Facebook 爆锤深度度量学习:该领域13年来并无进展!网友:沧海横流,方显英雄本色



论文下载地址:https://arxiv.org/pdf/2003.08505.pdf
度量学习试图将数据映射到一个嵌入空间,在这个空间中,相似的数据靠得很近,类型不同的数据离的很远。而映射的方式可以通过嵌入损失和分类损失实现,这两种方式各有特点,嵌入损失是根据一批样本之间的关系来操作,而分类损失包括一个权重矩阵,将嵌入空间转化为类logits向量。
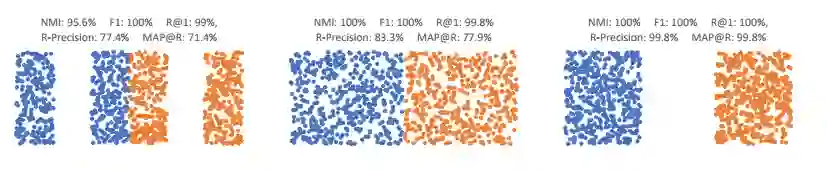
三个 toy示例:不同的精确指标如何评分。

该领域确实水文比例挺大的,有些文章为了中,确实会用特别低的baseline, 用resnet甚至densenet和别人googlenet的结果去比,或者用2048维特征去比过去方法的128维的结果。
一位网友提到,度量学习在数学上优雅,在可视化上炫酷,在论文结果上漂亮,但在实际应用中却毫无效果。
Metric learning在数学上推得很优雅,在可视化上很酷炫,在论文结果上表现得很漂亮,但实际应用上却毫无效果。asoftmax am amm等在某些数据集上确实拟合很好,适合刷指标,但实际在跨数据开集上,还是最简单的softmax更香。
公式超级多,论文看起来就专业 可视化好看,类间离散图很优雅
基本认同。唯一的进展是李飞飞的超大规模数据集,告诉大家堆数据带来的提升效果比算法创新还要大。然而这基本只算一个工程经验,根本也谈不上一个'进展'。
那么metirc learning有没有发展呢,我认为最主要的发展还是近几年的normalization,这个东西明确了几何空间的定义,使得研究人员能够更好的在几何层面设计metric,最后无论是训练的收敛速度还是最后的准确率都有了极大的提升。
最后,我们引用一下知名博主「王晋东不在家」的话(编者注:有删减)——
其实大可不必心潮澎湃、攻击别人、对该领域前途失望。每当一个研究领域出现一些retlinking、revisiting、comprehensive analysis等类型的文章时,往往都说明了几个现象:
1、这个领域发展的还可以,出现了很多相关的工作可以参考;
2、这个领域的文章同质化太严重,到了传说中的“瓶颈期”;
3、研究人员思考为什么已经有这么多好工作,却好像觉得还差点意思,还“不够用”、“不好用”、“没法用”。
其实这对于研究而言是个好事。我们在一条路上走了太久,却常常忘记了为什么出发。此时需要有些人敢于“冒天下之大不睫”,出来给大家头上浇盆冷水,重新思考一下这个领域出现了什么问题。哲学上也有“否定之否定”规律。
回到metric learning的问题上来。其实想想看,机器学习的核心问题之一便是距离。Metric learning这种可以自适应地学习度量的思想,真的是没用吗?还是说它只是被目前的方法、实验手段、评测数据集等等束缚了手脚,阴差阳错地导致了不好的结果这也是这个问题的提出者原文作者质疑的问题。
不能经受得住质疑和时间的洗礼的工作,不是好工作。事实上此类事情并不是第一次发生。
不信你看,作为当下ICML、ICLR、NIPS等顶会的“宠儿”,meta-learning可谓风头一时无两。然而,大家都清楚,meta-learning的一大部分工作都是在few-shot的任务上进行算法开发和评测的。从18年开始到今年的ICLR,就已经不断地有人“质疑”其有效性了。“质疑”的核心问题之一是:用简单的pretrain network去学习feature embedding,然后再加上简单的分类器就可以在few-shot那几个通用任务上,打败很多“著名”的meta-learning方法。所以到底是meta-learning的这种“学会学习”的思想没用,还是它只是被不恰当地使用了?或者说,meta-learning的正确用法是什么?我认为这也是要思考的。我个人是非常喜欢meta的思想的。
其实在transfer learning领域。我之前也有一篇看似“打脸”的paper:Easy Transfer Learning by Exploiting Intra-domain Structures。我们的实验同样证明了仅需简单pretrain过的ResNet50提取源域和目标域的feature embedding,然后加上简单的线性规划分类器,甚至是nearest centroid,就能取得当时(2018年底)几乎最好的分类结果。但是你能说transfer learning没用吗?显然这并不能掩盖transfer learning方法的光芒。所以我一直都在质疑自己:肯定是这些数据集不完善、精度不能作为唯一指标、其他方法需要再调参数,等等。
我觉得这可能是个实验科学的误区:我们实验设定本来就需要完善,并不能因此否定一类方法的有效性。深度学习大部分都是建立在实验科学的基础上,因此实验很关键。
有了广泛的质疑,才会有更广泛的讨论,于是会有更广泛的反质疑、新范式、新思想。从整个领域的发展来看,这无疑是好事。
所以这应该是“沧海横流,方显英雄本色”的时候了。加油吧!




