【论文分享】ICLR2022 HyperDQN: A Randomized Exploration for Deep RL
深度强化学习实验室
Ziniu Li, Yingru Li, Yushun Zhang, Tong Zhang, and Zhi-Quan Luo. HyperDQN: A Randomized Exploration Method for Deep Reinforcement Learning. In Proceedings of 10th International Conference on Learning Representations, 2022.
论文地址:
https://openreview.net/pdf?id=X0nrKAXu7g-
Introduction
强化学习的一个难题是与环境交互时的样本效率:好的探索策略可以减小样本复杂度;差的探索策略则可能导致即使交互了很多次,也无法求解到最优策略。具体而言,由于环境是未知的,智能体并不确定从环境得到的反馈是准确的,所以无法贪婪地优化策略来交互。直觉上,一个好的探索策略要不断尝试那些未知的/不确定的动作;但是对于已经比较确信的动作,应该采取最优的动作。因此,智能体要学会量化对环境的不确定性。
经过大量的研究,大家目前比较认可的高效探索策略有Upper Confidence Bound (UCB) 和Thompson Sampling (TS) 两种。简单来讲,UCB方法会设计“exploration bonus”来确保Q-value function是乐观的,这样便不会遗漏掉选择最优动作的可能。Thompon Sampling的方法会通过后验分布来刻画不确定度:如果后验分布比较“宽”,则认为对环境的不确定比较大,如果后验分布比较“窄”,则认为对环境的不确定度比较小。除此之外,通过从后验分布中采样,Thompson Sampling的方法也可以实现像UCB那样的乐观估计。虽然两种方法都有理论保证,但是有大量研究表示Thompson Sampling的方法实际性能会比UCB更好一些。
想要把Thompson Sampling的方法应用在RL里并不那么容易。一个主要的难题是如果更新后验分布。后验分布取决于先验分布和似然函数。如果我们考虑线性模型,那么后验分布更新还是可行的。这种情况下的算法就是著名的Randomized Least-square Value Iteration (RLSVI)。但是RLSVI和Deep RL并不兼容:
RLSVI里假设线性模型有一个比较好的特征(feature),从而可以表达最优的Q-value function。但这这个假设在实际任务中很难满足,因为我们实现不知道一个好的特征是什么,而需要神经网络来不断学习。
当特征在不断变化的时候,RLSVI里的更新公式便不再适用,这意味着后验分布很难求解。
Methodology
我们的工作解决了上面两个难点。基于之前的工作,我们设计了一个end-to-end的方式来同时学习特征和后验分布。我们的模型示意见下面的图片。具体而言,我们的方法里有两个模型: base model和hypermodel。base model就是一个基本的DQN模型;hypermodel则是一个meta model来度量base model的parameter uncertainty(在Thompson Sampling方法里,我们把对环境的不确定度转化为对模型参数的不确定度)。也就是说,base model的参数是从hypermodel里采样得到的。
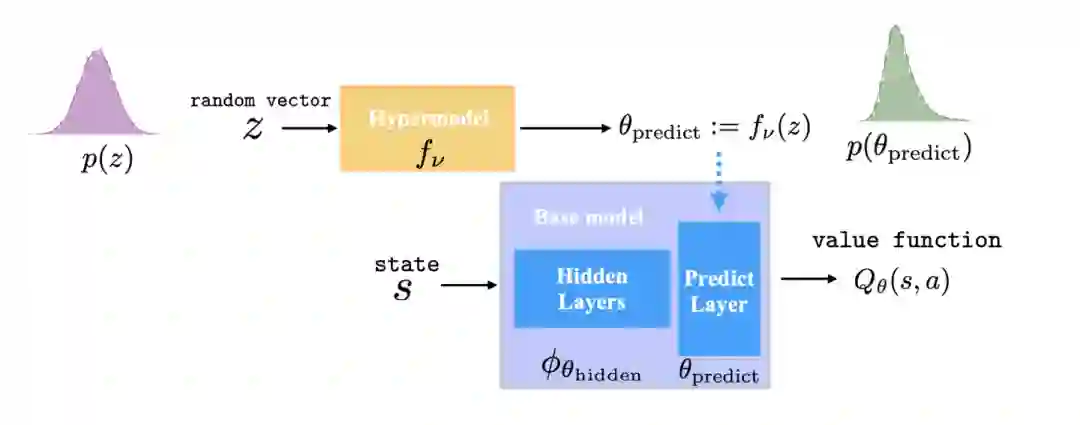
我们希望从数据里,可以同时把base model (feature extractor)和hypermodel (posterior distribution)给学习出来。为此,我们设计了下面的目标函数:
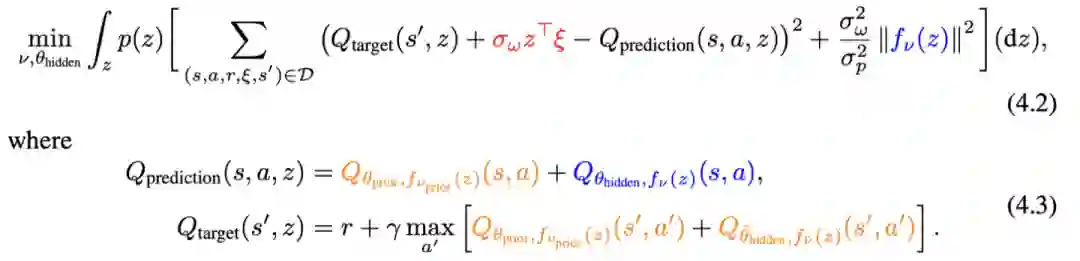
这里是一个高斯分布,$z\top \xi$是一个人为引入的噪声项。(4.2)里的第一项是基本的Q-learning objective,第二项是贝叶斯学习里的先验正则项。与RLSVI类似,(4.2)是一个randomized regression。在一定条件下,我们证明了(4.2)可以被用来近似真实的后验分布。下面定理中提到的(4.1)是(4.2)的简化版本。

Experiment
我们做了大量的实验来验证提出的方法的有效性,这里只展示部分结果。我们考虑了UCB类型的baselines: OPIQ 和 OB2I 以及randomized exploration类型的baselines: BootDQN 和 NoisyNet(具体文献见文章结尾)。
第一个实验是Atari。HyperDQN用20M frames的性能比DQN用200M frames的性能好。

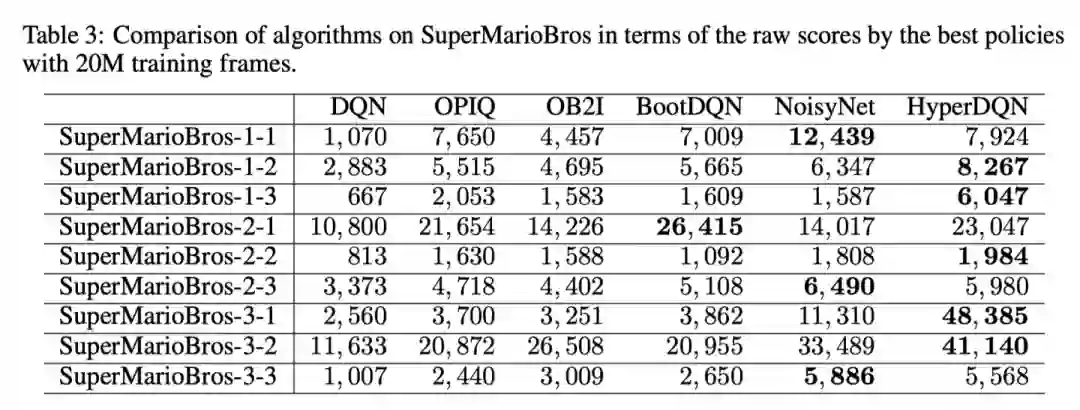
第二个实验是SuperMarioBros。HyperDQN在5/9个游戏中比baselines要好。
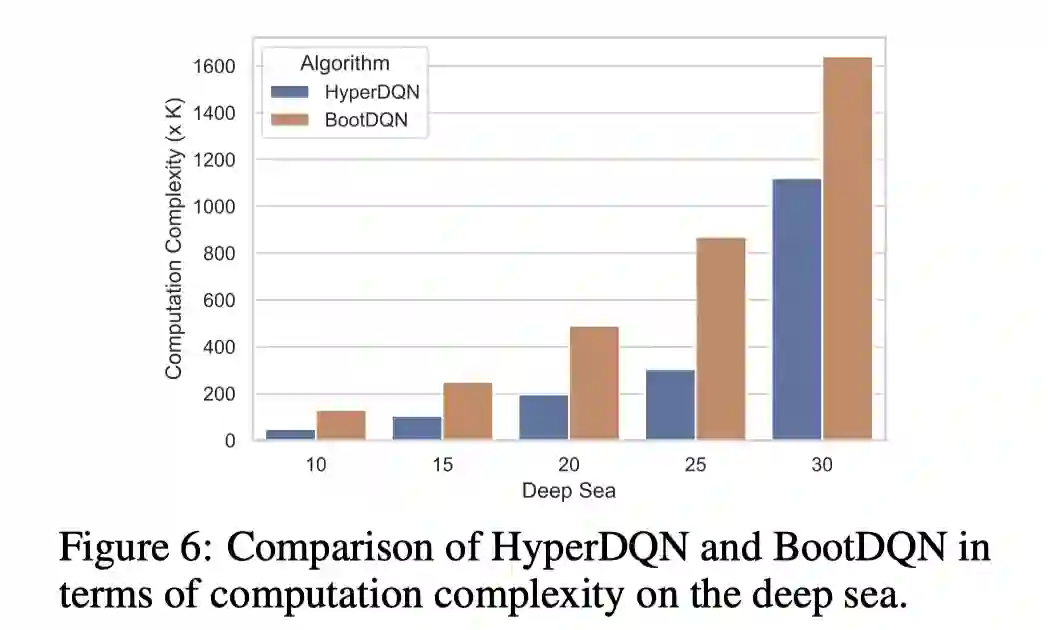
第四个实验是HyperDQN在continuous control的扩展方法HAC。HAC比SAC在稀疏奖励任务CartPole表现更好。

【RLSVI】Ian Osband, Benjamin Van Roy, and Zheng Wen. Generalization and exploration via randomized value functions. In Proceedings of the 33rd International Conference on Machine Learning, pp. 2377–2386, 2016.
【OPIQ】Tabish Rashid, Bei Peng, Wendelin Boehmer, and Shimon Whiteson. Optimistic exploration even with a pessimistic initialisation. In Proceedings of the 8th International Conference on Learning Representations, 2020.
【OB2I】Chenjia Bai, Lingxiao Wang, Lei Han, Jianye Hao, Animesh Garg, Peng Liu, and Zhaoran Wang. Principled exploration via optimistic bootstrapping and backward induction. In Proceedings of the 38th International Conference on Machine Learning, pp. 577–587, 2021.
【BootDQN】Ian Osband, John Aslanides, and Albin Cassirer. Randomized prior functions for deep reinforcement learning. In Advances in Neural Information Processing Systems 31, pp. 8626–8638, 2018.
【NoisyNet】 Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Matteo Hessel, Ian Osband, Alex Graves, Volodymyr Mnih, R´emi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, and Shane Legg. Noisy networks for exploration. In Proceedings of the 6th International Conference on Learning Representations, 2018.
【SAC】Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, pp. 1856–1865, 2018.





