博客 | 度量学习总结(三) | Deep Metric Learning for Sequential Data


本文原载于微信公众号:磐创AI(ID:xunixs),欢迎关注磐创AI微信公众号及AI研习社博客专栏。
作者 | Walker
编辑 | 安可
出品 | 磐创AI技术团队
【磐创AI导读】本文是度量学习系列文章的第三篇,上两篇我们总结了一些常用于文本分类以及适用于高维数据的度量学习方法,本文的主题是度量学习方法对时序数据的处理。
本文提出了一种基于循环神经网络(RNN)的三元组序列数据度量学习方法。我们认为,利用JACCard距离作为代理距离度量,该模型可以有效地训练类标。我们通过实验证明了该方法在三种不同的计算机日志行数据集上的性能和效率。
我们通过使用代理距离度量(jaccard距离)提高了建议的标签方法的效率,该度量允许我们学习带有少量注释的高质量距离度量。实验结果表明,具有代理距离的三元组度量学习方法在相同标签数量的效果明显优于RNN模型。
我们的目标是学习一个嵌入函数,它将符号标记序列从特征空间映射到度量空间,从而使语义相似的序列彼此映射得更近,而非相似的序列则相距更远。这背后的一般思想被称为度量学习。近年来,人们提出了基于三元体神经网络的深度学习方法来学习这种嵌入函数。三元体神经网络通过优化输入三元体网络上的排名问题来学习度量标准。三元体网络由锚点序列、正序列和负示例组成。这三个例子通过相似度关系相互关联,也就是说,正面的例子应该比反面的例子更类似于锚点的例子。三重网络训练学习一个函数,该函数将实例嵌入度量空间,其中正序列比负序列更接近锚点实例。
目前为止,三重网络只接受过使用标签信息的训练。也就是说,如果锚点示例具有相同的标签,则示例对锚定示例为正,否则为负。我们将代理距离度量与几个带标号的例子结合起来,确定三个例子之间的相似关系。这个代理距离度量给出了一些关于排名的指示,但在其他方面并不十分精确。如果需要,可以通过添加一些带标签的示例来改进所学的度量空间。因此,换句话说,我们采用弱监督学习的形式来使用三重网络学习距离度量。
与在成对训练示例中简单地使用距离度量相比,此方法有两个优点。首先,它根据训练示例的数量进行缩放,其次,它允许学习更高质量、特定于领域的度量标准。它还提供了一种通用的方法,将输入数据的现有度量与标记的示例结合起来。

我们都知道,深度学习算法由以下四个部分组成:模型、目标函数、优化过程和数据。在这里,我们描述了我们用来学习序列距离度量的模型,我们的模型结构基于三重网络。该模型由一个用于嵌入的深度神经网络组成,然后是一个L 2归一化层。三联体的每一个输入都是用同一个网络嵌入的,归一化的输出用于计算三联体的损失函数。我们使用lstm来嵌入序列,而非卷积神经网络。LSTM非常适合于序列建模,并已应用于许多顺序学习问题。
我们将包含规范化层的嵌入网络称为f,x是序列,z是嵌入序列z=f(x)。图示意性地描述了我们的三重网络体系结构。我们使用一个三重LSTM和一个L2规范化层来学习序列的度量嵌入空间。
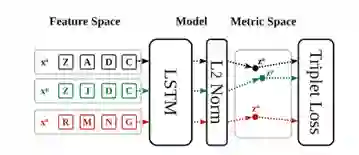
在这里,我们描述了学习序列距离度量的目标。当嵌入锚与嵌入正例之间的距离大于嵌入锚与嵌入负例之间的距离时,此目标将惩罚三重连接。
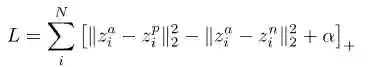
假设一个嵌入锚示例zia的三重集合,一个嵌入正示例zip和一个嵌入负示例zin,这个目标最小化锚与正锚与锚与负锚之间的距离差以及给定的裕度α。α是一个超参数。如果正例与锚之间的距离较小,而负例与锚之间的距离较大,则三重损失L较小。参数α确保允许同一类的示例之间存在空白。
我们使用Jaccard距离作为代理度量来确定相似性两个输入序列之间的关系。Jaccard距离 JD是距离在两组 x 1和x 2之间测量。Jaccard距离告诉我们多样性两个序列,但它忽略序列的信息属性,如令牌的顺序。我们假设使用Jaccard距离提供有足够的信息根据三元组的不相似性对三元组进行排名。
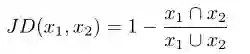
为了用三联体网络学习距离度量,我们需要定义输入三联体例子的关系。也就是说,对于锚示例,我们需要知道一个示例是正的,即属于同一类,还是负的,即属于不同的类。
输入示例之间的关系在锚示例x a和另一个示例x j之间定义。我们使用两个步骤来定义这种关系。这两步过程如图所示。

这里我们展示了序列xj与锚定序列xa之间的关系定义过程。我们的主要思想是通过使用代理距离度量和一些带标签的示例定义输入数据的相似关系,以弱监督的方式学习距离度量。与三重网络相结合,这些相似关系允许我们学习输入序列的特定域度量。
如果我们没有可用的标签信息,我们使用jaccard距离jd作为代理距离度量来确定x a和x j之间的关系。如果JACCard距离低于阈值t pos,则关系为正;如果高于另一阈值t neg,则关系为负。如果JacCard距离高于正阈值t-pos,但低于负阈值t-neg,我们将关系定义为未知。
形式上,我们定义锚定序列xa和另一序列xj之间的相似关系,如下所示。让xa,xj是两个令牌序列,la,lj是它们各自的标签,jd(x a,x j)两个序列之间的jacard距离,tpos,tneg作为正或负示例对的阈值。如果序列没有标记,则其标签为∅。
然后我们将两个序列之间的相似关系r定义为:
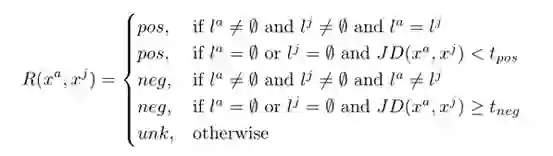
【总结】:本文介绍了深度度量学习如何处理时序数据的问题。欢迎大家持续关注我们的公众号,学习更多机器学习知识。
欢迎扫码关注磐创AI微信公众号


点击 阅读原文,查看更多内容



