近期声学领域前沿论文(No. 4)
1. 基于神经网络的语音质量评估
参考文献:
non-intrusive speech quality assessment using neural networks
链接:
https://arxiv.org/abs/1903.06908
单位:
蒙特利尔大学,微软
尝试解决的问题:
如何代替人去评估一个音频的好坏
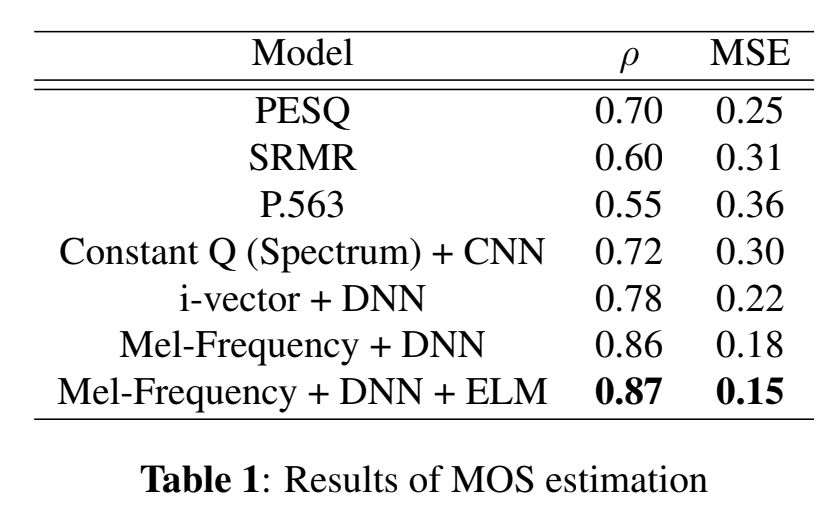
对于生成型模型而言,如何评估生成样本的好坏一直没有完全标准的做法,例如在语音合成中,检测语音合成的效果都是靠人去听然后进行主观评分。而本文作者使用一个完全前馈型神经网络构建的语音评估模型,其通过将梅尔频谱作为输入特征,得到了与MOS相关系数为0.85并且最低均方差为0.15的好结果。
本文中作者一共提出了三个神经网络模型,它们分别是常数Q变换、将i-vector作为神经网络的输入、将梅尔频谱作为神经网络的输入,并且将它们的结果与PESQ、P.563和SRMR这三个客观的乐器指标进行比较,最终可以用来评估MOS值。实验结果表明,将梅尔频谱作为输入的全连接神经网络表现最佳。从文中截取的下表为不同模型对比的实验结果:
2. MIDI文件的智能版
参考文献:
Smart Edition of MIDI Files
链接:
https://arxiv.org/abs/1903.08459
单位:
Spotify
尝试解决的问题:
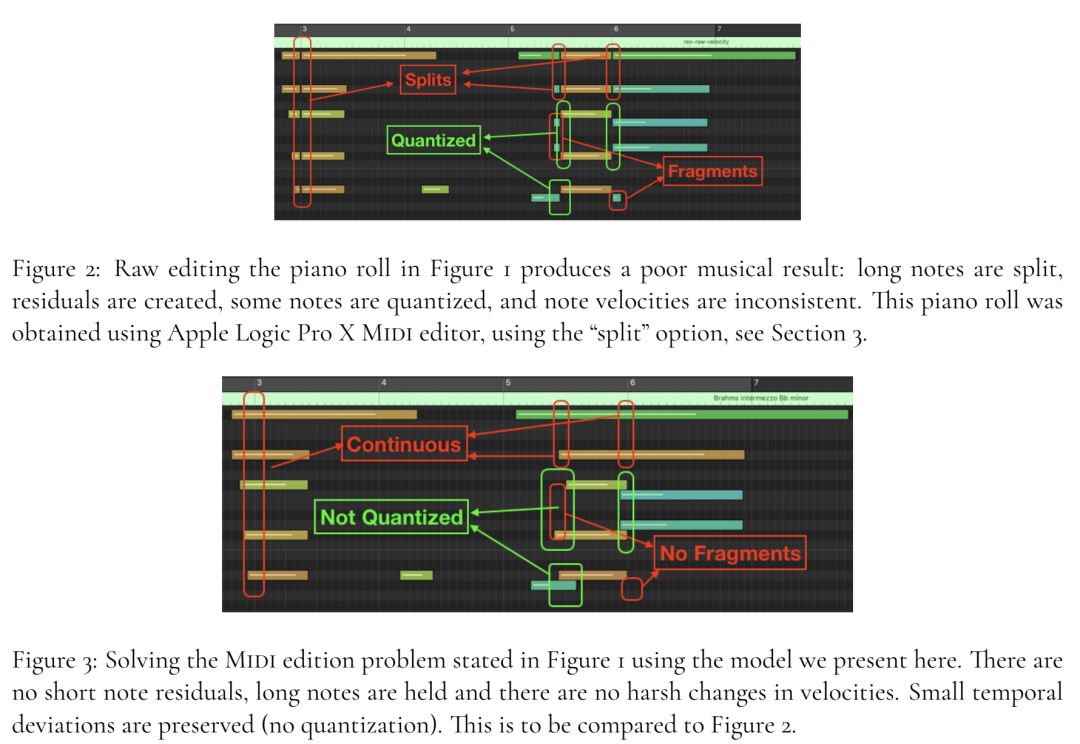
在编辑MIDI音频时候如何保证音频之间的连续性、没有突然变化的尖峰
从文中截取的下图可以清晰地概括本文所做的工作:
3. 通过对抗生成网络(GAN)在原始音频上实现超分辨增强
参考文献:
bandwidth extension on raw audio via generative adversarial networks
链接:
https://arxiv.org/abs/1903.09027
单位:
University of Michigan,University of Washington
尝试解决的问题:
基于GAN的音频超分辨算法一般会使得音频频谱出现不光滑的现象,为了解决这个问题,通常的做法是增加一个感知特征损失函数(perceptual loss),但是这种loss通常需要一个强大的预训练好的分类网络,同时也需要大量的特征标记,作者为了解决这个不现实的问题基于U-net提出了一种无监督的特征loss,并结合GAN进行一起训练而得到了最好的效果。
从文中截取的下图表明了原始的高分辨音频、原始的低分辨音频与通常的超分辨音频(通过对抗损失函数和L2损失函数学习得到)的频谱对比图:
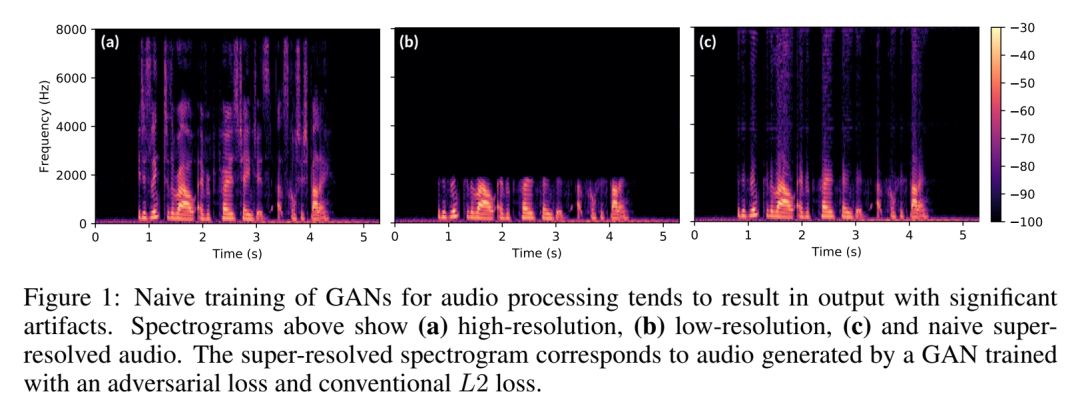
音频超分辨是指将一个下采样过的音频或低分辨率的音频转化为一个高分辨率的音频的过程,即提高了采样率,或者说重构了一部分消失的频谱。为了解决超分辨音频生成带来的频谱不光滑的问题以及减少大量的预训练成本和特征标记成本,作者在本文中提出了一个基于卷积神经网络的对抗生成模型,并提出了一个全新的无监督的通用特征loss,该模型可以被稳定地训练并且通过主观和客观的评估方法,发现该模型在人声音频、音乐音频的超分辨增强上取得了业界最好的表现。
通常的GAN中,生成器是基于噪音来生成新的分布,而判别器则用来判断该分布是否与真实分布接近。在音频超分辨任务中,生成器则是基于低分辨率的音频来生成高分辨率的音频,判别器用来判断生成的高分辨率音频是否和低分辨率音频一样。这个就是GAN框架在音频超分辨任务中的应用原理。
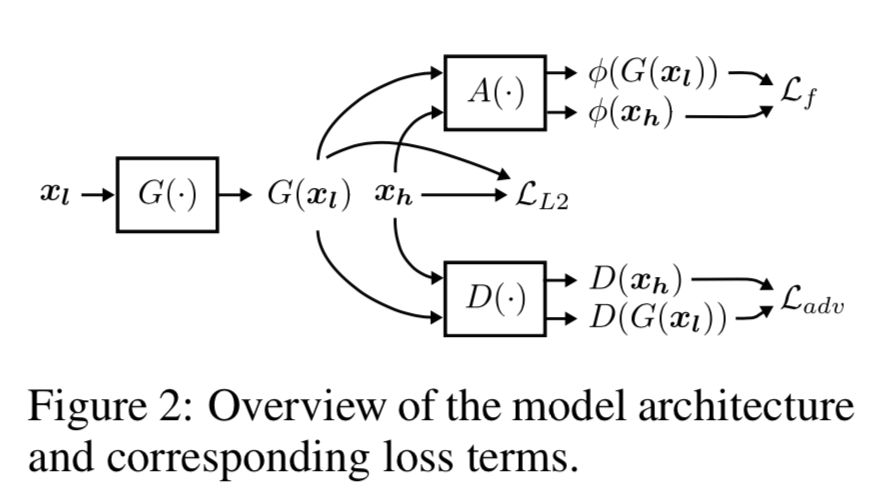
在本⽂中,作者提出了一个包含多级别卷积特征的U-net-GAN框架(如上图所示),它包含了三个组成部分:生成器、判别器和基于卷积网络的自动编码器。生成器的任务是建⽴低分辨率⾳频x_l 和⾼分辨率⾳频x_h 之间的 映射,判别器的任务是判断生成的数据分布是真的还是假的。除了生成器器和判别器以外,本模型中的⾃动编码器可以提取⽣成的⾳频和目标的⾼分辨音频的感知特征,整个框架如上图所示,图中有三个损
失函数,分别是L_f 、L_L2 和L_adv ,其中L_f 表示由⾃动编码器器提取出来的感知特征的损失函数,具体是二者之间的均⽅差;L_L2 则是生成器⽣生成的音频与目标⾼分辨⾳频之间的均⽅差; L_adv 则是判别器的损失函数,即负对数似然。最终的损失函数则是:
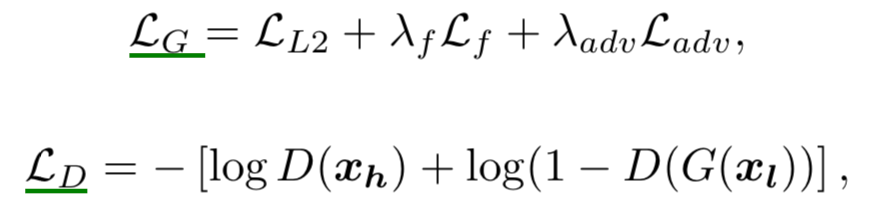
接下来我分别介绍判别器、生成器和自动编码器。
首先,模型的生成器和判别器如下图所示,其中生成器是一个类似U-net的结构,U-net被广泛运用于图像分割领域,U-net包含上采样、下采样两个模块,它们里面都用到了多级别的卷积神经网络,即4中不同卷积核的卷积层(3×1,9×1,27×1,81×1),可以用来捕捉不同层次的特征信息,同时,二者中分别用到了SuperPixel Layer和SubPixel Layer,其中SubPixel Layer通过将空间信息转化为通道信息,再将各个通道的信息按照固定的顺序插入到超分辨对象中,这个就是这里的上采样过程;基于这个已有的工作,并且传统的通过strided convolution和pooling的下采样操作容易导致不平滑的问题,作者进而提出将SubPixel Layer的逆操作作为下采样,称之为SuperPixel Layer,该逆操作的做法是首先对时间维度的采样点转化为通道维度,再通过一个固定的缩放因子来对通道维度进行降维即可。判别器中也采用了多级别的卷积神经网络,并通过SuperPixel Layer来实现降维。
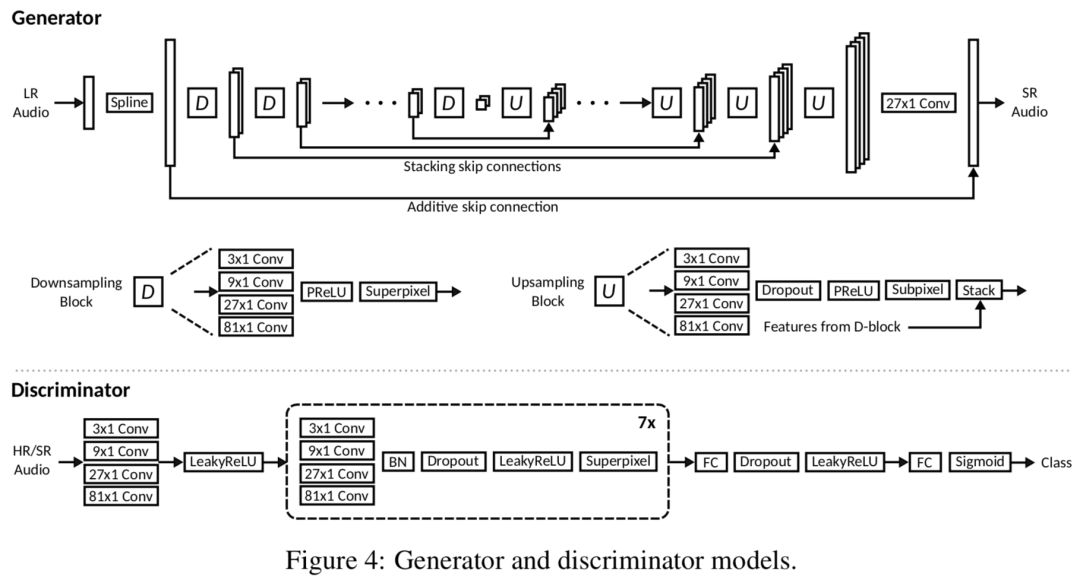
自动编码器部分跟生成器的结构基本一样,只是剔除了所有的残差连接操作。总而言之,作者在模型上的的创新点有:
设计了一个无需对音频预处理、可以自动提取感知特征的自动编码器结构,并将其loss作为其中一个训练目标;
仿照SubPixel Layer的设计理念,将其逆操作作为下采样来替代传统的strided convolution操作;
在评估阶段,作者采取了生成音频与目标音频之间的信噪比(Signal-to-noise,SNR)、对数频谱距离(log-spectral distance,LSD)、平均主观意见分(mean opinion score)来分别对说话人音频、钢琴曲两个任务进行评估,最终实验结果表明与业界最新成果相比,该模型取得了最好的效果。
题图:深圳梧桐山
深度学习每日摘要|坚持技术追求原创



