从 6 篇顶会论文看「知识图谱」领域最新研究进展 | 解读 & 代码

本期内容选编自微信公众号「开放知识图谱」。
ISWC 2018

■ 链接 | http://www.paperweekly.site/papers/1912
■ 源码 | https://github.com/quyingqi/kbqa-ar-smcnn
■ 解读 | 吴桐桐,东南大学博士生,研究方向为自然语言问答
概述
随着近年来知识库的快速发展,基于知识库的问答系统(KBQA )吸引了业界的广泛关注。该类问答系统秉承先编码再比较的设计思路,即先将问题和知识库中的三元组联合编码至统一的向量空间,然后在该向量空间内做问题和候选答案间的相似度计算。该类方法简单有效,可操作性比较强,然而忽视了很多自然语言词面的原始信息。
因此,本文提出了一种 Attentive RNN with Similarity Matrix based CNN(AR-SMCNN)模型,利用 RNN 和 CNN 自身的结构特点分层提取有用信息。
文中使用 RNN 的序列建模本质来捕获语义级关联,并使用注意机制同时跟踪实体和关系。同时,文中使用基于 CNN 的相似矩阵和双向池化操作建模数据间空间相关性的强度来计算词语字面的匹配程度。
此外,文中设计了一种新的实体检测启发式扩展方法,大大降低了噪声的影响。文中的方法在准确性和效率上都超越了 SimpleQuestion 基准测试的当前最好水平。
模型
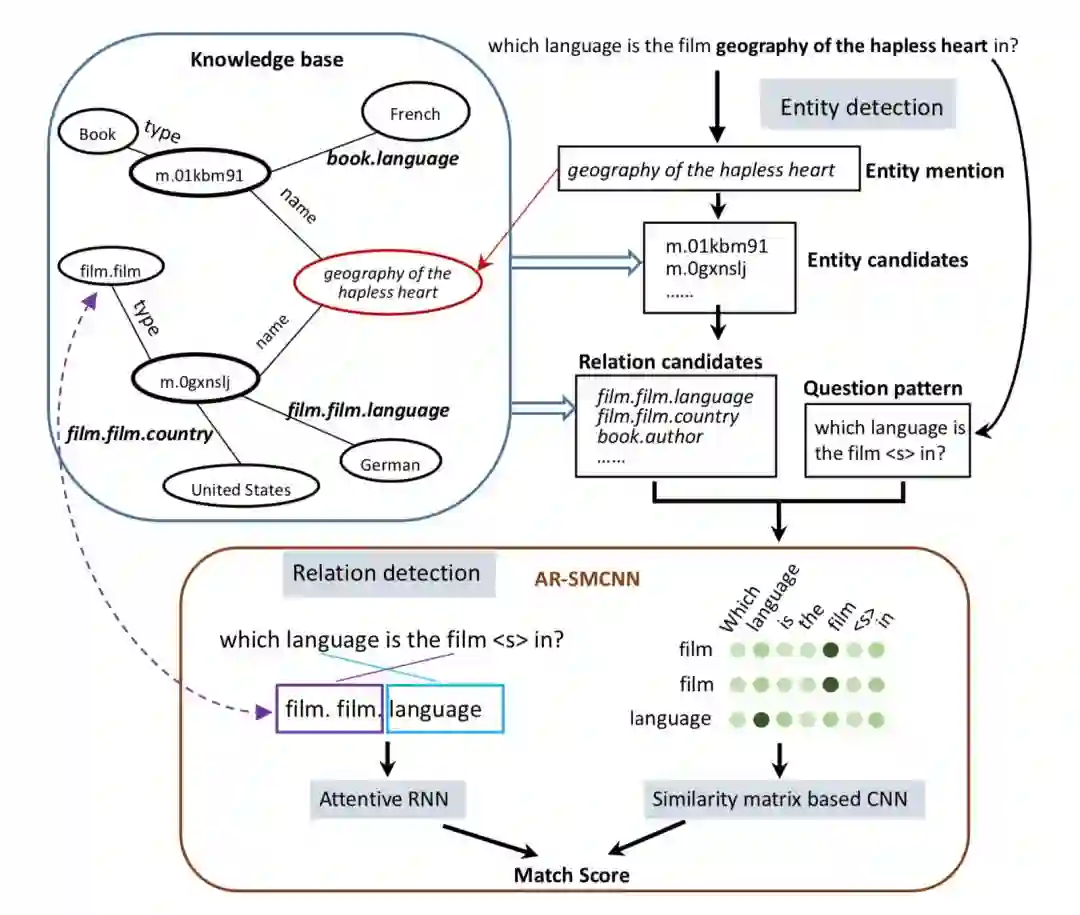
模型如上图所示,假设单关系问题可以通过用单一主题和关系论证来查询知识库来回答。因此,只需要元组(s,r)来匹配问题。只要s和r的预测都是正确的,就可以直接得到答案(这显然对应于o)。
根据上述假设,问题可以通过以下两个步骤来解决:
1. 确定问题涉及的 Freebase 中的候选实体。给定一个问题 Q,我们需要找出实体提及(mention)X,那么名称或别名与实体提及相同的所有实体将组成实体候选 E。现在 E 中的所有实体都具有相同的实体名称,因此我们暂时无法区分他们。具体地,模型中将命名实体识别转换成了基于 Bi-LSTM 完成的序列标注任务。
2. 所有与 E 中的实体相关的关系都被视为候选关系,命名为 R。我们将问题转换为模式 P,它是通过用 <e> 替换问题中的提及而创建的。为了找出与问题真正相关的关系,我们将 P 与 R 中的每个关系进行比较并对它们进行评分,然后将得分最高的关系作为最终结果。
为了更好地进行关系匹配,模型从单词字面表达和语义两个层面对自然语言进行了建模。具体操作如下图所示:
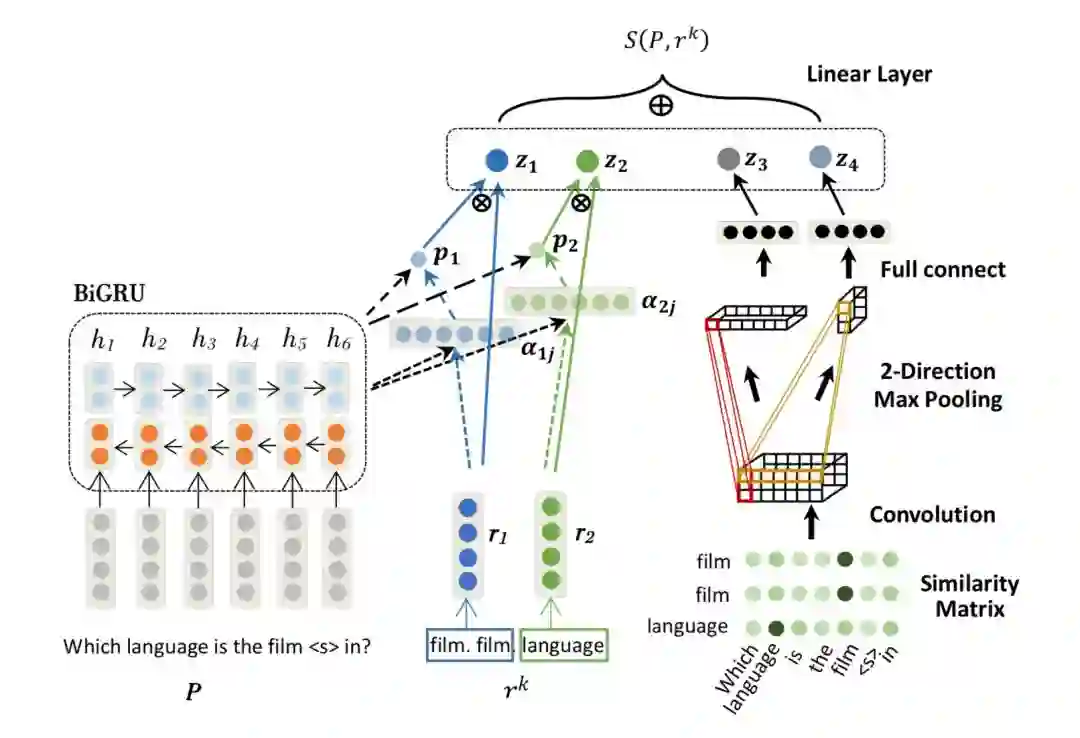
图中所示的 AR-SMCNN 模型,输入是经替换 mention 后的问题模版(pattern)P 和候选关系 rk。
模型左边的部分是结合了 attention 机制的 BiGRU,用于从语义层面进行建模。右边的部分是 CNN 上的相似性矩阵,用于从字面角度进行建模。最终将特征 𝑧1,𝑧2,𝑧3,𝑧4 连接在一起并通过线性层得到最终的候选关系分数 𝑆(𝑃,𝑟𝑘)。
实验结果
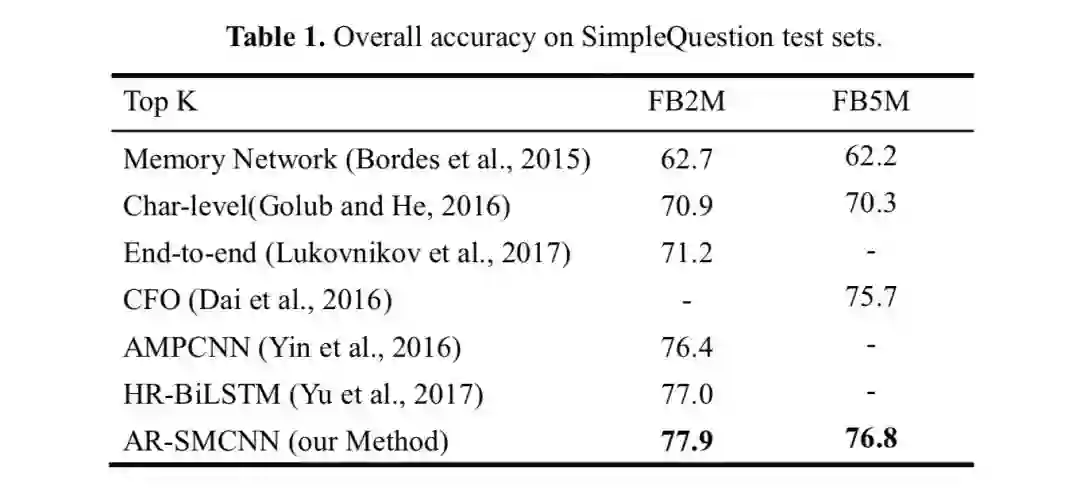
如表 1 所示,文中提出的方法在 FB2M 和 FB5M 设置上达到了 77.9% 和76.8% 的精确度,分别超过了之前的最佳结果 0.9% 和 1.1%。
总结
在这篇文章中,作者提出了一种基于神经网络的新颖方法来回答大规模知识库中的单关系问题,它利用 RNN 和 CNN 的优势互补来捕获语义和文字相关信息。通过省略实体匹配模型使得模型简单化,所提出的方法实现了有竞争力的结果。
尽管所提出的方法仅限于单关系问题,但这项工作可以作为未来开发更先进的基于神经网络的 QA 方法的基础,可以处理更复杂的问题。证实了人机协作的有效性,但是 MQS 算法复杂度太高,导致运行时间过长。
NAACL HLT 2018

■ 链接 | http://www.paperweekly.site/papers/1911
■ 解读 | 邓淑敏,浙江大学博士生,研究方向为知识图谱与文本联合表示学习
动机
机器学习一直是许多 AI 问题的典型解决方案,但学习过程仍然严重依赖于特定的训练数据。一些学习模型可以结合贝叶斯建立中的先验知识,但是这些学习模型不具备根据需要访问任何结构化的外部知识的能力。
本文的目标是开发一种深度学习模型,可以根据任务使用注意力机制从知识图谱中提取相关的先验知识。本文意在证明,当深度学习模型以知识图谱的形式访问结构化的知识时,可以用少量的标记训练数据进行训练,从而降低传统的深度学习模型对特定训练数据的依赖。
模型
模型的输入是一组句中的词构成的词向量序列 x=[x_1, x_2,...,x_T],经过一个 LSTM 单元得到每个词向量的隐藏层状态 h_t = f(x_t, h_{t-1}),然后将得到的隐藏层状态向量加和平均得到 o = 1/T(\sum_{t=1}^{T}h_t)。根据可以计算上下文向量 C=ReLU(o^T W)。
实体和关系对应的上下文向量分别与实体和关系的向量相乘,经过softmax操作,算出每个实体和关系的权重 \alpha_{e_i}, \alpha_{r_i}。其中,实体和关系的向量是通过 DKRL 模型(一种结合文本描述的知识图谱表示学习模型)计算得到。
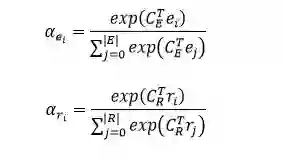
然后将文本中的所有实体和关系分别根据前面算出的权重进行加权平均,从而得到文本中所有实体和关系的向量 e, r。
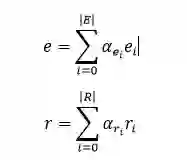
根据 TransE 的假设 (h+r≈t),构建事实元组 F=[e,r,e+r],将这个输入 LSTM 模型中进行训练,得到文本分类的结果。
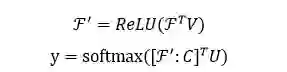
计算文本中实体和关系表示的原始模型架构如下图所示:
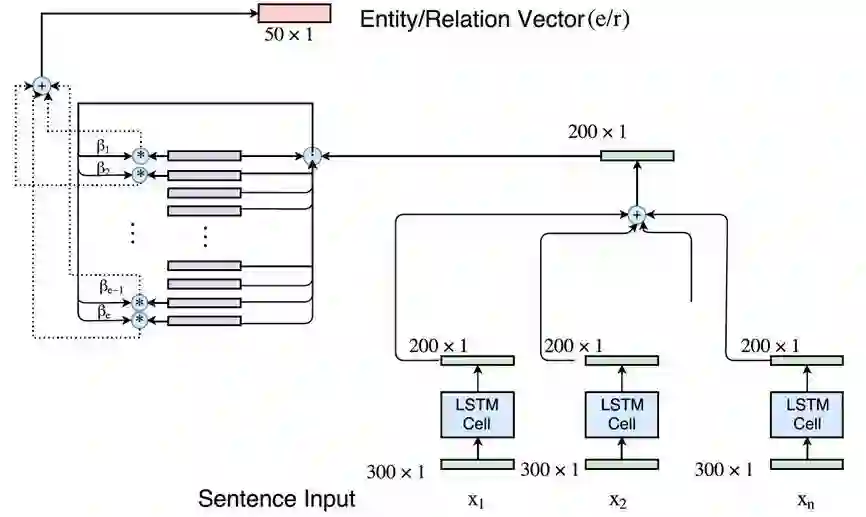
将计算实体和关系表示的模型与文本分类的 LSTM 模块进行联合训练,联合模型架构如下图所示。
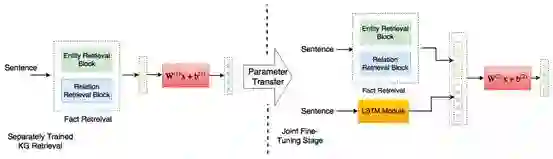
文本中实体和关系的数目很大,为每一个实体和关系分别计算权重开销不菲。为了减少注意力空间,本文利用 k-means 算法对实体和关系向量进行聚类,并引入了基于卷积的模型来学习知识图谱实体和关系集的表示。
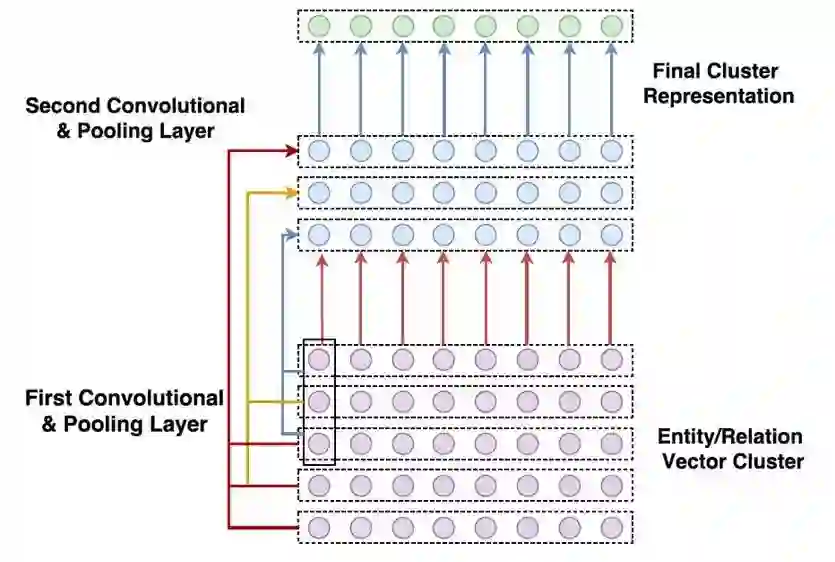
实验
本文使用了 News20,DBPedia 数据集来解决文本分类的任务,使用斯坦福自然语言推理(SNLI)数据集进行自然语言推断的任务。还使用了 Freebase (FB15k) 和 WordNet (WN18) 作为相关的知识库输入。
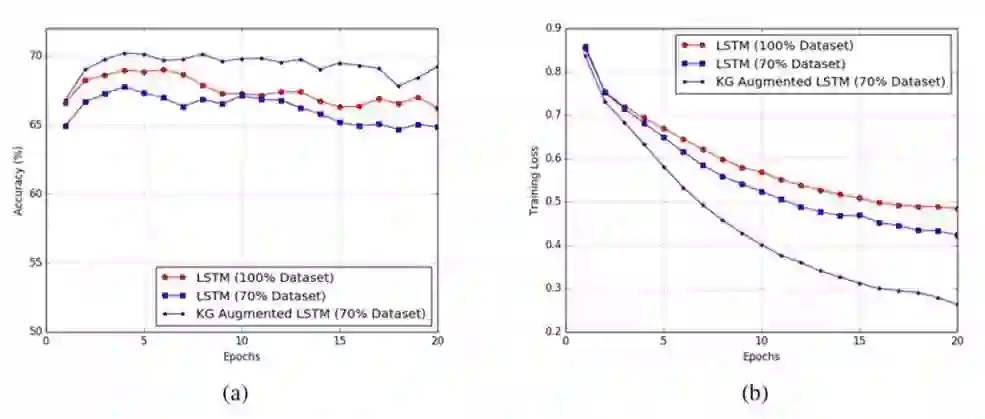
图 (a)、图 (b) 分别表明,在 SNLI 数据集上训练的准确度和损失函数值。实验中分别比较 100% 数据集,70% 数据集,以及 70% 数据集 + KG 三种情况输入的结果。
可以发现,引入 KG 不仅可以降低深度学习模型对训练数据的依赖,而且还可以显著提高预测结果的准确度。此外,本文提出的方法对大量的先验信息的处理是高度可扩展的,并可应用于任何通用的 NLP 任务。
AAAI 2018

■ 链接 | http://www.paperweekly.site/papers/1909
■ 解读 | 高桓,东南大学博士生,研究方向为知识图谱、自然语言处理
动机
传统的知识图谱问答主要是基语义解析的方法,这种方法通常是将问题映射到一个形式化的逻辑表达式,然后将这个逻辑表达转化为知识图谱的查询例如 SPARQL。问题的答案可以从知识图谱中通过转化后的查询得到。
然而传统的基于语义解析的知识库问答会存在一些挑战,如基于查询的方法只能获取一些明确的信息,对于知识库中需要多跳才能获取的答案则无法回答。举例来说当问到这样一个问题“Who wrote the paper titled paper1?,传统的基于语义解析的方法可以获得如下语句进而可以查到 paper1 这个实体。
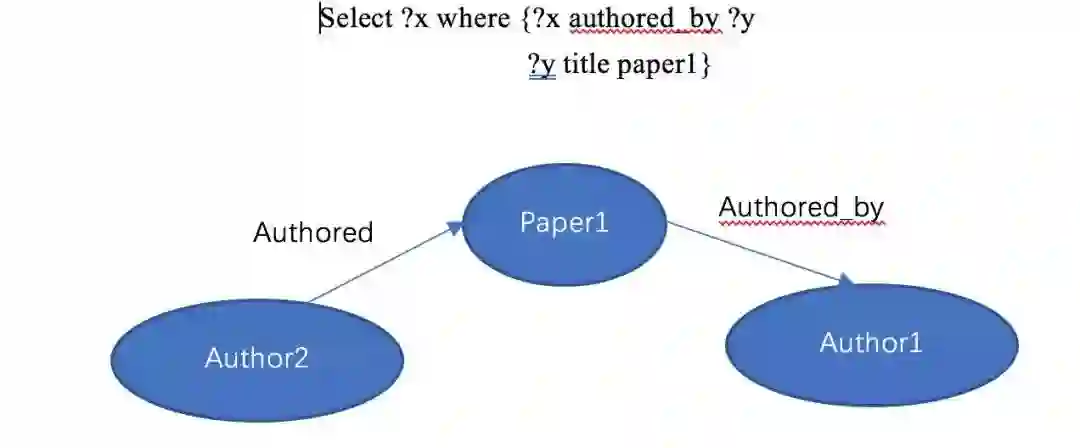
但是在上例中,当我们询问 Who have co-authored paper with author1? 由于缺乏 co-author 这个明确的关系,传统的方法则无法转换成合适的查询语句。但实际上,在上例中 author2 则是 author1 在 paper1 中的 co-author。
另一个对于传统方法的挑战是,在传统方法中问句中含有的实体通常都使用很简单的方法来匹配到知识库上,例如字符串匹配。但实际场景中用户的输入可能是通过语音识别转换而来或者是用户通过打字输入而来。因此用户的输入很难确保不存在一定的噪声。在具有噪声的场景下,问句中的实体则很难直接准确的匹配到知识库上。
因此本文提出了一个端到端的知识库问答模型来解决以上两个问题。
创新点
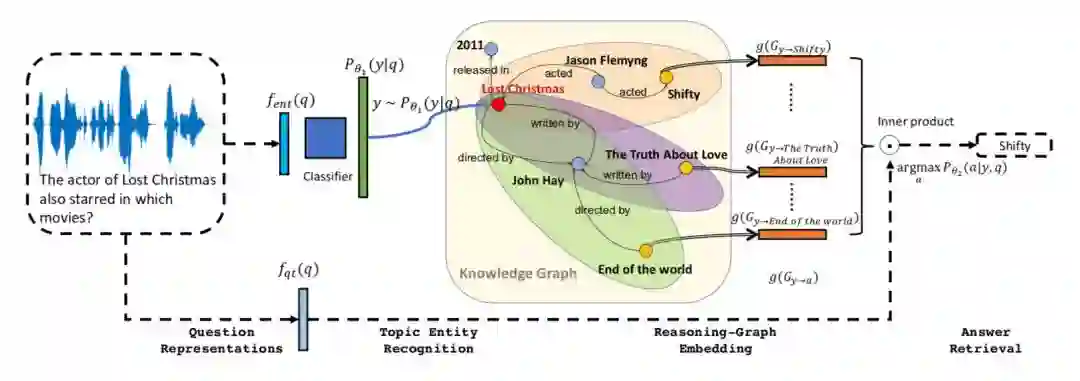
▲ 模型框架图
本文提出的模型如上图所示,这个模型为了克服上述所说的问题则将模型分为两个部分:
第一部分是通过概率模型来识别问句中的实体。如问句 who acted in the movie Passengers? 我们希望能将 Passengers 识别出来。但由于训练数据中的实体没有被标注出来,因此这个识别的实体将被看成一个隐变量。整个识别实体的过程如下:
1. 先将输入的问句 q 进行编码,将问句 q 转换为一个维度是 d 的向量;
2. 随后将图谱中每个实体都转化为一个向量;
3. 通过 softmax 计算在 q 下图谱中每个实体是 q 中实体的概率。
该过程在整个模型框架图的左上部分在上例中输入问句 The actor of lost Christmas also starred in which movies,通过算法在图中找到 lost Christmas 为问句中对应的实体。
第二部分则是在问答时在知识图谱上做逻辑推理,在推理这部分的工作中我们给出了上一步识别的实体和问句希望系统能给出答案。由于在整个系统的学习过程中没有人来标注在问答时使用的推理规则,因此在问答时使用的规则将被学习出来。整个推理过程如下所示:
1. 通过另一个网络对问句 q 进行编码,将 q 转化为一个维度是 d 的向量;
2. 通过一个 Reasoning graph embedding,对 y 的相邻实体进行编码;
3. 通过 softmax 计算通过 y 推理找到实体是问题 q 答案的概率;
4. 如果推理没有达到限定的步数则返回 2,将原来 y 相邻的实体转换为 y 进而进行推理。
整个推理过程则在上图的右半部分,该部分分别计算推理时实体是问句答案的概率,最后得到实体 shifty 对于问句 q 概率最大。而概率最大的实体到 y 的路径则是推理所获取的路径为 lost Christmas acted Jason Flemyng acted Shifty。
最后算法通过 EM 进行优化,整体训练的思路是希望第一部分和第二部分的概率同时最大。
实验结果
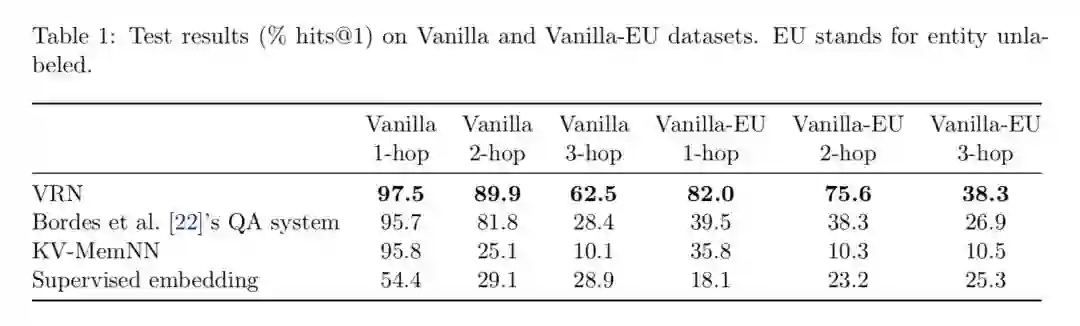
实验结果显示在 Vanilla、NTM 和 Audio 数据集下,算法的效果都超过传统的 QA 系统,同时在需要推理的问题中性能更为显著。
AAAI 2018

■ 链接 | http://www.paperweekly.site/papers/1910
■ 源码 | http://sentic.net/downloads/
■ 解读 | 徐康,南京邮电大学讲师,研究方向为自然语言处理、情感分析和知识图谱
概述
目前大部分人工智能的研究都集中在基于统计学习的方法,这些方法需要大量的训练数据,但是这些方法有一些缺陷,主要是需要大量的标注数据而且是领域依赖的;不同的训练方法或者对模型进行微调都会产生完全不同的结果;这些方法的推理过程都是黑盒的。
在自然语言处理领域中,人工智能科学家需要减少统计自然语言处理领域和其他理解自然语言急需的领域(例如,语言学、常识推理和情感计算)之间的隔阂。在自然语言处理领域,有自顶向下的方法,例如借助符号(语义网络)来编码语义;也有一种自底向上的方法,例如基于神经网络来推断数据中的句法模式。
单纯地利用统计学习的方法主要通过历史数据建模关联性以此“猜测”未知数据,但是建模自然语言所需要的知识远不止此。因此,本论文工作的目的就是结合人工智能领域中统计学习和符号逻辑的方法进行情感分析任务。
模型
本论文首先设计了一种 LSTM 模型通过词语替换发现“动词-名词”概念原语(概念原语就是对常识概念的一种的抽象,概念“尝”、“吞”、“啖”和“咀嚼”的原语都是“吃”。),为情感分析任务构建了一个新的三层知识表示框架 SenticNet5。
SenticNet5 建模了普遍关联现实世界对象、行为、事件和人物的内涵和外延信息,它不是盲目地依赖关键词和词语共现模式,而是依赖关联常识概念的隐含语义。
SenticNet5 不再单纯地使用句法分析技术,同时通过分析短语关联的概念,而不是短语本身(因为短语本身经常并不显式地表达情感)挖掘微妙表达的情感。
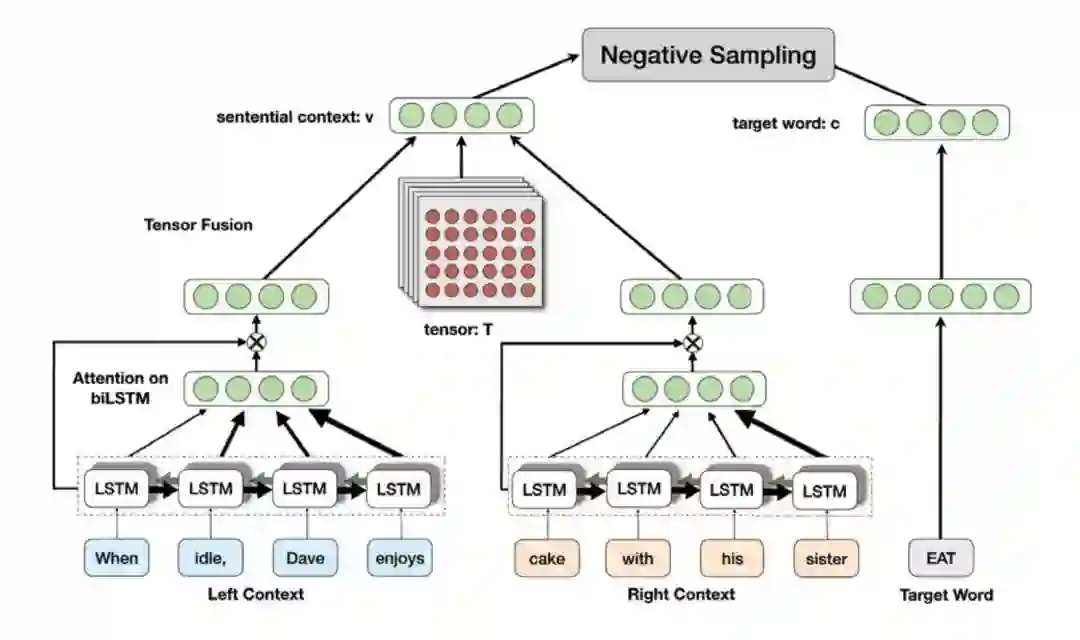
▲ 图1:上下文语境向量和词向量生成框架
本论文声称是情感分析应用中第一个提出结合符号逻辑和统计学习的方法。本论文的核心思想就是提出一种概念原语的,也就是使用一种自顶向下的方法泛化语义相关的概念,例如,“munch_toast”和“slurp_noodels”可以泛化成概念原语“EAT_FOOD”。这种做法背后核心的思想就是使用有限的概念上的原语描述包含情感信息的概念。
本论文工作的第一步就是挖掘概念原语,具体模型如图 1 所示,该模型的核心思想就是属于相同原语下的概念词语跟目标词语在语义上关联并且具有相似的上下文语境。
举个例子,句子“他刚刚咀嚼几口粥”,这里的“咀嚼”和“狼吐虎咽”属于相同的概念原语“吃”,所以这里的句子“狼吞虎咽”代替“咀嚼”也说得通。
该模型左边建模目标词语的左上下文和右上下文合成目标词语的上下文语境表示,模型的右边建模目标词语的表示,基于这个模型就可以找到属于同一原语的词语,也就是讲这些词语聚类,然后人工标注原语。
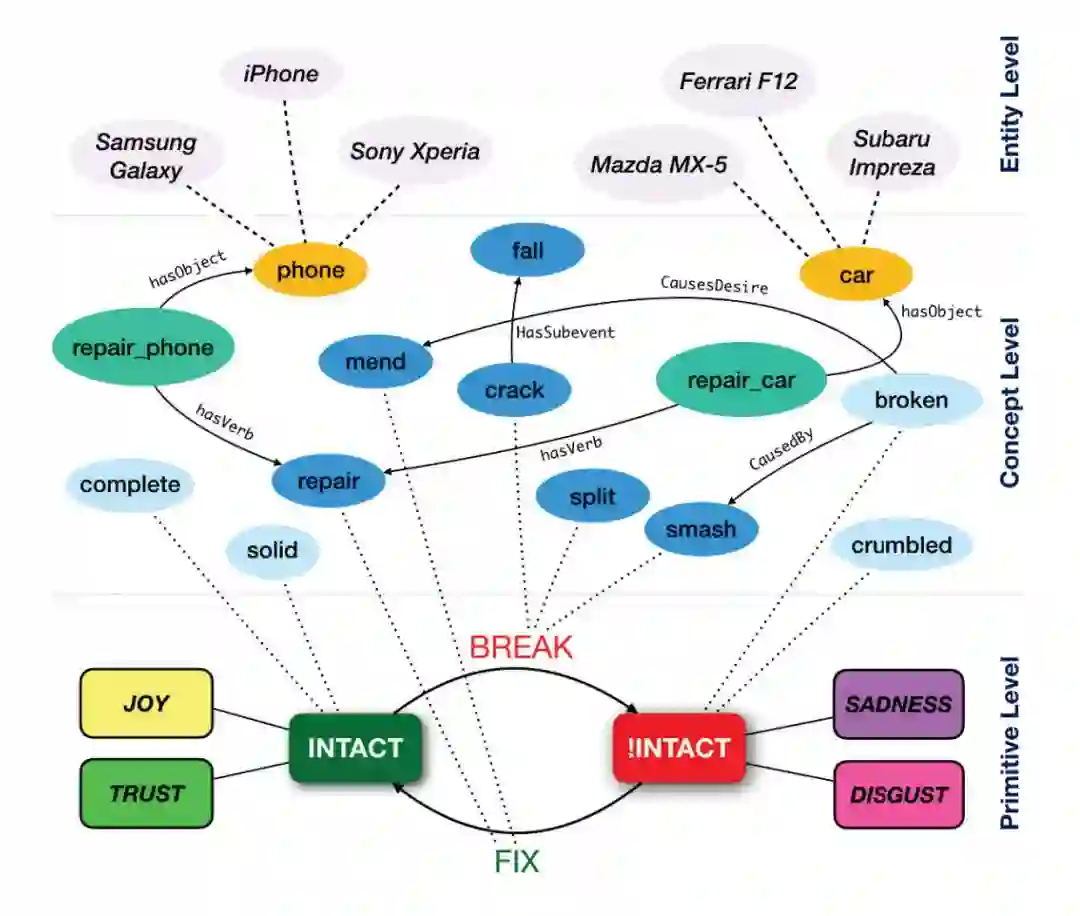
因为 SenticNet5 是一个三层的语义网络(如图 2 所示),原语层包含基本的状态和行为(状态之间的交互),包含状态的情感信息;概念层通过语义关联链接的常识概念;实体层属于常识概念的实例。
例如,在原语层,状态“inact”对应情感“joy”和概念层上的形容词概念“complete”,行为“break”对应动词概念“crack”和“split”;在概念层,概念短语“repair_phone”对应概念“repair”和“phone”;同时概念“phone”又对应实例层上的“iPhone”。
这样我们分析“iPhone”的时候虽然本身不包含情感信息,但是跟“repair”在一起,“repair”对应状态原语“fix”,“fix”又转到正面的情感“intact”,因此“iPhone”就包含了正面的情感。
实验
在实验部分,本论文主要评估了深度学习方法的性能和 SenticNet5 作为知识库在情感分析任务中的效果。从图 3,4,5 的结果看来本论文的方法在两个人物都有 3% 左右的提升。
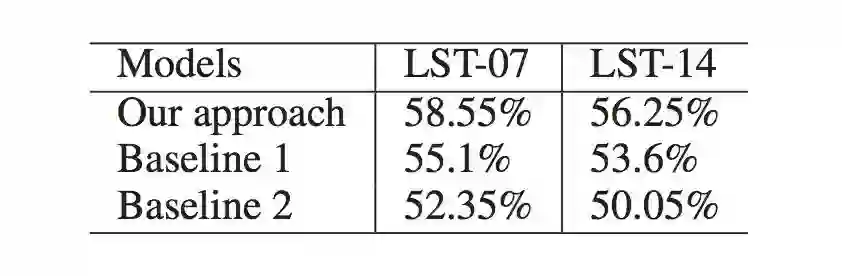

▲ 图4:SenticNet5在Biltzer数据集上情感分析的性能

▲ 图5:SenticNet5在Movie Review数据集上情感分析的性能
AAAI 2018

■ 链接 | http://www.paperweekly.site/papers/1913
■ 源码 | https://github.com/TimDettmers/ConvE
■ 解读 | 汪寒,浙江大学硕士,研究方向为知识图谱和自然语言处理
本文主要关注 KG Link prediction 问题,提出了一种多层卷积神经网络模型 ConvE,主要优点就是参数利用率高(相同表现下参数是 DistMult 的 8 分之一,R-GCN 的 17 分之一),擅长学习有复杂结构的 KG,并利用 1-N scoring 来加速训练和极大加速测试过程。
背景
一个 KG 可以用一个集合的三元组表示 G={(s,r,o)},而 link prediction 的任务是学习一个 scoring function \psi(x),即给定一个三元组 x=(s,r,o) ,它的 score \psi(x) 正于与 x 是真的的可能性。
Model ConvE
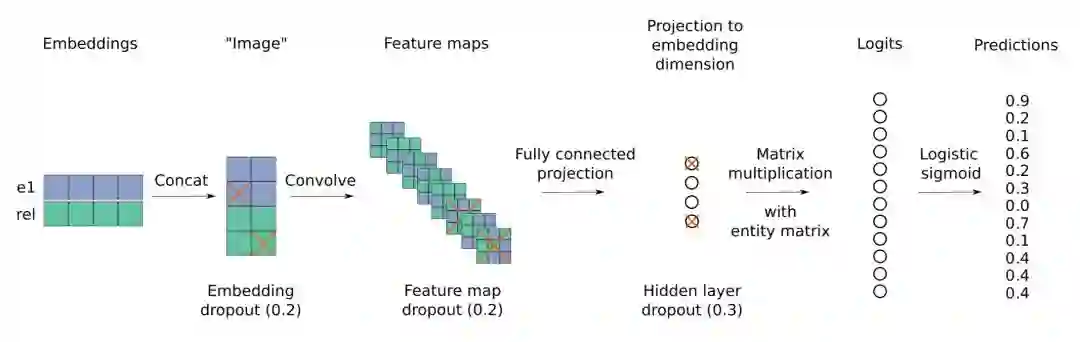
这是 ConvE 的整体结构,把输入的实体关系二元组的 embedding reshape 成一个矩阵,并将其看成是一个 image 用卷积核提取特征,这个模型最耗时的部分就是卷积计算部分。
为了加快 feed-forward 速度,作者在最后把二元组的特征与 KG 中所有实体的 embedding 进行点积,同时计算 N 个三元组的 score(即1-N scoring),这样可以极大地减少计算时间,实验结果显示,KG 中的实体个数从 100k 增加到 1000k,计算时间也只是增加了 25%。
ConvE 的 scoring function:
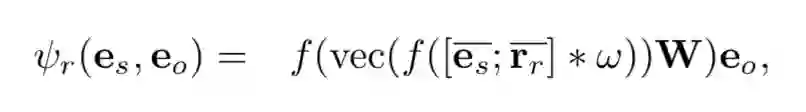
Loss function 就是一个经典的 cross entropy loss:
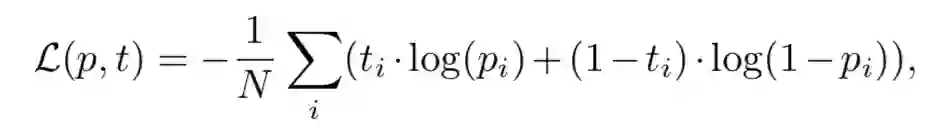
Test Set Leakage Problem
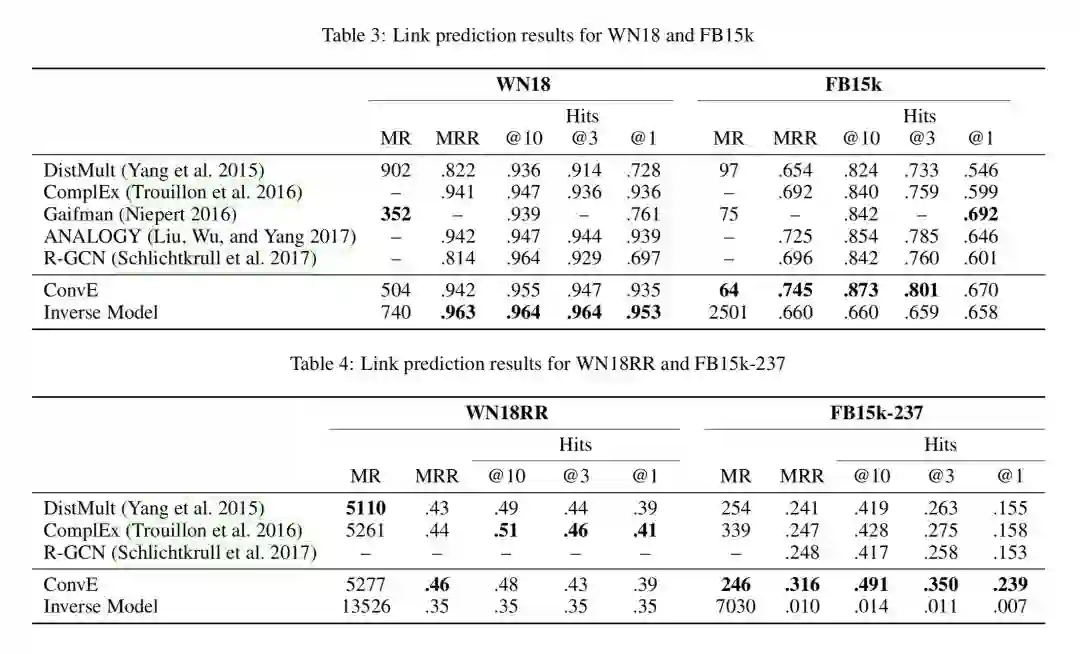
WN18 和 FB15k 都有严重的 test set leakage problem,即测试集中的三元组可以通过翻转训练集中的三元组得到,举个例子,测试集中有 (feline, hyponym, cat) 而训练集中有 (cat, hypernym, feline),这个问题的存在导致用一个很简单的 rule-based 模型就可以在某些数据集上实现 state-of-the-art 性能。
作者构造了一个简单的 rule-based inverse model 来衡量这个问题的严重性,并利用消去了 inverse relation 的数据集 WN18RR 和 FB15k-237 来进行实验,实验结果如下:
AAAI 2018

■ 链接 | http://www.paperweekly.site/papers/1914
■ 源码 | https://github.com/bxshi/ConMask
■ 解读 | 李娟,浙江大学博士生,研究方向为知识图谱和表示学习
本文解决知识库补全的问题,但和传统的 KGC 任务的场景有所不同。以往知识库补全的前提是实体和关系都已经在 KG 中存在,文中把那类情况定义为 Closed-World KGC。从其定义可以发现它是严重依赖已有 KG 连接的,不能对弱连接有好的预测,并且无法处理从 KG 外部加入的新实体。
对此这篇文章定义了 Open-World KGC,可以接收 KG 外部的实体并链接到 KG。论文提出的模型是 ConMask,ConMask 模型主要有三部分操作:
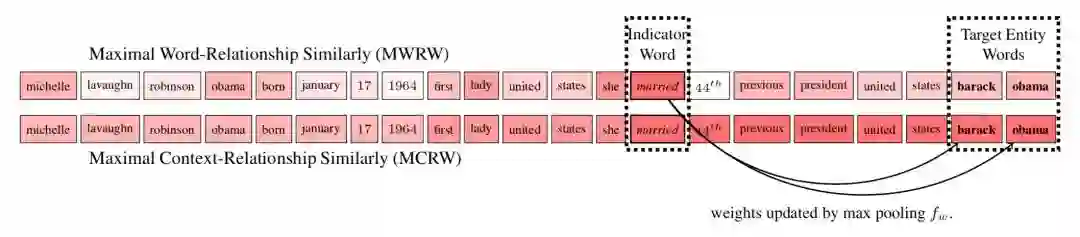
1. Relationship-dependent content masking
强调留下和任务相关的词,抹去不相关的单词; 模型采用 attention 机制基于相似度得到上下文的词和给定关系的词的权重矩阵,通过观察发现目标实体有时候在权重高的词(indicator words)附近,提出 MCRW 考虑了上下文的权重求解方法。
2. Target fusion
从相关文本抽取目标实体的 embedding(用 FCN 即全卷积神经网络的方法);这个部分输入是 masked content matrix,每层先有两个 1-D 卷积操作,再是 sigmoid 激活函数,然后是 batch normalization,最后是最大池化。
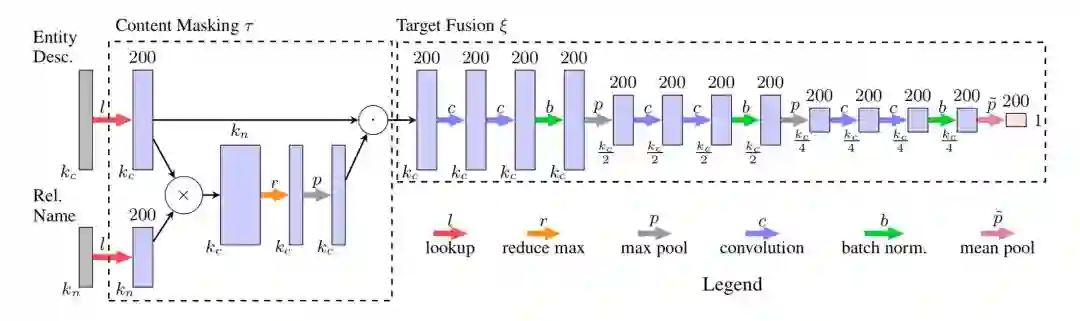
为避免参数过多,在得到实体名等文本特征时本文选用语义平均来得到特征的 embedding 表示。
3. Target entity resolution
通过计算 KG 中候选目标实体和抽取的实体的 embedding 间的相似性,结合其他文本特征得到一个 ranked list。本文设计了一个 list-wise ranking 损失函数,采样时按 50% 比例替换 head 和 tail 生成负样本,S 函数时 softmax 函数。
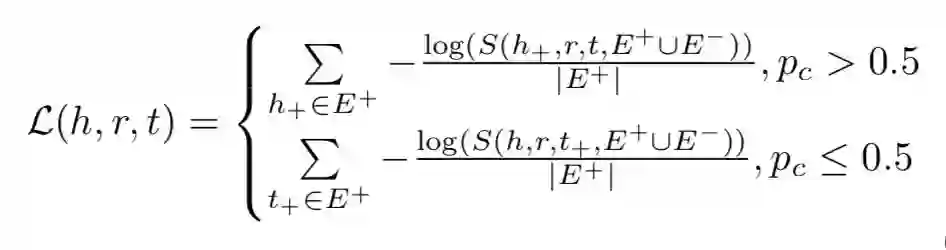
论文的整体模型图为:
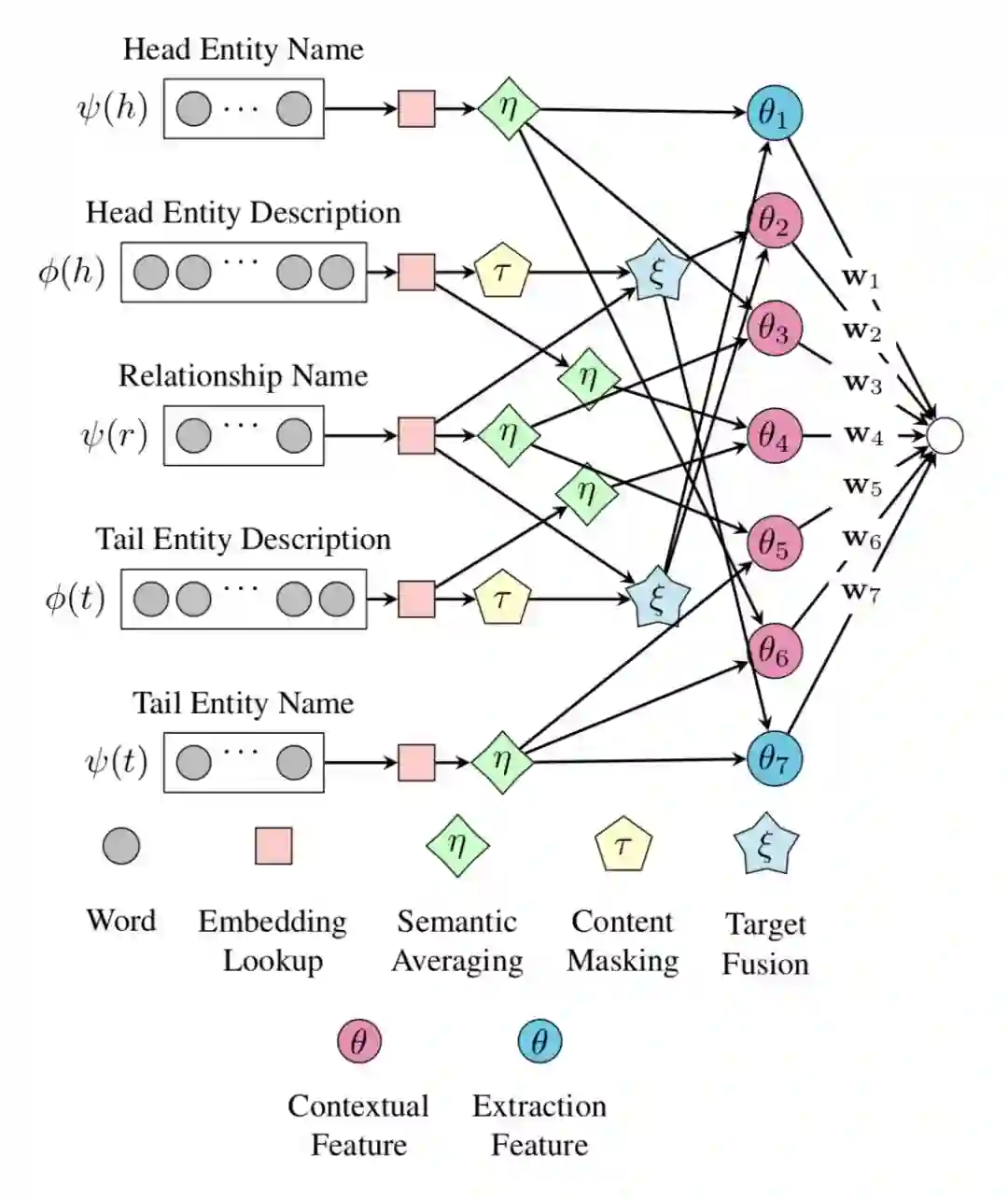
本文在 DBPedia50k 和 DBPedia500k 数据集上取得较好的结果,同时作者还添加了 Closed-World KGC 的实验,发现在 FB15k,以及前两个数据集上效果也很不错,证明了模型的有效性。


▲ 戳我查看招聘详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。







