【AIDL专栏】鲁继文:面向视觉内容理解的深度度量学习
AIDL简介
“人工智能前沿讲习班”(AIDL)由中国人工智能学会主办,旨在短时间内集中学习某一领域的基础理论、最新进展和落地方向,并促进产、学、研相关从业人员的相互交流。对于硕士、博士、青年教师、企事业单位相关从业者,预期转行AI领域的爱好者均具有重要的意义。2018年AIDL活动正在筹备,敬请关注公众号获取最新消息。
导读
中国人工智能学会举办的第四期《人工智能前沿讲习班》专题为“智能感知与交互”。来自清华大学自动化系的鲁继文副教授做了题为《面向视觉内容理解的深度度量学习》的报告。本文根据鲁继文博士的报告内容整理发布,对相关领域研究工作具有长期价值。
「关注本公众号,回复"鲁继文",获取完整版PPT」
讲者简介
鲁继文,博士,清华大学自动化系副教授,博士生导师,IEEE高级会员。研究方向为计算机视觉、模式识别和机器学习,发表IEEE汇刊论文55篇(其中PAMI论文9篇),ICCV/CVPR/ECCV/NIPS论文32篇,ESI热点论文和高被引用论文9篇,论文被Google累计引用5000余次,SCI他引1400余次。曾任或现任6个SCI国际期刊的编委,包括IEEE Transactions on Circuits andSystems for Video Technology、Pattern Recognition、Pattern Recognition Letters等。现任IEEE信号处理学会多媒体信号处理技术委员会委员,IEEE信号处理学会信息取证与安全技术委员会委员,IEEE电路与系统学会多媒体系统与应用技术委员会委员等。作为项目负责人主持国家重点研发计划课题和国家自然科学基金面上项目等国家级项目3项。

前言:深度度量学习及其应用
度量学习是机器学习领域比较重要的一个概念,主要研究数据之间的距离与相似性,从而指导对数据的更高层次处理。将深度学习引入度量学习,就有了深度度量学习的概念。深度度量学习在视觉内容理解,尤其是各种高层视觉任务分析方面有很多应用。
一、视觉内容理解
视觉内容理解是指如何从图像和视频中提取有用信息,帮助我们更好地理解视觉目标内容。该领域一个重要应用是视觉识别。人脸识别是该领域很重要的应用典型。另一个典型是行人再识别,其主要解决的问题在摄像机网络中跨摄像头地识别行人,如果能有效地确定行人的轨迹,就可以对他的行为进行更好的分析和理解。
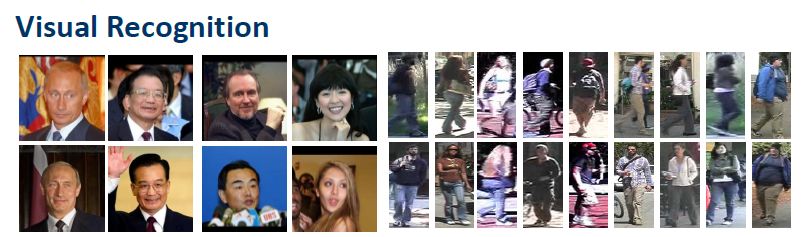
视觉内容理解还有一个很重要的任务是视觉目标跟踪。给定监控场景,如何对其内容进行实时、动态、快速的有效跟踪。很多时候视觉目标跟踪是在线学习的过程,比如只给出第一帧目标的位置,算法要自适应地找到目标在后续帧的位置。
第三个应用,大规模图像搜索。大规模图像搜索是指在千万数量级的数据库内找到与给定图像最相似的图像。如果数据库不大,很多方法都可以做的很好,但是数据库一旦变得很大,搜索精度和搜索速度都会变困难。
所以在典型的视觉理解任务中,如何有效的计算视觉目标的相似性是很重要的指标。传统的欧式距离或余弦距离弱点在于无法有效描述数据的语义信息。另外,同类目标在不同环境下搜集到的样本在空间中往往呈非线性分布,这是视觉内容理解所面临的核心挑战。以人脸图像为例,同一个人脸在不同光照、姿态、表情、光照、背景、遮挡等因素干扰下,采集的样本在特征空间内高度混叠。这种情况给识别、检测、搜索都带来很大的挑战。此时如何有效描述样本之间的相似性就显得尤为关键。

欧式距离的弱点是没有把数据的统计信息或者是协方差信息考虑进去,因此计算机视觉领域常用马式距离,它的好处在于考虑了协方差信息,可以更有效地描述样本相似度。但是马式距离的计算方式往往是固定的,辨别性不高,因此又有了度量学习。度量学习的核心思想是利用训练集数据信息计算出判别力较强的PSD矩阵M。

根据标签类型,度量学习可以分监督学习、非监督学习、半监督学习;根据获取标签的度量类型可以分成弱监督学习和强监督学习;根据度量学习的结构,可以分为浅层学习和深层学习;根据学习度量的个数,可以分为单度量学习和多度量学习。
在浅层的度量学习方面,代价敏感的度量学习比较有代表性。度量学习往往追求更高的识别率,但是在实际应用中算法出现错误可能造成重要损失,所以以识别率为驱动的度量学习方法往往并不是最佳选择。基于以上思想,就有了代价敏感的度量学习,其代价矩阵对不同的分类错误计算不同的代价。
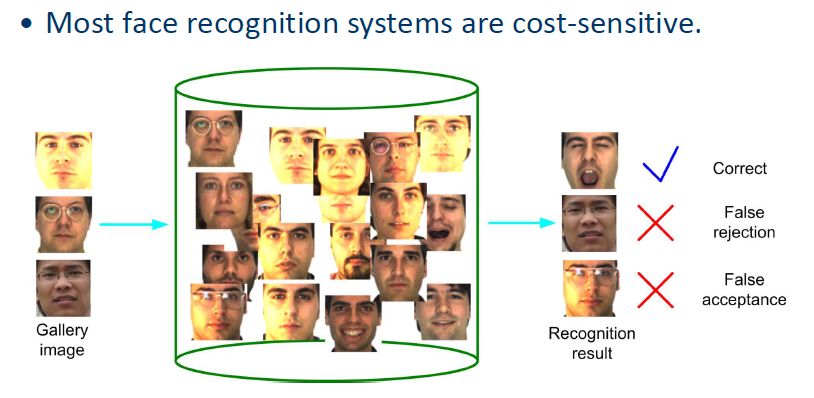
有很多视觉任务的负样本多于正样本,此时可以引入代价敏感的思想。负样本对可能比正样本对多很多,但是有些负样本对判别能力非常高。通过机器学习的算法找到这种负样本对,用来进行度量学习的设计,就可以解决问题。
二、深度度量学习
深度度量学习与传统的度量学习相比,核心不同点是度量不再基于线性方法,而是通过神经网络设计目标函数,通过目标函数修正网络参数。在设计网络时有不同的监督信息,分为弱监督和强监督。
想要度量学习利用线性方法解决非线性问题,可以用基于核的方法。首先把样本映射到高维核空间,在高维核空间里再去学度量。此方法缺点在于找不到度量的学习过程。而深度学习最大的优点在于能够对数据进行有效的非线性建模,所以把深度学习思想引入到度量学习里,就有了深度度量学习。
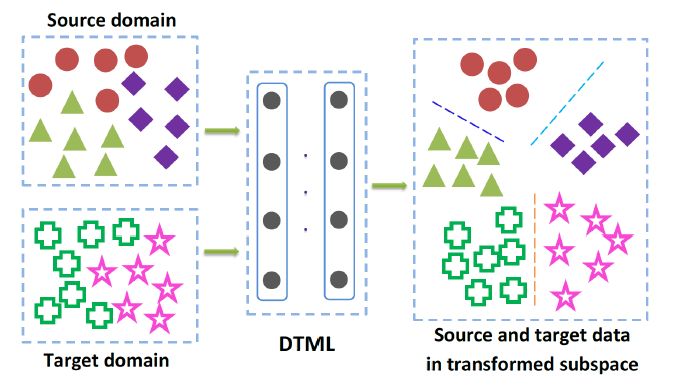
深度度量学习的训练集和测试集应该来自同一数据集,但在实际应用中可能做不到这一点,这就需要对特征、度量进行迁移,所以就有了深度迁移度量学习。对两个数据库,在一个数据库上学习到的信息可以迁移到另一个数据库上去。两个数据集的数据在网络顶层足够靠近,才能保证学到的信息能够迁移。
深度度量学习还可以解决多视图学习问题。同一个数据可以有多种表达,不同表达之间会有共同信息。将这种信息经过网络训练,希望在网络顶层存在这样的空间:在该空间内既有不同特征里面共享的信息,又有不同特征各自独享的信息。如何将共享信息和独享信息融合以进行联合学习,是一个问题。第二个问题,如何优化共享信息和独享信息,使得网络顶层的共享信息差别尽可能小,而独享信息尽可能保留自身的特点。
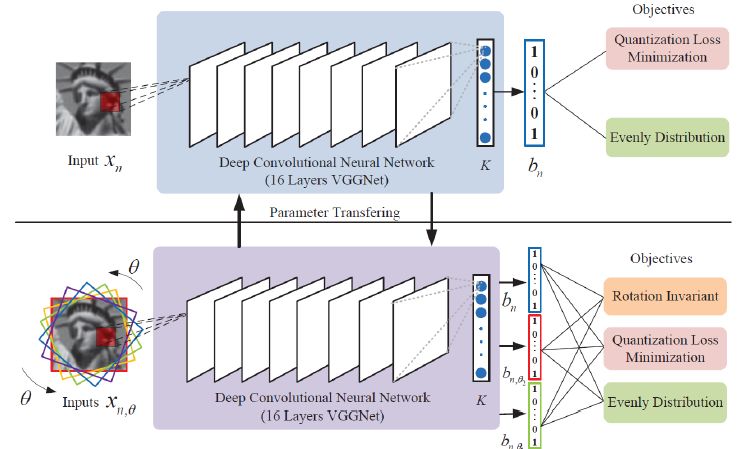
深度度量学习还可以做图像的二值制描述,准确说是对图像整体做二值制描述。比如在大规模图像搜索中,把图像数据映射到低维紧凑的二值空间,对节省存储空间和提高运算速度都有帮助。传统的哈希学习是线性影射,所以把深度度量学习思想嵌入到哈希学习过程中去,可以带来很好的效果。在网络顶层设计二值的过程中,从实质向量到二值向量映射的损失越小越好;对每个Bit,希望训练集一半是1,一半是0;Bit与Bit之间尽可能独立。以上约束可以保证非常短的二值码就可以很好地描述图像。
三、总结和展望
无论深度度量学习还是浅层度量学习,多数情况下都可以有效地描述样本相似度,只要目标函数设计得合格,对网络的性能都会有帮助。对于不同的视觉内容理解,很多时候需要考虑领域知识或者先验知识,把这些知识嵌入到目标函数里,可以保证学到的方法更有针对性。
未来还有很多工作需要探索,比如大规模的度量学习,非线性度量学习,或者鲁棒的度量学习等。

Q&A
提问:对于特征融合,您的方法是每个特征独立学习之后再加权,不同特征在一起学习是否可以?这两种方法效果有区别么?
鲁继文:这要取决于特征差异性大不大,如果特征之间差异很大,独立学习再加权效果可能不好,如果特征之间差异不大,还可以试试。
提问:您提到引入代价敏感的思想可以使差异性变得更明显,在目标函数中怎么体现这种思想?
鲁继文:可以把不同类别数据的分布看作一种先验。如果类别不同,距离又比较大,代价就很小;如果类别不同,距离很小,对识别很容易造成干扰,这时代价会很大。
提问:深度度量学习是不是都用了自编码的方式?
鲁继文:我们在早期大部分用这种方式,后来也用过卷积神经网络。关键在于数据量的大小,如果数据足够多,可以把网络设计得深一点,如果数据比较少,相对轻量的模型更合适。
扫描下方二维码加入深度度量学习讨论群

感谢AIDL志愿者边学伟协助整理!
志愿者持续招募中,有意者联系微信号"AIDL小助手(ID:must-tech)"

历史文章推荐:
AI综述专栏 | 11页长文综述国内近三年模式分类研究现状(完整版附PDF)
AI综述专栏 | 朱松纯教授浅谈人工智能:现状、任务、构架与统一(附PPT)
【AIDL专栏】罗杰波: Computer Vision ++: The Next Step Towards Big AI




