强化学习开篇:Q-Learning原理详解

导读:最近在对话系统的业务中研究了下结合强化学习的用法,特开此篇进行强化学习系列算法介绍。
目录
1.强化学习是什么
强化学习并不是某一种特定的算法,而是一类算法的统称,与有监督学习、无监督学习共称为机器学习的三大分支。针对强化学习最有名的应用应该是近几年的Alpha go,机器虚拟棋手首次战胜了棋界高手(下图即为对战截图)。
对于监督学习我们都不陌生,这种方法是在有标注数据的前提下可以高效的学习各类别对应的数据特征。而强化学习一开始并没有标注数据,它需要在对应环境中不断尝试进而获取相关数据和标签信息,然后根据学到的数据信息掌握可以带来高分的行为选择。
尤其是近年来深度学习技术的迅速发展,强化学习在学术界和工业界有了进一步地运用,比如让计算机学着玩游戏(王者荣耀人机对战有没有很熟悉,最近难度提升了不少~);再比如在对话系统中可以借助强化学习快速的针对对话状态做出行为反馈,无需人工维护。
2.Q-Learning是什么
现在回想一下我们小时候呱呱落地什么都不会,然后我们爸妈会耐心的教导我们,教我们做事读书,比如吃饭,第一次看到餐具和美味的饭菜我们根本不知道是要做什么,于是妈妈告诉你这是要吃饭啦,首先要洗手拿筷子,然后是夹菜;再比如看到卡车,第一次见到不知道是什么东西,于是妈妈又一次耐心的告诉你这是卡车,下次再见到你就知道这个东西原来是卡车。这种就是典型的监督学习,当我们做出一个动作,会立即得到反馈,而强化学习不是这样,当我们做出动作的时候,不会有立即的反馈,只有到结束的时候才能知道做这个行为的结果是啥。
比如我们小时候写作业的时候爸妈经常说“写不完作业就不能看电视”,这种写作业的状态下,如果你选择了继续写作业,爸妈发现后会表扬你(甚至给你点奖励),但如果你选择了撇下作业去看电视,爸妈发现后则会狠狠的惩罚你,通过这么一个写作业看电视受罚的经历,你知道了以后写不完作业就不能看电视这种决策思维,而Q-Learning则是这种决策思维的具象体现。
下面结合具体示例来讲解Q-Learning具体算法思维,并给出demo示例。
3.算法思维演示
此处依然以经典的“5号房间”来阐述Q-Learning的具体思想。
3.1 抽象建模
假设有这样的房间:
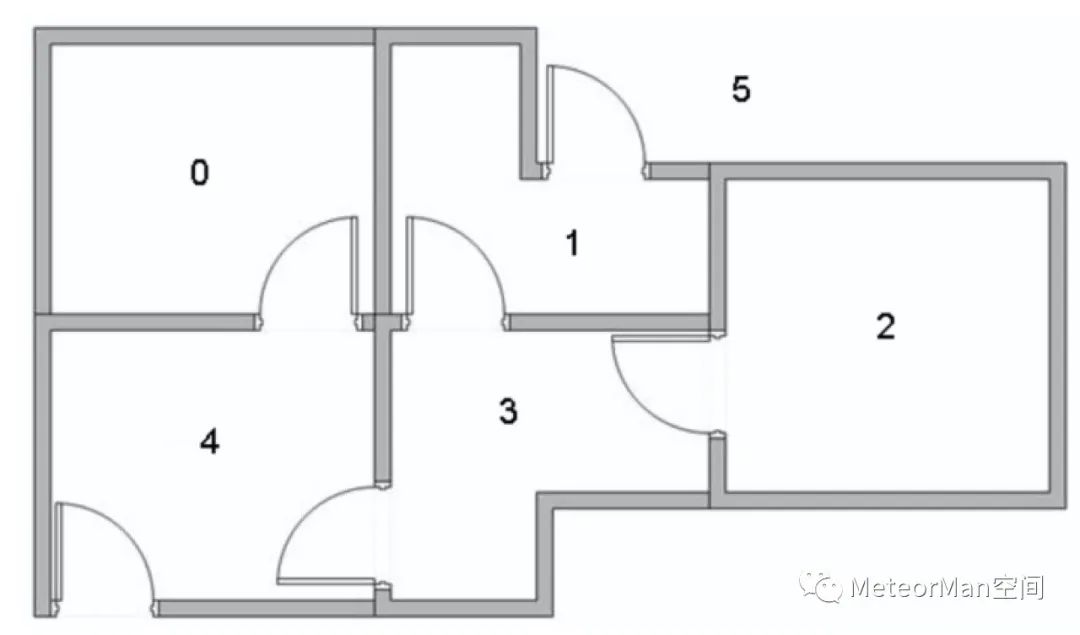
通过线条将其房间布局抽象为图节点表示:
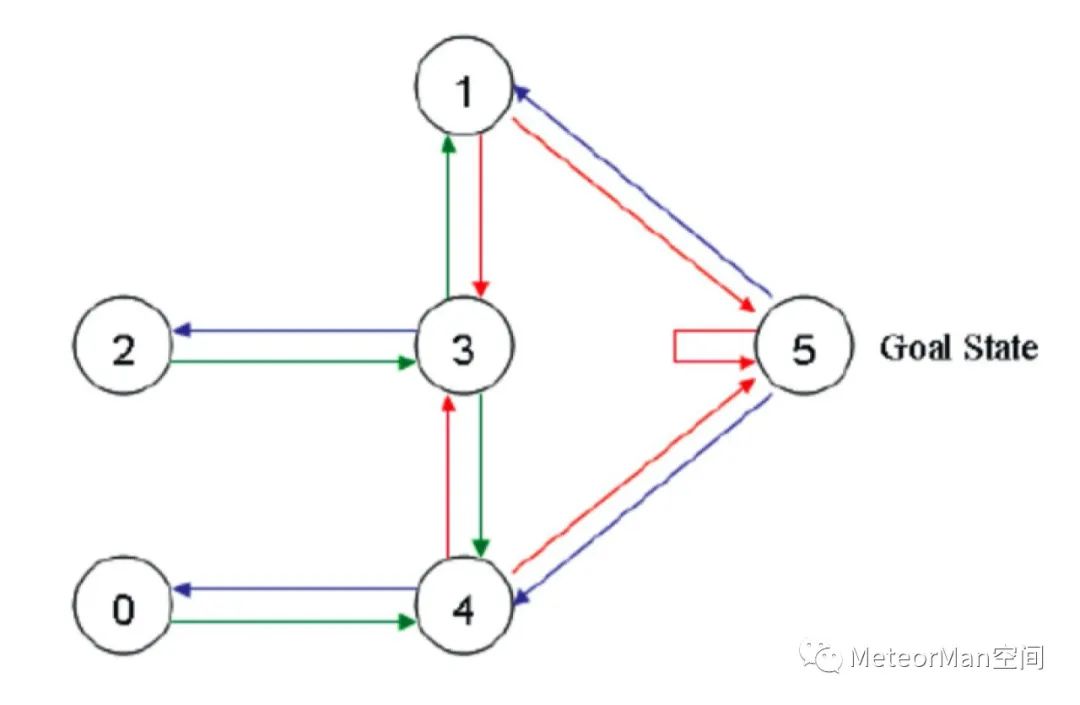
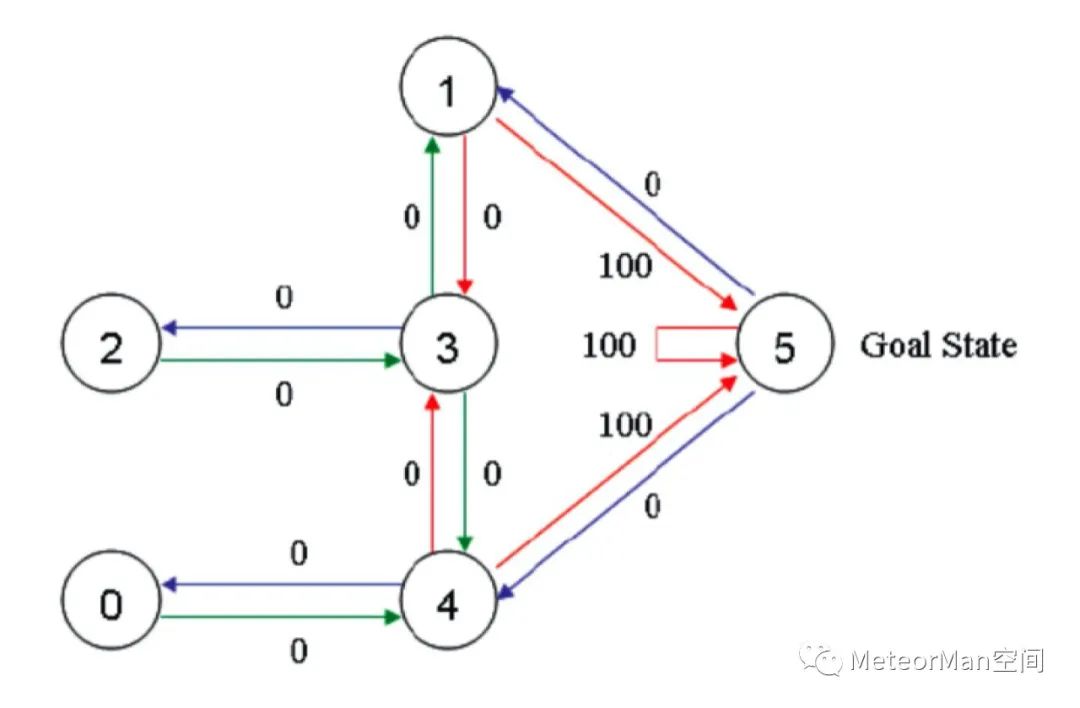
上图就是房间对应的布局图。首先呢将机器人(agent)随机的选择一个位置放下,让它自己随意走动,直至走到5号房间,表示成功。为了能够走出去,可以针对每个节点之间的连接边设置权重,将能够直接到达5号房间的边权重设为100,其余不能直接到达的边权重设置为0,依据这种机制上图可更新为:
在Q-Learning算法中,最重要的思维就是“状态”和“动作”这两个抽象表示,以上图为例,状态指的就是图中的哪个节点(可以是2节点,可以是5节点......),动作则指的是从一个节点到另一个节点的操作,如从1节点到3节点这一个操作就是一个动作行为。
紧接着我们指定一个奖赏矩阵R:
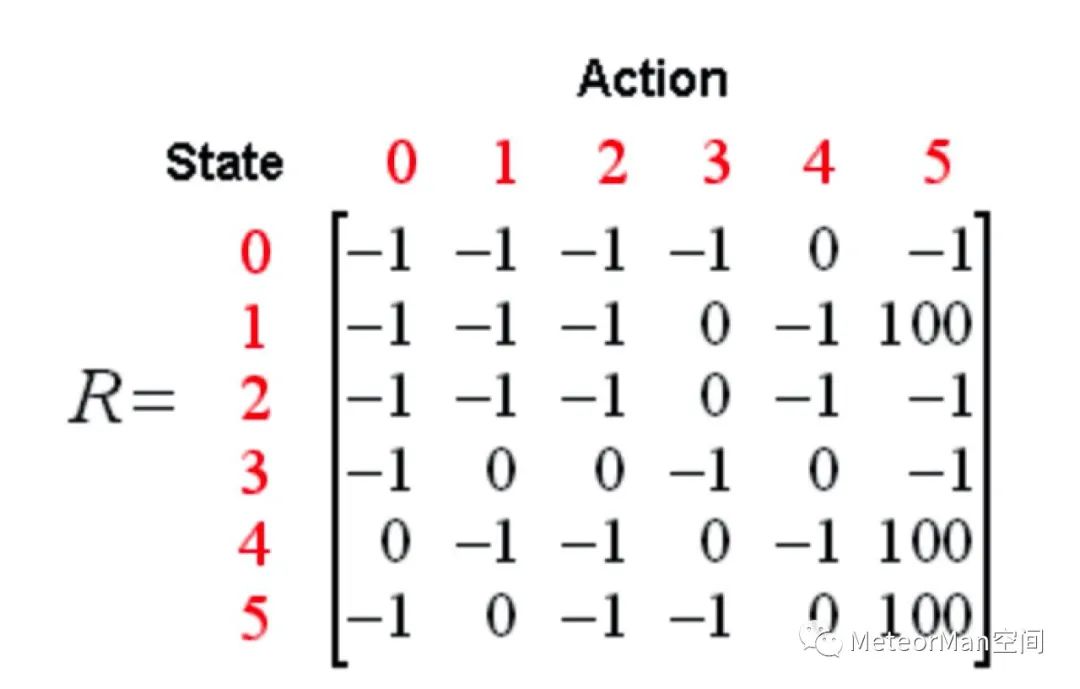
• 0表示可以通过;
• 100表示可以直接到达终点。
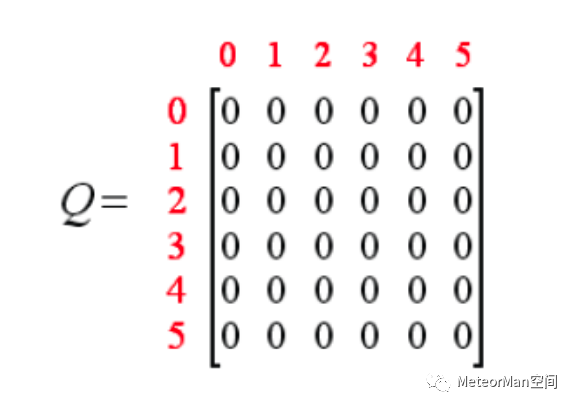
随后我们再创建一个Q表,表示学习的数据和标签信息,即经验矩阵,与R矩阵同阶,初始化为0矩阵。
最后我们给出Q-Learning的状态转移方程和伪代码框架。
状态转移方程:
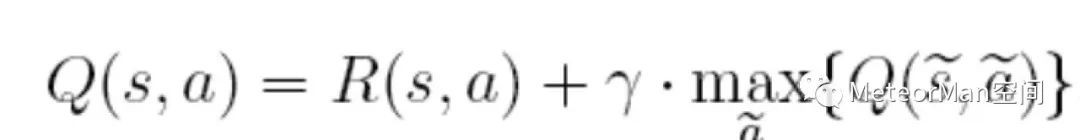
其中:
• s表示当前状态;
• a表示当前动作;
• s~表示下一个状态;
• a~表示下一个动作;
• γ为贪婪因子,0<γ<1,一般设置为0.8.
伪代码框架:

根据伪代码思维训练Q表,当Q学习完以后,就可以根据Q表来选择路径。
以上知悉之后,接下来将结合Q-Learning算法思维和示例讲解具体计算步骤。
3.2 Q-Learning决策矩阵Q训练
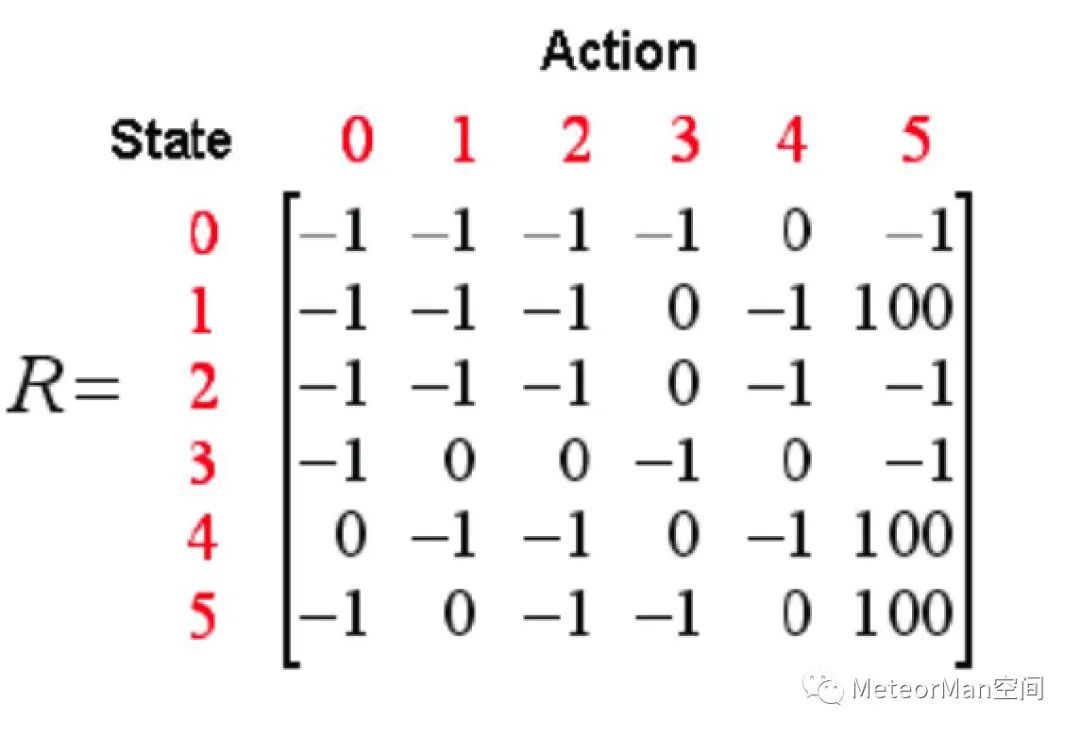
第一步 给定参数γ和reward矩阵R;
设定γ=0.8,R=
(1)随机选择一个状态,比如1;
(2)状态1不是目标状态,继续查看状态1所对应的的R表,找到可能的下一个行为(到达3和到达5),随机的选择到达5这个行为,根据状态转移方程计算Q(1,5):
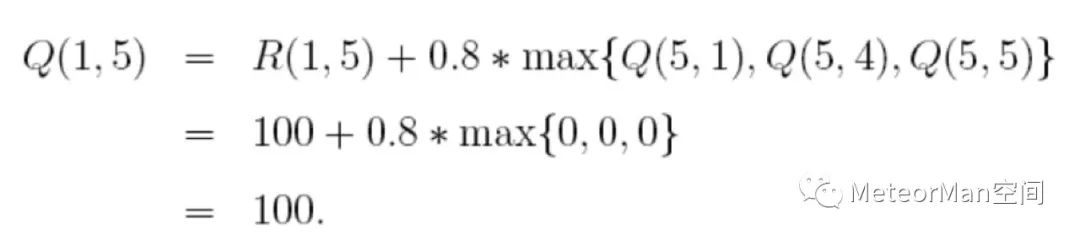
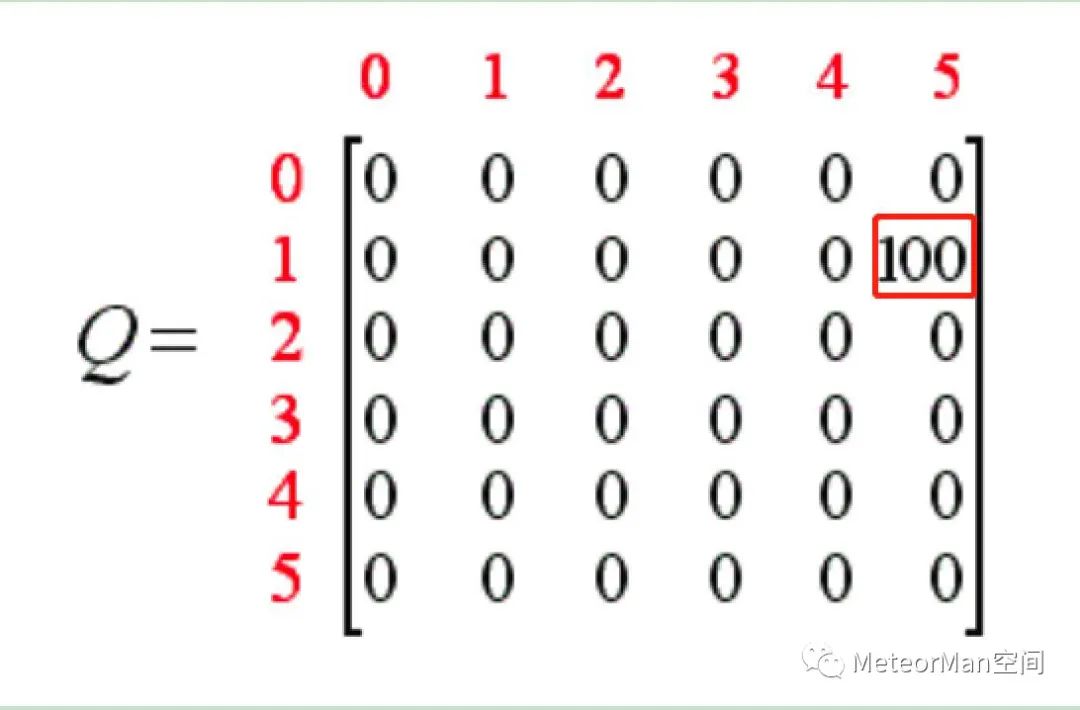
如此,到达目标,第一次尝试训练结束。
第三步 第二次迭代尝试训练
(1)随机选择一个状态,比如3;
(2)状态3不是目标状态,继续查看状态3所对应的的R表,找到可能的下一个行为(到达1、到达2以及到达4),随机的选择到达1这个行为,根据状态转移方程计算Q(3,1):
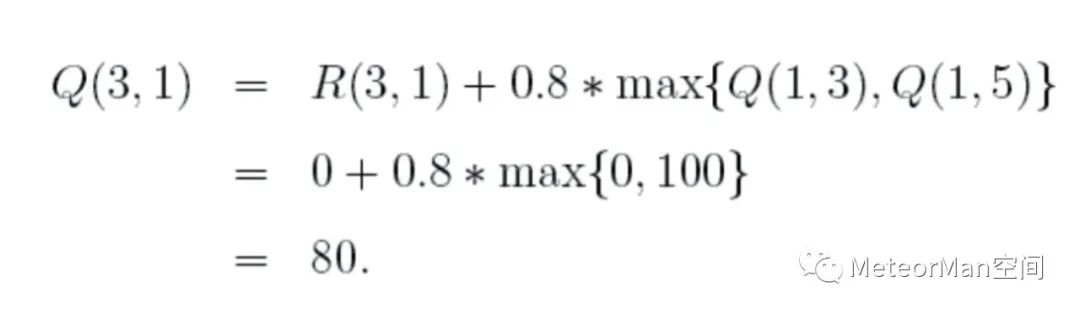
此时更新Q表:
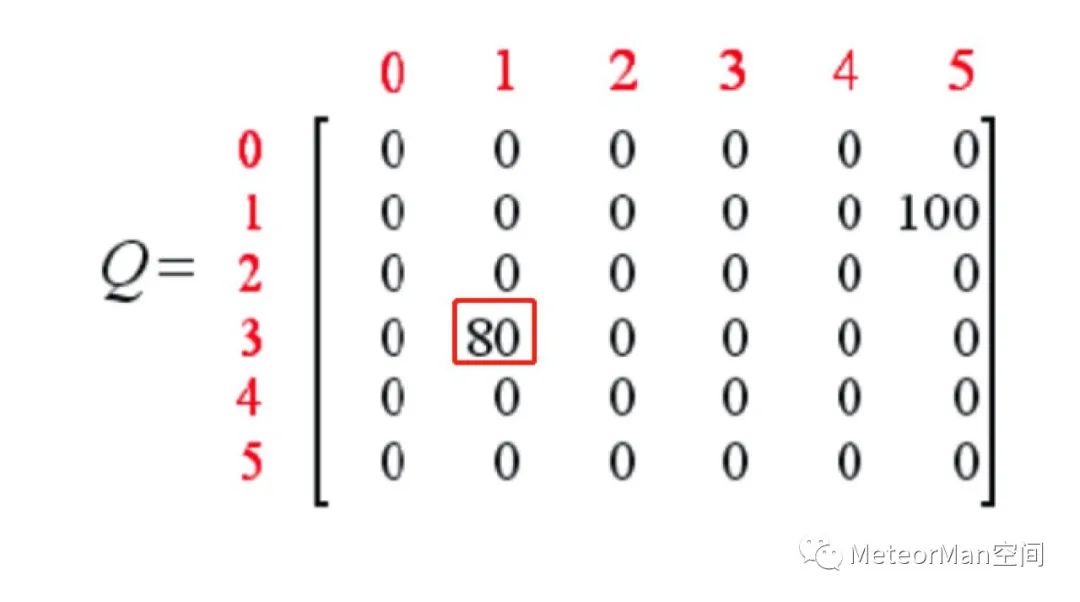
通过以上的训练方式不断迭代尝试训练即可得到一个训练好的Q表:

随后对其规范化,每个非零元素除以矩阵Q的最大元素值(此处为500),可得:

最终的Q表对应房间布局如如下所示:
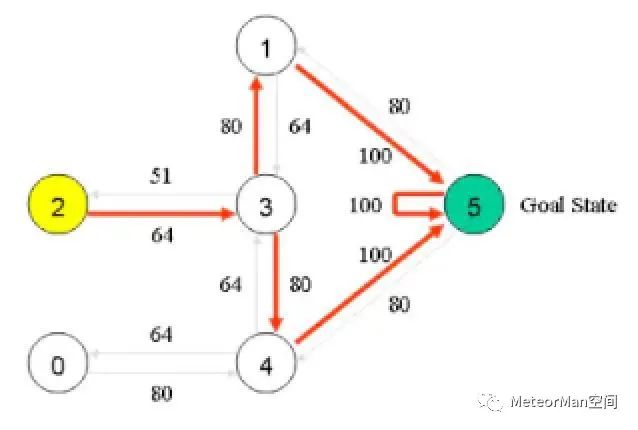
训练代码如下所示:
for i in range(1000):# 对每一个训练,随机选择一种状态state = random.randint(0, 5)while state != 5:# 选择r表中非负的值的动作r_pos_action = []for action in range(6):if r[state, action] >= 0:r_pos_action.append(action)next_state = r_pos_action[random.randint(0, len(r_pos_action) - 1)]q[state, next_state] = r[state, next_state] + gamma * q[next_state].max()state = next_state
3.3 Q-Learning选择算法
当Q表训练好之后,就可以根据Q表来进行路径选择。
选择算法如下:

对应代码如下:
state = random.randint(0, 5)print('机器人处于{}'.format(state))count = 0while state != 5:if count > 20: # 如果尝试次数大于20次,表示失败print('fail')break# 选择最大的q_maxq_max = q[state].max()q_max_action = []for action in range(6):if q[state, action] == q_max: # 选择可行的下一个动作q_max_action.append(action)# 随机选择一个可行的动作next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]print("the robot goes to " + str(next_state) + '.')state = next_state
输出效果:

若对该算法感兴趣,可去该处(https://github.com/Vincent131499/Reinforcement_Learning/tree/master/Q_Learning)获取完整代码。
参考资料:
[1]http://mnemstudio.org/path-finding-q-learning-tutorial.htm
[2]刘驰.深度强化学习-学术前沿与实战应用[M]
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




