【总结】强化学习需要批归一化(Batch Norm)吗?
深度强化学习实验室
深度强化学习算法 (DRL, Deep Reinforcement Learning Algorithm) 的神经网络是否需要使用批归一化 (BN, Batch Normalization) ?深度强化学习不需要批归一化,但是可以用归一化(长话短说)
1. BN在RL中是如何失效的?
在深度学习中BN很有用。特别是在监督学习中,我们从训练集中抽取数据进行训练,通过随机抽取保证每个批次的数据符合独立同分布 (i.i.d.)。在这种稳定的训练环境下,BN可以计算出一个变化稳定的 mean 和 std 用于归一化。
BN很有用,详见 Paper3 Batch normalization: Accelerating deep network training by reducing internal covariate shift. 2015. 这里还解释了BN如何起作用。
BN如何用,详见 从双层优化视角理解对抗网络GAN 的 3.2.3 批归一化BatchNorm 该怎么用?
在强化学习中,BN会失效,智能体 (agent) 训练越快,BN越难以发挥作用。与有监督训练不同,RL的智能体需要通过「经验回放」技术与环境交互来获取训练数据,这些数据不是一开始就准备好的。所以RL无法为BN提供足够稳定的训练数据,每当训练数据发生变化(智能体搜集到大量新的状态state),而BN来不及适应新的数据,造成估值函数和策略函数相继奔溃(表现为估值函数的估值不准,策略函数的策略退化)。
「经验回放」技术是什么?详见 DRL的经验回放(Experiment Replay Buffer) 用Numpy实现让它更快一点 的章节 1. 简单介绍「经验回放」

在有监督的深度学习中:
无论网络性能如何,我们一直都从训练集随机抽样得到稳定的训练数据(绿色箭头起点)
在训练数据稳定时,BN也会趋于稳定,并算出稳定的均值和方差(绿色箭头终点)
而在深度强化学习中:
训练数据由智能体与环境交互,从零开始收集,一开始就是不稳定的(橙色箭头起点)经过长时间采样,训练数据逐渐变多,从而趋于稳定(橙色箭头终点),BN也渐渐稳定,此时由于策略提升,智能体开始收集到新的状态,训练数据发生变化(红色箭头起点)受采样数据中新状态的影响,BN之前算出的均值与方差不适应新的数据,需要重新计算,因此它的值开始波动,可策略的性能在BN算出稳定的新值前,已经发生了明显的下降。策略性能下降,导致智能体与环境的交互受到影响,这加剧采样数据的不稳定,最终BN与采样数据双双滑落到不稳定的状态(红色箭头终点)。
循环以上过程 2~5
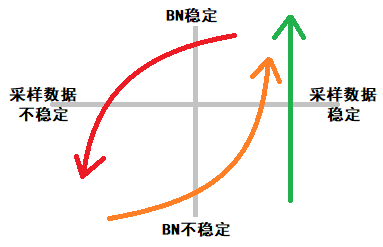
请注意,如果有的人复现的DRL算法非常差,采样效率低意味着采样数据稳定(成绩垫底,发挥稳定,有较大提升潜力),那么它用了BN反而能获得性能的提升。
传统的机器学习算法(比如写在 sk-learn里的那些),只要会超参数搜索技巧,大家得到的结果差不多
深度学习的一些算法,还可以在kaggle上举办比赛,尽管大家用的算法差不多,但是复现效果明显有优劣之分(比如自称YOLO5的算法,它的本质上还是YOLO4,但是它的确比YOLO4好)
强化学习的大部分算法,尤其是深度强化学习的算法,不同人类复现的效果有天壤之别。“这个环境我用DRL的XXX算法跑不出来啊”,能说出这句话的人,可能把DRL算法当成是sk-learn里面那些算法了。
若你在外看到有人宣称使用了BN让他的DRL算法训练更快了,可能是因为他实现的DRL算法差。例如,对于完全相同的某个任务(如Ant-v0):
好的DRL算法复现,平均训练0.5m步,加上BN,训练1m步,得出BN不适合RL的结论
差的DRL算法复现,平均训练10m步,加上BN,训练5m步,得出BN适合RL的结论
2. 尽管RL不需要批归一化BN,但是RL可以使用归一化
对训练数据使用归一化,即将输入神经网络的数值事先除以其均值和方差,让输入的张量符合标准正态分布,这是非常有用的技巧。强化学习也可以用,具体操作如下:
开始DRL的训练,然后将历史训练数据保存在经验回放 (relpay buffer) 里
训练结束后,计算 replay buffer 里 state 每个维度的均值和方差,结束整个训练流程
下一次训练开始前,对所有输入网络的state用固定的均值和方差进行归一化
重复一两次此过程
Critic一般以 state 和 action 作为输入,为何一般只对state做归一化而忽略 action?
在动作空间是连续的情况下,一个设计得好的环境,其 action 的均值方差最好接近0和1。要做到这点非常容易,例如我把动作空间设置为 -1到 1。
此外,一边训练一边计算归一化的均值与方差也是可行的(计算量稍大,我不推荐)与批归一化不同的是,这里的归一化使用的不是某一批次的数据,而是统计了历史出现的所有数据,因此它可以非常稳定。如下:
# https://github.com/zhangchuheng123/Reinforcement-Implementation/blob/master/code/ppo.py
# 详细过程去看他的代码
classRunningStat(object):
def mean(self):
def std(self):
class ZFilter:
def __call__(self, x, update=True):
x = x - self.rs.mean
x = x / (self.rs.std + 1e-8)
x = np.clip(x, -self.clip, self.clip)
return x3. 还认为RL应该用BN?Rllib他们都不用
知名的强化学习算法库:伯克利的Ray RLLIB、OpenAI的 baselines 等 都没有在他们的DRL算法中使用BN,这是有说服力的证据。
若看到这里还有人认为RL应该使用BN,那么可能只有把深度学习当成是实验科学,并用实验数据和代码才能说服他们了,代码见 ElegantRL (中文名可能叫“强化学习库:小雅?) ,里面有各种DRL算法以及标准的训练环境。想要通过实践去检验的人,可以随便挑一个算法,在你自己认为合适的地方加上BN层,如下:
self.net = nn.Sequential(nn.Linear(state_dim, mid_dim), nn.ReLU(),
nn.BatchNorm1d(mid_dim), # 随便挑一个地方加上BN层
nn.Linear(mid_dim, action_dim), nn.Tanh(), )实验数据见下方论文截图。
4. 列举出学界对BN in RL 的讨论并点评
反方 Paper1, Paper2 的观点与我相同,认为不需要:
正方 Paper3, Paper4 认为RL需要BN
Paper1 认为RL不能使用BN
CrossNorm: On Normalization for Off-Policy TD Reinforcement Learning. 2019.10 "Results improve only little over those without normalization and often are substantially worse."
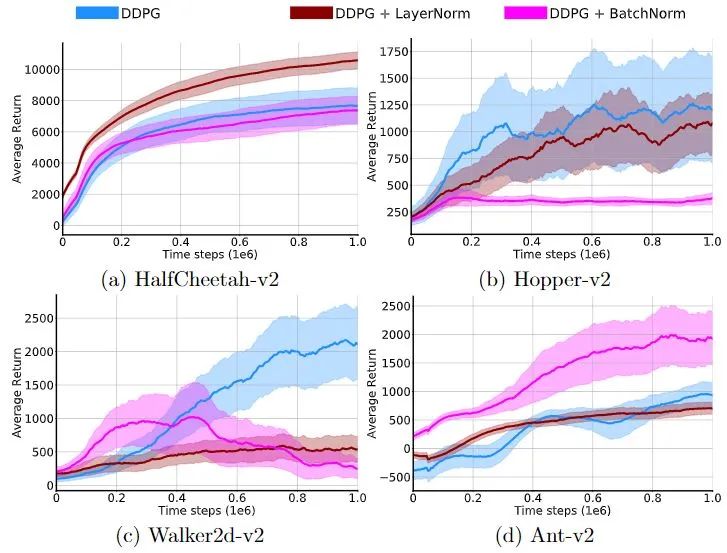
上面这篇文论发现在DRL 中使用BN 会带来很小的提升,但通常情况下甚至更差(训练更长久,且训练不稳定)。因此他们对BN 进行改进,提出了 CrossNorm。我在我的DRL 代码中尝试了BN,观测到的现象与他们描述的相符。此外,我尝试了他们的 CrossNorm 却没有得到显著的提升,我不推荐 CrossNorm。
Paper2 认为RL不需使用BN
Continuous control with deep reinforcement learning. ICLR. 2016 In Fig. 2, they compare "target network update" with "BN". the blue curve (with target network, not BN) is no significant difference between other methods with BN.
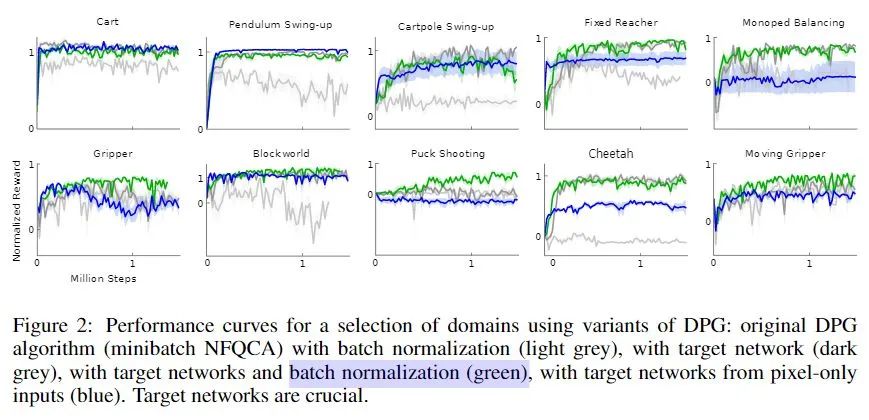
早在2016年,就有人讨论过 BN in RL 了,他们的结论也是:RL不需要使用BN,BN带来的性能提升微乎其微,远远不如 soft target update、(和后来的)Generalization Advantage Estimate 等技术。
Paper3 认为BN可以提升DL的训练
Batch normalization: Accelerating deep network training by reducing internal covariate shift. 2015. Cited by 17773 (till 2020-05-14)
在DQN提出用 Q network 取代 Q table,DDPG提出用 Actor Network 取代 DQN 的 贪婪策略 argmax 后,强化学习的无模型算法逐渐与深度学习进行结合。以至于知乎讨论的「强化学习」很大程度上是指「深度强化学习」(Deep RL)。
这篇文章只说:BN可以给深度网络带来提升,把它算成是正方已经很勉强。尽管深度强化学习也是一种深度学习,但是我个人认为深度强化学习中BN会失效。原因是深度强化学习(DRL) 不使用训练集进行训练,其训练数据没有深度学习那么稳定。详见本页面的「1. BN在RL中是如何失效的?」
Paper4 认为BN可以提升RL的训练
A Novel DDPG Method with Prioritized Experience Replay. IEEE SMC 2017. They cited Paper3 and claimed BN can improve DRL.
这篇文章在他们的DRL算法 DDPG中 尝试使用 BN,并认为用了更好(我反对此观点)。下面是我个人的吐槽:
为何在2017年出了A3C.2016 的情况下还要用 DDPG.2014?
若没有大厂背书(或是落地),没有开源代码的研究成果可视为不存在。
Paper3 说的是BN可以提升DL,而没有直接说BN可以提升DRL,不应该犯这种错误。
这篇文章发表在 IEEE SMC 2017. 还好不是讨论强化学习的地方,这篇文章能过侧面说明了当时这几个审稿人可能需要先入门深度强化学习。
这篇文章把DQN的 Prioritized Experience Replay 和 DDPG 结合起来,这是A+B式的科研,其创新程度不高,可以作为优秀的本科毕业设计,更不该成为可发表的论文。在标题上写 Novel DDPG 不恰当。
5. 列举出知乎对BN in RL 的讨论并点评
DDPG算法中actor的网络总是输出边界值怎么办?- @盛夏的果核 的回答 - 知乎
batch normalization+减少网络层+合理初始化参数+降低学习率+限制梯度幅值。
编辑于 2019-12-09
我不认同应该在DDPG中使用 BN。我认为很差的DDPG复现在使用了BN后,其性能可以提升。但是若正确复现了DDPG,就不会认为使用BN可以让DDPG正常训练。
我认同“减少网络层+合理初始化参数+降低学习率+限制梯度幅值”对提升DRL算法性能的建议,特别是“减少网络层”,但是这些建议和提问“DDPG算法中actor的网络总是输出边界值怎么办?”没有很强的关联。
这个问题相当于“我的电脑蓝屏了怎么办?”重启当然是有效的方法。
DDPG算法参数如何调节?- @Anonymous (叫这个名字 @不出来 )的回答 - 知乎
1、数据要归一化,至少要标准化,否则容易出现梯度爆炸的问题
2、使用批归一化层,keras中自带,位置放在激活函数层之前,防止输入全部处于tanh激活函数的饱和区间
3、reward中增加惩罚项,根据action的实际含义而定,惩罚过于复杂容易导致critic网络的loss不收敛
发布于 2019-09-01
我认同第一点,数据可以归一化。
我不认同第二点,BN不适合强化学习。而且“位置放在激活函数层之前”这是绝对错误的,详见从双层优化视角理解对抗网络GAN 的 3.2.3 批归一化BatchNorm 该怎么用? 批归一化不能放在激活层之前,这种结构在网络宽度不足的情况下容易丢失很多信息。
第三点不是恰当的建议,懂得如何正确地在“reward中增加惩罚项”的人,不需要问“DDPG算法参数如何调节?” 这种问题。
原文链接:
https://zhuanlan.zhihu.com/p/210761985?utm_source=wechat_session&utm_medium=social&utm_oi=734765378340671488&s_r=0
完
总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第81篇:【综述】多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第77篇:深度强化学习工程师/研究员面试指南
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)




