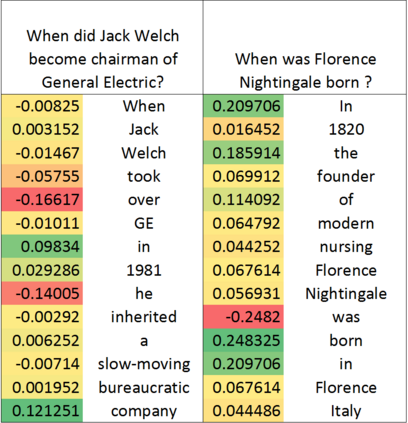
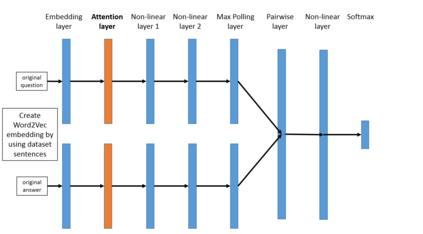
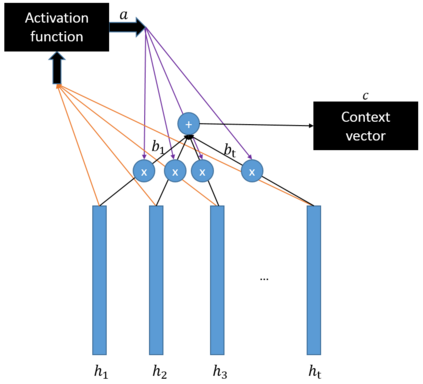
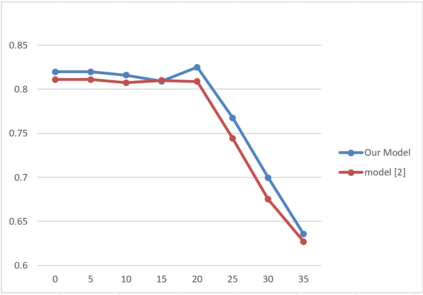
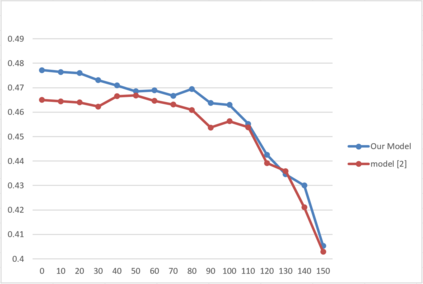
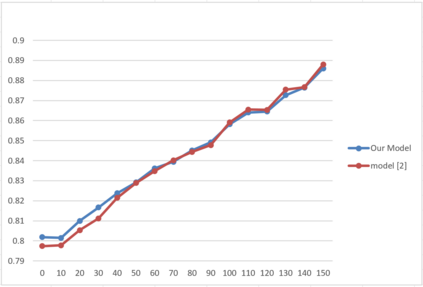
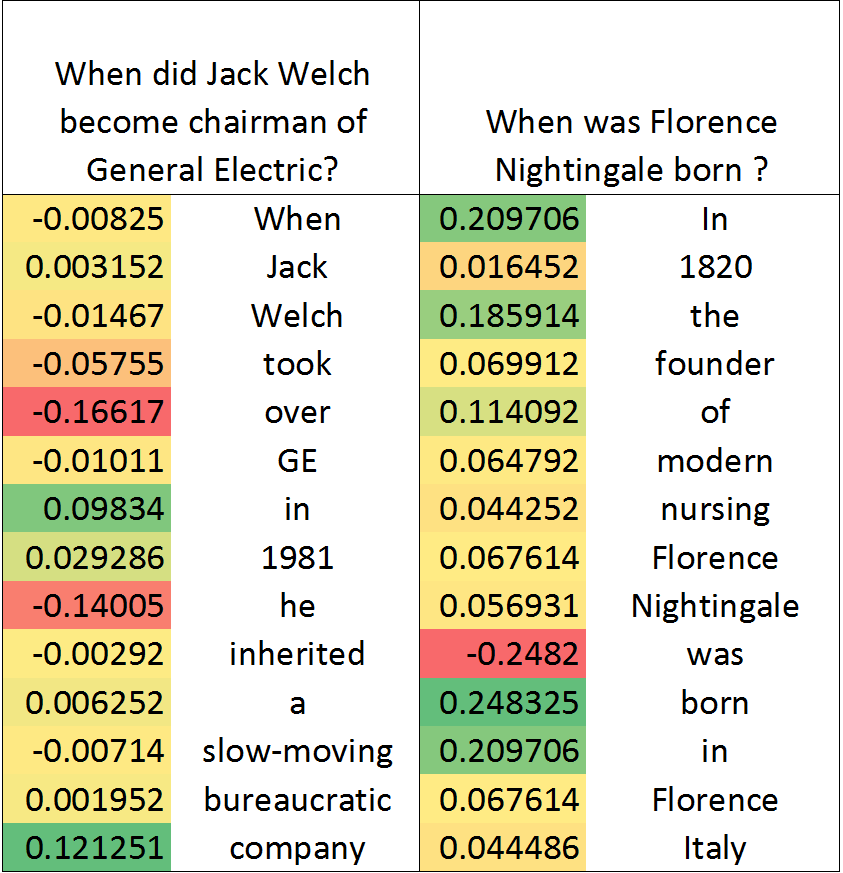
One of the main challenges in ranking is embedding the query and document pairs into a joint feature space, which can then be fed to a learning-to-rank algorithm. To achieve this representation, the conventional state of the art approaches perform extensive feature engineering that encode the similarity of the query-answer pair. Recently, deep-learning solutions have shown that it is possible to achieve comparable performance, in some settings, by learning the similarity representation directly from data. Unfortunately, previous models perform poorly on longer texts, or on texts with significant portion of irrelevant information, or which are grammatically incorrect. To overcome these limitations, we propose a novel ranking algorithm for question answering, QARAT, which uses an attention mechanism to learn on which words and phrases to focus when building the mutual representation. We demonstrate superior ranking performance on several real-world question-answer ranking datasets, and provide visualization of the attention mechanism to otter more insights into how our models of attention could benefit ranking for difficult question answering challenges.
翻译:排名方面的主要挑战之一是将查询和文档配对嵌入一个共同的功能空间,然后可以将其输入到一个学习到排序的算法中。为了实现这一表达方式,传统状态的艺术方法具有广泛的特征工程学,可以将查询和答对的相似性编码。最近,深层学习的解决方案表明,在某些环境里,可以通过直接从数据中了解相似性来取得可比较的性能。不幸的是,以前的模型在较长的文本或大量不相干的信息的文本上表现不佳,或者在语法上不正确。为了克服这些限制,我们建议了一种用于回答问题的新型排序算法,即QARAT,它利用一种关注机制来学习在建立相互代表时要关注的词和词组。我们在几个现实世界的问答排名数据集上表现出优异的排名表现,并提供关注机制的直观化,以便更深入了解我们的关注模式如何有利于对困难的回答挑战进行排名。