
主题: Multi-Agent Determinantal Q-Learning
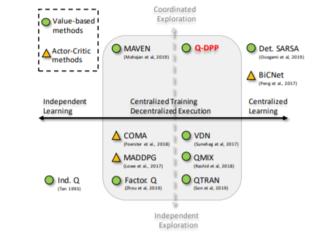
摘要: 具有分散执行力的集中训练已成为多主体学习中的重要范例。尽管可行,但是当前的方法依赖于限制性假设来分解跨执行主体的集中价值函数。在本文中,我们通过提出多智能体确定性Q学习来消除这种限制。我们的方法是基于Q-DPP,这是一种将确定性点过程(DPP)扩展到多智能体设置的新方法。 Q-DPP促进代理商获取多种行为模式;这允许对联合Q函数进行自然分解,而无需对值函数或特殊网络体系结构进行先验结构约束。我们证明Q-DPP在可分散合作任务上概括了包括VDN,QMIX和QTRAN在内的主要解决方案。为了有效地从Q-DPP提取样本,我们开发了具有理论近似保证的线性时间采样器。在训练过程中,我们的采样器还通过协调代理覆盖状态空间中的正交方向而受益于探索。我们在多个合作基准上评估我们的算法;与最新技术相比,我们算法的有效性得到了证明。
成为VIP会员查看完整内容
相关内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
27+阅读 · 2020年4月5日
Arxiv
8+阅读 · 2020年4月13日
Arxiv
4+阅读 · 2018年8月17日
相关主题
相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
131+阅读 · 2020年4月19日
专知会员服务
27+阅读 · 2020年4月5日
相关资讯
相关论文
Arxiv
8+阅读 · 2020年4月13日
Arxiv
4+阅读 · 2018年8月17日