and quantitative results show that our proposed method improves real-time 3D reconstruction on the performance of camera tracking and segmentation of moving objects with reduced computational complexity.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




